CRUD-CSI:数据库操作与存储接口设计指南
本文还有配套的精品资源,点击获取简介:CRUD-CSI可能指一个涉及数据库CRUD操作和特定存储接口的项目或库。CRUD操作是数据库管理的基础,包括创建、读取、更新和删除记录。项目可能提供一种简化这些操作的接口,允许开发者通过ORM框架或直接SQL语句与数据库交互。CSI可能指计算机科学接口或云存储接口,涉及应用程序与服务的交互规范。本项目的实现细节不明确,需要查看源代码...

简介:CRUD-CSI可能指一个涉及数据库CRUD操作和特定存储接口的项目或库。CRUD操作是数据库管理的基础,包括创建、读取、更新和删除记录。项目可能提供一种简化这些操作的接口,允许开发者通过ORM框架或直接SQL语句与数据库交互。CSI可能指计算机科学接口或云存储接口,涉及应用程序与服务的交互规范。本项目的实现细节不明确,需要查看源代码或文档以获取更深入的理解。 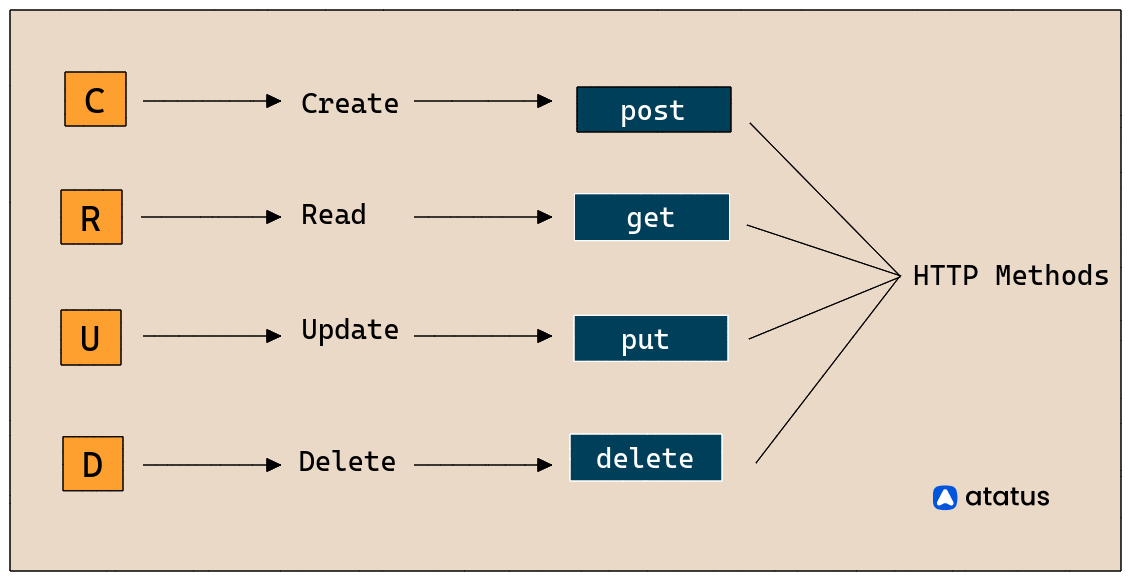
1. CRUD操作的介绍与实践
在当今的IT行业中,CRUD操作是数据库操作的基础,它代表着创建(Create)、读取(Read)、更新(Update)和删除(Delete)四个基本的数据处理动作。CRUD不仅为数据库的日常管理提供了必要的操作接口,而且对于任何需要持久化存储数据的应用来说,掌握CRUD操作是不可或缺的基础。
1.1 CRUD操作的含义及其重要性
CRUD操作是数据持久层的基石,无论是开发Web应用还是构建复杂的分布式系统,都离不开对数据的增删改查。理解并精通CRUD操作,可以帮助开发者更高效地管理数据库资源,优化数据访问路径,进而提升整个系统的性能和用户体验。
1.2 CRUD在不同编程语言和数据库中的实现
不同的编程语言和数据库系统提供了各自的方式来实现CRUD操作。例如,使用SQL语言的MySQL数据库、使用MongoDB的NoSQL数据库,或者在Java中使用JDBC,以及在Python中通过ORM框架操作SQLite数据库。通过展示多种语言和数据库系统中CRUD操作的实例,我们能够更直观地理解其在不同环境下的应用差异。
-- 一个简单的SQL语句来演示CRUD操作
-- 创建数据表
CREATE TABLE IF NOT EXISTS user (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100)
);
-- 插入新记录
INSERT INTO user (name, email) VALUES ('John Doe', '***');
-- 查询记录
SELECT * FROM user;
-- 更新记录
UPDATE user SET email = 'john.***' WHERE id = 1;
-- 删除记录
DELETE FROM user WHERE id = 1;
在下一章,我们将深入讨论ORM(对象关系映射)框架,这是一种流行的抽象化数据库操作的方法,它允许开发者用面向对象的方式来操作数据库,而无需直接写入SQL代码。
2. ORM框架的应用
2.1 ORM框架基础
2.1.1 ORM的概念和优势
对象关系映射(Object-Relational Mapping,简称ORM)是一种技术,用于在关系数据库和对象之间进行转换。这种模式主要解决数据库和面向对象编程之间的不匹配问题,它将数据库的表映射为代码中的类,并且将表中的行映射为类的实例(对象)。使用ORM框架可以更加直观地进行数据库操作,并且能够简化编程模型,让开发者聚焦于业务逻辑而不是底层SQL语句。
ORM的优势主要体现在以下几个方面:
- 代码简化 :ORM将数据库操作抽象成简单的对象操作,减少了代码的复杂度。
- 开发效率提升 :使用ORM框架可以快速搭建应用程序的数据访问层,极大地提升了开发效率。
- 可维护性增强 :代码更加贴近业务逻辑,易于理解和维护。
- 数据类型安全 :ORM能够确保数据类型的安全性,减少类型错误导致的问题。
