改进的协同过滤推荐算法
1、推荐算法的发展随着互联网的快速增长,为了给用户提供更精准的服务,用户数据规模将大规模增长。而这些用户数据中包括用户个人信息,浏览记录、消费历史等数据,为了避免数据的大规模浪费,造成“信息过载”问题[1],推荐系统孕育而生。推荐系统于1990年被首次提到,而协同过滤于1992年被首次提出,随着推荐系统的不断发展,推荐系统与云计算、大数据相结合使用,随后在深度学习的热潮之下,2016年开始,推荐系
1、推荐算法的发展
- 随着互联网的快速增长,为了给用户提供更精准的服务,用户数据规模将大规模增长。而这些用户数据中包括用户个人信息,浏览记录、消费历史等数据,为了避免数据的大规模浪费,造成“信息过载”问题[1],推荐系统孕育而生。
- 推荐系统于1990年被首次提到,而协同过滤于1992年被首次提出,随着推荐系统的不断发展,推荐系统与云计算、大数据相结合使用,随后在深度学习的热潮之下,2016年开始,推荐系统与深度学习相结合来进行使用。
- 目前推荐系统已经成为许多电子商务和多媒体平台的内核,个性化推荐服务能够帮助平台吸引用户的注意力,提高用户访问量。推荐系统为网络平台的发展提供源源不断的动力,其商业价值也引起工业界和学术界的关注[1.1]。
- [1]黄立威, 江碧涛, 吕守业, 等. 基于深度学习的推荐系统研究综述. 计算机学报, 2018, 41(7): 1619–1647. [doi: 10.11897/SP.J.1016.2018.01619].
[1.1] 胡琪,朱定局,吴惠粦,巫丽红.智能推荐系统研究综述[J].计算机系统应用,2022,31(04):47-58.DOI:10.15888/j.cnki.csa.008403. - 推荐系统方法能够从海量数据中挖掘出隐藏价值信息,为用户提供个性化服务。让用户各取所需,避免用户在非感兴趣的数据中浪费大量时间,降低用户的体验满意度。推荐系统在缓解数据过载的问题中发挥着重要作用,能够协助用户发现潜在的兴趣[2],挖掘用户的历史行为数据、商品的多样化数据以及上下文场景信息,捕获用户潜在偏好,向用户生成更加精确的个性化推荐列表。
[2]Zhang S, Yao L, Sun AX, et al.Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys, 2019, 52(1): 5.
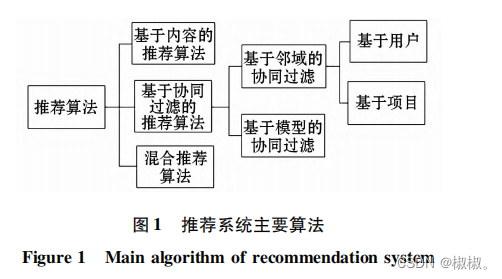
2推荐算法类别
- 已知的推荐算法根据评价对象不同可以分为四种,分别为基于协同过滤、基于内容、基于数据挖掘和混合推荐算法等[1.1]。
[1.1] 胡琪,朱定局,吴惠粦,巫丽红.智能推荐系统研究综述[J].计算机系统应用,2022,31(04):47-58.DOI:10.15888/j.cnki.csa.008403.

(1)基于协同过滤的推荐算法
- 目前的协同过滤的方法主要是两种类型:即用户层面与物品层面的两种办法。基于用户的协同过滤算法是推荐领域中比较经典的算法,主要包括:基于用户层面与物品层面两种【4.4】。基于用户的协同过滤推荐算法,首先要可以找寻到和目标用户相类似的用户的集合,然后依据该集合中用户偏爱的且目标用户之前没有使用过的商品进行推荐[36],推荐过程如图所示。
- 基于物品的协同过滤算法,通过去寻找和目标物存在着近似特质的项目,然后再邻接项目的评分数据的基础上来进行推荐[37]。推荐过程如图所示,从图中可以发现,根据多个用户的历史数据,如果喜欢商品1的用户会对商品3的喜好更有偏向,这样对于对于只喜欢商品1的用户,系统就会给他推荐商品3。
【4.4】徐超. 基于协同过滤的智能推荐商城系统的设计与实现[D].南昌大学,2021.DOI:10.27232/d.cnki.gnchu.2021.002264.
[36] 吴建帆,曾昭平,郑亮,李琥,管孜恒,徐寅.基于用户的协同过滤推荐算法研究[J].现代计算机,2020(19):27-29+67.
【37】王永贵,李倩玉.基于KNN-GBDT的混合协同过滤推荐算法[J/OL].计算机工程与应用:1-8[2021-02-07].