- 数据库无关性 :开发者可以编写通用的代码,不同的数据库可以通过更换适配器来实现无缝切换。
2.1.2 常见ORM框架对比
市场上存在多种ORM框架,包括但不限于Hibernate(Java)、Entity Framework(.NET)、Active Record(Ruby)、Django ORM(Python)等。在选择ORM框架时,需要考虑以下几个因素:
- 性能 :不同的ORM框架对数据库操作的性能有所不同。
- 社区与文档 :活跃的社区和完善的文档可以帮助开发者更快地解决问题。
- 兼容性 :框架需要兼容所使用编程语言和数据库的版本。
- 扩展性 :框架是否支持自定义扩展,以满足特定场景的需要。
以Java领域的Hibernate和.NET领域的Entity Framework为例,Hibernate是一个成熟的ORM解决方案,拥有广泛的社区支持,适合企业级应用的开发。Entity Framework则从.NET框架诞生之初就内置了支持,对于.NET开发者来说非常友好,且近年来的Core版本性能有了极大的提升。
2.2 ORM在数据库操作中的实践
2.2.1 基本CRUD操作的ORM实现
基本的CRUD操作是数据库操作中最常见的四种操作,包括创建(Create)、读取(Read)、更新(Update)和删除(Delete)。以下是一个使用Java Hibernate框架实现的简单CRUD示例:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
// 创建操作
User user = new User("John Doe", "john.***");
session.save(user);
// 读取操作
User retrievedUser = (User) session.get(User.class, user.getId());
// 更新操作
retrievedUser.setEmail("john.***");
session.update(retrievedUser);
// 删除操作
session.delete(retrievedUser);
***mit();
session.close();
在这个例子中,我们通过Session对象来管理数据库操作。Session是应用程序和持久化存储层之间的一个单线程对象,代表一次与数据库的交互。Transaction用于事务管理,确保所有的更改要么全部成功,要么全部回滚。
2.2.2 高级查询与事务管理
ORM框架通常提供丰富的API来执行复杂的查询。以Hibernate为例,可以使用HQL(Hibernate Query Language)来进行查询操作,也可以使用Criteria API来构建类型安全的查询。以下是一个使用HQL的查询示例:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
// HQL查询
Query query = session.createQuery("from User where email = :email");
query.setParameter("email", "john.***");
User user = (User) query.uniqueResult();
// 事务管理
***mit();
session.close();
事务管理确保了数据的一致性,通过BEGIN, COMMIT和ROLLBACK等操作来控制事务的边界。Hibernate也支持声明式事务管理,可以在配置文件中指定哪些方法需要事务管理。
2.2.3 ORM与数据库性能优化
ORM虽然方便,但如果使用不当,可能会对性能产生负面影响。为了优化数据库性能,开发者需要关注以下几点:
- 懒加载 :使用懒加载来延迟加载关联对象,减少不必要的数据加载。
- 批处理 :批量处理可以减少数据库交互次数,提高性能。
- 缓存 :合理的使用一级缓存和二级缓存能够减少对数据库的查询次数。
- 索引 :合理地创建索引可以提高查询效率。
ORM框架提供的缓存机制可以减少对数据库的直接查询,但同时也需要开发者合理控制缓存大小和生命周期,避免内存溢出等问题。
2.3 ORM框架的高级特性与技巧
2.3.1 关联映射与懒加载
在面向对象的程序设计中,对象之间的关系映射是常见的需求。ORM框架允许开发者以声明的方式定义这些关系,常见的关系包括一对一、一对多和多对多。
懒加载是ORM框架中一个重要的性能优化技巧,它允许ORM在需要时才加载关联的实体。这可以避免一次加载过多的数据,从而提高性能。但开发者需要注意懒加载可能导致的N+1查询问题,这在处理大量数据时可能会引起性能瓶颈。
2.3.2 面向对象与数据库设计的协同
在使用ORM框架时,要让面向对象的设计与数据库设计之间能够更好地协同工作。例如,表的继承关系可以在ORM中映射为继承的类结构。此外,表的联合查询(Joins)在ORM中可以对应为对象的关联引用。
正确的模型映射能够使代码更加清晰,但需要考虑数据库的设计约束,比如外键的使用,以及如何在ORM中处理好一对一和一对多的关系映射。
2.3.3 ORM安全性的考量与实现
安全性是应用开发中不可忽视的问题。在使用ORM框架时,需要确保所有数据库操作都符合安全规范,比如防止SQL注入攻击。使用ORM框架时,开发者通常不需要直接编写SQL语句,这在一定程度上降低了SQL注入的风险,但仍需小心防范。
此外,还需要注意ORM框架中动态生成的SQL语句,确保它们的生成符合预期,避免暴露敏感信息。使用框架提供的安全性特性,如参数化查询和事务管理,来进一步提高应用的安全性。
3. 计算机科学接口概念
3.1 接口的定义与重要性
3.1.1 接口的基本概念
在计算机科学中,接口(Interface)是一个非常核心的概念,它定义了一系列方法的集合,这些方法由实现该接口的类来具体实现。接口可以被视为一组规范或契约,确保了不同组件或系统间能够以一致的方式进行通信和交互。
接口通常用来定义一个类或者模块必须实现的方法,而不必关心具体如何实现这些方法。这种设计使得软件组件具有更好的解耦性,提高了代码的复用性和系统的可维护性。接口是面向对象编程(OOP)中多态性的基础,允许不同的类以相同的方式处理请求。
3.1.2 接口与抽象类的区别
尽管接口和抽象类在某些方面看起来非常相似,它们都用于实现多态,但它们在设计上和使用上有着本质的区别:
- 实现方式: 接口在Java等语言中通常是通过关键字
interface声明,类通过implements关键字实现接口;而抽象类在Java中是通过abstract关键字声明,类通过extends关键字来继承抽象类。 - 组成成员: 接口通常只包含方法声明(Java 8以后可以包含默认实现和静态方法),而抽象类可以包含方法声明、具体方法和属性。
- 继承与实现: 一个类可以实现多个接口,但只能继承一个抽象类。这提供了更灵活的扩展方式。
- 目的差异: 接口更倾向于定义一个公共的协议,强调“可以做什么”;抽象类更侧重于定义一个基础的共性结构,强调“是什么”。
3.2 接口在软件工程中的应用
3.2.1 接口的封装与分离关注点
在软件工程中,接口的一个关键作用是封装和分离关注点。它允许开发者在不修改现有代码的基础上,通过引入新的接口来扩展系统的功能,这种做法符合开闭原则(Open/Closed Principle),即软件实体应当对扩展开放,对修改关闭。
- 解耦: 通过接口定义,不同模块之间通过抽象的协议进行通信,这样可以降低模块间的耦合度,使得各个模块能够独立地开发、测试和维护。
- 灵活性: 使用接口可以提供更好的灵活性,因为当接口的实现发生变化时,依赖于该接口的其他模块可以不用做任何改动。
3.2.2 接口版本控制与兼容性问题
随着软件的迭代更新,接口版本控制变得尤为重要。它涉及到如何保证旧版本接口的稳定性,同时允许新版本接口的扩展。
- 向后兼容性: 在进行接口升级时,需要确保新的接口实现仍然能够与旧版本的接口调用者兼容,除非是故意为了引入破坏性更改。