(2)基于内容的推荐算法
- 基于内容的推荐算法是源于信息检索这个定义,人工智能和机器学习技术在其中起到了举足若轻的作用,并且引入了概率统计这一概念,该算法中将每位使用中的要求当作是一个向量,然后通过技术向量之间的夹角来判断需要推荐的物品的相似程度[49]。
- 基于内容的推荐算法如图所示。在商城系统中,首先需要根据商品的属性信息构建各类商品的的属性库,这种属性库一般为用户评价情况。然后壮各类商品的属性值进行相似度计算,找出各类物品中最为相似的另一类物品,比如A商品与C商品相似度值最高,在进行商品推荐时,如果用户购买过a类商品,c类商品也会同时进行推荐。具体如图3.3所示:
[49] Bushra Alhijawi, Yousef Kilani. A collaborative filtering recommender system using genetic algorithm. 2020, 57(6)

- 在进行用户商品推荐的过程中,系统会根据用户对推荐的商品的反馈情况给予动态调整、不断完善。这类算法虽然计算简单、直观、高效,但是在动态调整计算的过程中可能会造成大量的计算冗余,随着商品和用户数据的大规模增加,系统的计算效率会逐渐降低,在一定程度上难以满足企业和用户的需求。同时,这种推荐算法总是基于历史数据来进行更新,难以发掘出用户的新兴趣点,新商品难以推荐。此外,也存在着一些内容属性比较复杂的情况让其不好处理,例如电影或者音乐类的信息属性[33]。
[33]蒲鲜霖.智能推荐系统中协同过滤算法综述[J].中国新通信,2018,20(23):31-32.
(3)混合推荐算法
-
基于不同的推荐算法有不同的特点,为了能够让推荐系统更快速,更高效的来迎合不同环境下的用户需求,因此,混合推荐这种方法也就应运而生了【徐超】。比较常见的混合方法包括:加权法、切换式、瀑布型和混合式等。
-
推荐算法优缺点对比:
评价对象为项目内容的推荐算法依据用户兴趣 和项目本身的内容进行推荐,不需要依赖其他数据,精度较高,但特征提取比较困难,在面对新项目、新用户时存在冷启动问题;根据项目和用户的交互信息进行推荐的协同过滤推荐算法有模型和邻域之分,其中基于近邻的又可以分为根据当前用户兴趣相似度推知未知用户兴趣的评分,即用户型和利用已知用户的浏览历史和项目属性的关联规则,生成推荐表格的项目型。混合推荐算法[3.3],为了取长补短,将多种推荐算法进行融合,实现更好的个性化推荐。
[3.3]古险峰,白林锋.深度学习框架下混合协同过滤算法研究[J].哈尔滨商业大学学报(自然科学版),2022,38(01):30-34.DOI:10.19492/j.cnki.1672-0946.2022.01.003.


3基于改进的协同过滤商品推荐算法
- 协同过滤[4]是早期使用最为广泛的推荐算法,核心思想是综合用户和项目显式反馈信息,筛选出目标用户可能感兴趣的项目进行推荐。协同过滤算法具备可解释性,能够发掘出用户新的兴趣点,但随着用户和物品的规模增大,共现矩阵数据会变得更加稀疏,计算相似度时准确率会降低,影响算法实际效果。且推荐结果的头部效应明显,评分高的受欢迎物品会多次推荐,而评分信息少的新物品较少推荐,算法泛化能力较差。
[4] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms. Proceedings of the 10th International Conference on World Wide Web. Hong Kong: ACM, 2001. 285–295.
- 基于以上的问题,本文提出了一种改进的协同过滤算法。在基于用户的协同过滤算法中,针对用户之间不存在交集的稀疏数据进行了算法优化,降低了时间计算复杂度,同时引入了热门物品惩罚来降低热门物品造成的推荐误差,并结合时间衰减函数来综合考虑由于时间对用户的影响情况。在基于物品的协同过滤算法中,考虑到热门商品造成的推荐偏差,在相似度计算是加入了热门商品惩罚计算;通知考虑到由于时间的间隔长短对于用户的兴趣影响情况,引入了时间衰减函数来进行算法优化。
3.1基于用户的改进协同过滤算法
- 在商城系统首页商品推荐页面,类似于“猜你喜欢”商品推荐,这部分主要使用基于用户的协同过滤算法来进行商品推荐。与传统的用户推荐算法相比,本文进行了改进。
该算法的具体步骤如下所示:
(1)根据用户对于商品的喜好程度评分,构建评分表,如表3.2所示:

(2)用户间相似度计算
用户相似度计算中主要是基于余弦公式来计算相似度计算,如公式 3.1 所示:

(3)算法复杂度的优化
-
在步骤2中的相似度计算过程中,是针对用户来进行计算的,每个用户对之间都需要进行计算,但是实际情况中,很多用户之间并不存在交集,为了降低计算的复杂度,避免系数用户对的冗余计算,对算法进行了如下优化:
a.先计算出分子不为0,N§∩N(q)≠0 的用户对(u,v)
b.将计算结果在进行相似度计算,获取p、q对相似度。 -
详细的优化过程:首先建立用户-商品倒排表T,代表物品和哪些用户之间有行为的产生。其中在T中,依据物品i,假设其对应的用户为j,k)。
-
然后依据表 T,构建相似度矩阵W(在W中,会对相应位置的元素进行更新,例如,W[j][k]=W[j][k]+1,W[k][j]=W[k][j]+1)。以此类比,在倒排表T被扫描之后,就可以得到一个完整的用户相似度矩阵W了,此处的W对照的是前面所述的余弦公式中的分子部分,然后用W除以分母,便可以最终得到两个用户的兴趣相似度了。我们同样以表 3.2 为例子,存在着四个用户,则需要一个4行4列的倒排表,如图3.3所示。

-
然后,基于以上的计算构建用户相似度矩阵,如图所示。

-
得到W后,依据余弦相似度计算公式进行计算,W值为公式3.1中的分子部分,计算公式如公式3.2所示。其中,表示用户对商品i的感兴趣程度,表示和用户p兴趣最接近的K个用户集,表示用户q对于商品i的感兴趣程度。

(4)热门商品的惩罚函数
- 在进行商品推荐时,对于热门商品的购买在很大程度上并不代表该用户的实际兴趣倾向,都购买热门商品的用户之间兴趣不一定相同,会存在很大的误区。基于此,我们在用户兴趣相似度计算中进行了优化,对商品进行了热门商品惩罚计算。计算如公式3.3所示。

该公式中分子部分,对用户对的热门商品进行了惩罚N(i)是对商品i有过行为的用户的集合,商品i的热门程度越高,则N(i)越大,最终用户对之间的相似度值越小。
(5)时间衰减函数的引入
-
在实际情况中,用户的兴趣程度会受时间的影响,随着时间的推移用户的兴趣会发生变化,一般我们将用户最近的行为情况作为最新的兴趣评价标准。其次,随着时间的推移,商品的流行度会发生不同程度的改变,会在一定程度上影响用户间的相似度计算。因此,推荐需要考虑实时性,通过引入时间损失函数来降低时间所造成的兴趣影响情况。在公式3.3的基础上进行了时间衰减f计算,如公式3.4和公式3.5所示。其中,代表用户p对商品i所造成的行为时间。

-
而同样的用户当前对物品的偏好程度受相似用户集合最近的偏好行为的影响较大,所以当我们计算用户p对商品 i的偏好程度时,也需要加上时间衰减函数,如公式 3.6 所示:

-
最后,需要根据用户对商品的偏好程度进行排序,根据排序的商品进行用户商品推荐。
3.2基于物品的改进协同过滤算法
- 在商品详情页的推荐模块中,我们使用基于物品的协同过滤推荐算法。主要是以商品为中心,基于不同用户对于物品的喜好程度来评价商品之间的相似度,在给用户推荐他喜欢的物品的相似商品。该算法的实现流程如下所示。
(1)根据不同用户对商品的评价情况构建用户-商品倒排表,同上文中基于用户推荐算法中的T倒排表的构建,其中A、B、C代表用户,a、b、c代表商品。构建如图所示。

(2)同现矩阵的构建,同现矩阵表示了同时喜欢两个物品的用户数,是根据上面
的用户-商品倒排表计算而得出的,如表所示:

(3)物品之间的相似度计算,这里采用以下公式3.7来进行计算。其中,分子代表同时喜欢商品i和j的用户数量,该公式代表了喜欢i商品的用户中喜欢j商品所占的比例。
在这里插入图片描述
(4)推荐结果的计算来计算用户p对物品i的兴趣程度,如公式3.8所示。其中,代表用户p感兴趣的商品集,代表用户p对商品j的感兴趣程度。代表与商品j最相似的K个商品集合。

(5)热门商品的惩罚
- 如果商品过于热门可能会导致大量用户对其有行为倾向,这会导致商品i与商品j之间的相似度偏差会很大。在进行商品i与商品j相似度计算时引入热门商品惩罚,改进如公式3.9所示。在分母部分进行乘积开方降低热门商品的权重。

(6)时间衰减函数的引入
- 同理,由于时间效益的影响,用户在较近时间内的行为最能反映用户的兴趣倾向,基于此时间间隔近的行为相对于时间间隔远的行为更可以反应物品之间的相似度,因此在商品相似度计算中加入时间衰减计算,计算如公式3.10和3.11所示。

而同样的用户当前行为应该和用户最近的行为关系最为密切,所以在最后的推荐结果计算时也要加入时间衰减计算,计算公式如公式3.12所示。

4本章小结
- 本章首先介绍了推荐算法的发展历程,然后介绍了几种比较常见的推荐算法,包括算法的基本思想和优缺点,随后详细介绍了本文提出的改进的基于协同过滤的商品推荐算法,包括基于用户的协同过滤算法和基于物品的协同过滤算法,本文将两种算法都进行了应用,同时还针对其中的热门物品推荐问题和系统的时间效应与实时性问题进行了改进与优化。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)