- 版本命名: 常见的做法是通过接口URL或方法名中包含版本号来标识接口的不同版本,如
/api/v1/users和/api/v2/users。
3.3 接口设计的原则与模式
3.3.1 SOLID原则与接口设计
接口设计应该遵循SOLID原则,这是一个面向对象设计的五个基本原则,帮助软件设计师创建易于维护和扩展的系统。
- 单一职责原则(Single Responsibility Principle): 一个接口应该只有一个被修改的原因。
- 开闭原则(Open/Closed Principle): 类、模块、函数等应该对扩展开放,对修改关闭。
- 里氏替换原则(Liskov Substitution Principle): 对象在程序中应该被其子类的实例替换,而不会影响程序的正确性。
- 接口隔离原则(Interface Segregation Principle): 不应该强迫客户依赖于它们不用的方法。
- 依赖倒置原则(Dependency Inversion Principle): 高层模块不应该依赖于低层模块,两者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
3.3.2 常见的设计模式在接口中的应用
设计模式是软件设计中常见问题的通用解决方案。接口设计经常与这些模式结合,以提高代码的灵活性和可维护性。
- 工厂模式(Factory Pattern): 使用接口定义一个创建对象的工厂方法,而具体创建哪个对象由实现该接口的子类来决定。
- 策略模式(Strategy Pattern): 定义一系列的算法,把它们一个个封装起来,并使它们可以相互替换。接口在这里定义了算法必须实现的方法。
- 观察者模式(Observer Pattern): 对象间的一对多依赖关系,当一个对象改变状态时,所有依赖者都会收到通知。接口在这里定义了通知的协议。
结语
在这一章中,我们详细探讨了接口的概念、重要性以及在软件工程中的应用。我们了解到接口是构建灵活、可维护和可扩展的软件系统的基础。通过遵循SOLID原则和应用常见的设计模式,接口能够有效地解决软件设计中的问题,同时保证系统的稳定性和一致性。随着我们继续深入学习,我们会发现接口在软件架构和设计模式中扮演着至关重要的角色。
4. 云存储接口的介绍
4.1 云存储接口概念
4.1.1 云存储基础和应用场景
云存储是一种通过互联网提供的数据存储服务,它允许用户在远程服务器上存储数据,而无需本地物理存储。这种服务是基于云计算架构的,它提供的存储空间可以是按需分配,费用通常基于实际使用的容量计算,这一特点使得云存储在各种规模的企业和个人用户中都非常受欢迎。
在现代应用中,云存储被广泛应用于以下几个场景:
- 数据备份与恢复 :云存储作为备份解决方案,可以为公司提供额外的安全层,确保关键数据的持久化和恢复能力。
- 文件共享与协作 :团队成员可以借助云存储实现高效协作,共享文档、视频和其他重要文件。
- 内容分发网络(CDN) :将内容缓存至世界各地的服务器,以实现快速的内容分发。
- 大规模数据分析 :云存储可以存储和处理大数据分析所需的数据量,为企业决策提供支持。
4.1.2 云存储接口的作用与优势
云存储接口为应用程序提供了一种与云存储服务进行交互的标准方法。它允许应用程序以编程方式上传、下载、管理文件,以及执行其他存储操作。以下是云存储接口的几个关键作用:
- 抽象存储细节 :云存储接口隐藏了底层存储架构的复杂性,使得开发者可以专注于应用逻辑,而无需深入了解存储设备和网络。
- 兼容性和互操作性 :通过统一的接口,应用程序可以与多种云存储服务提供商交互,从而提高了应用的兼容性和可移植性。
- 可扩展性和弹性 :云存储接口通常设计为支持水平扩展,使得服务能够应对不断变化的工作负载。
云存储接口的优势主要体现在以下几个方面:
- 成本效益 :用户不需要投资昂贵的存储硬件,云存储按需计费模式可以降低存储成本。
- 可扩展性 :根据业务需求的变化,用户可以轻松地增加或减少存储资源。
- 高可用性 :通过云服务提供商的冗余存储和自动故障转移机制,确保了数据的高可用性。
- 安全性 :成熟的云存储服务提供多种安全机制来保护用户数据,如数据加密、访问控制等。
4.2 云存储接口的技术实现
4.2.1 RESTful API设计原则
RESTful API是目前最流行的接口设计方式之一,它基于HTTP协议,提供了一种简单、灵活的方式来实现云存储接口。RESTful API的设计原则包括:
- 资源的表达 :每个资源都应该是唯一的,并通过URL来访问。
- 无状态的交互 :客户端请求应该包含处理请求所需的所有信息,服务器端不需要保存任何客户端状态。
- 使用HTTP方法 :使用标准的HTTP方法如GET、POST、PUT、DELETE等来表示不同的操作。
- 统一的接口 :客户端不需要知道每个API的具体实现,只需要了解资源的URL和HTTP方法。
例如,一个简单的RESTful API设计可能如下:
- 获取文件列表 :
GET /files - 上传文件 :
POST /files - 下载文件 :
GET /files/{filename} - 删除文件 :
DELETE /files/{filename}
4.2.2 云存储接口的认证与授权机制
安全是云存储接口设计中不可或缺的一部分。认证和授权机制用于确保只有合法的用户可以访问数据。常用的机制包括:
- 基于令牌的认证 (如OAuth):客户端在访问接口之前必须获得一个令牌,并在请求中包含该令牌。
- 基于角色的访问控制 (RBAC):定义不同的角色,并为每个角色分配访问资源的权限。
- API密钥 :为每个访问者提供一个API密钥,用于识别和跟踪API调用。
- SAS(Shared Access Signature)令牌 :一种用于访问Azure Blob存储等服务的安全令牌,通过URL参数提供安全访问。
下面是一个使用OAuth令牌认证的RESTful API请求示例:
GET /files HTTP/1.1
Host: ***
Authorization: Bearer YOUR_OAUTH_TOKEN
在上述请求中,客户端需要在HTTP请求头中添加一个 Authorization 字段,并提供有效的OAuth令牌。
4.3 云存储接口的实际应用案例
4.3.1 文件上传与下载接口的实现
实现文件上传和下载接口时,通常会使用HTTP的POST和GET方法。一个基本的文件上传流程包括:
- 客户端向服务器发送包含文件数据的POST请求。
- 服务器接收文件数据,并保存到指定的存储位置。
- 服务器返回操作结果给客户端,确认上传成功或提供错误信息。
实现文件上传的伪代码如下:
import requests
files = {'file': open('example.txt', 'rb')}
response = requests.post('***', files=files)
if response.status_code == 200:
print("File uploaded successfully.")
else:
print("Error in uploading file.")
文件下载接口通常提供一个GET请求,允许客户端通过URL下载文件。例如:
GET /files/example.txt HTTP/1.1
Host: ***
Authorization: Bearer YOUR_OAUTH_TOKEN
实现文件下载的伪代码如下:
import requests
response = requests.get('***', headers={'Authorization': 'Bearer YOUR_OAUTH_TOKEN'})
if response.status_code == 200:
with open('example.txt', 'wb') as f:
f.write(response.content)
else:
print("Error in downloading file.")
4.3.2 数据同步与备份接口的策略
数据同步和备份是云存储服务的另一项重要功能。为了实现数据的可靠备份和同步,通常需要使用一些策略,例如:
- 版本控制 :跟踪文件的每个版本,允许用户随时回滚到特定的时间点。
- 增量备份 :只备份自上次备份后发生变化的数据,以节省时间和带宽。
- 压缩和加密 :在传输和存储数据时进行压缩和加密,以减少存储空间需求并保证数据安全。
以下是使用RESTful API进行数据备份的策略示例:
POST /backup HTTP/1.1
Host: ***
Authorization: Bearer YOUR_OAUTH_TOKEN
Content-Type: application/json
{
"source_path": "/data",
"destination_path": "/backup",
"incremental": true,
"encrypted": true
}
该请求将触发一个增量备份过程,备份数据将被压缩并加密,保存至指定的目的路径。
通过上述实例,我们可以看到云存储接口在实际应用中的强大功能和灵活性,能够满足多样化的业务需求。而这些功能的实现,都离不开对RESTful API设计原则的遵循以及对安全认证与授权机制的严格把控。
5. 代码版本控制与协作的最佳实践
5.1 版本控制系统的演变与选择
5.1.1 版本控制系统的起源
版本控制系统是软件开发中不可或缺的工具,它可以帮助开发者跟踪和管理源代码的变更历史。最初,版本控制主要是为了跟踪文件的更改和历史版本,随着时间的推移,它进化成为支持协作开发的复杂系统。从最简单的本地版本控制系统,如RCS(Revision Control System),到集中式版本控制系统,如CVS和Subversion(SVN),再到如今广泛采用的分布式版本控制系统,如Git,每一步的演进都是对开发需求的响应。
5.1.2 分布式与集中式版本控制系统的比较
集中式版本控制系统(CVCS)的特点是拥有一个中央服务器,所有代码的变更历史都存储在此服务器上,团队成员需要与这个中央服务器进行交互来获取最新的代码和提交自己的更改。相比之下,分布式版本控制系统(DVCS),如Git,没有中央服务器的概念,每个开发者都拥有完整的代码库副本,包括完整的变更历史。这使得代码的同步和分支操作更加高效和灵活。
5.1.3 Git与其他版本控制系统的对比
Git之所以能够在短短几年内成为业界标准,主要因为它在速度、数据完整性和分布式协作方面有着明显的优势。Git使用了哈希函数来存储数据,确保了数据的不变性,而其分支操作由于克隆了整个仓库,因此几乎没有任何性能损耗。在协作模式上,Git的pull request和fork机制为开源项目的协作贡献提供了极大的便利。尽管Git目前是版本控制的霸主,但一些项目由于其特殊需求可能仍会使用SVN等传统工具。
5.2 代码分支管理策略
5.2.1 分支策略的作用
在现代软件开发中,分支是版本控制的基础。合理的分支策略能够帮助团队管理不同阶段的开发工作,分离特性开发、修复工作与生产环境代码。分支策略有助于减少冲突,加快发布速度,以及提高代码质量。
5.2.2 Git Flow与GitHub Flow
最流行的分支模型之一是Vincent Driessen提出的Git Flow,它定义了一个围绕项目发布周期的严格分支模型,包括主分支(master)、开发分支(develop)以及特性分支、热修复分支、发布分支等。而GitHub提出的GitHub Flow则更为简洁,主张使用单一的长期分支(通常是master),以及基于它的特性分支进行开发和管理。
5.2.3 分支命名与保护规则
为了维护代码库的清晰性和稳定性,明确分支命名规则至关重要。分支名称应该清晰地传达其目的,比如特性分支可以命名为feature/branch-name,修复分支可以命名为hotfix/bug-name等。此外,一些代码仓库允许设置分支保护规则,以避免直接在主分支上进行更改,从而保障生产环境代码的稳定性。
5.3 提高代码质量的实践
5.3.1 代码审查的重要性
代码审查是提升代码质量的重要手段。通过代码审查,团队成员不仅可以互相学习,还可以提早发现潜在的问题和缺陷,提高项目的整体质量。代码审查还有助于保持团队编码风格的一致性,减少将来维护工作的难度。
5.3.2 自动化测试与持续集成
自动化测试是确保软件质量的关键步骤,它能够以可重复的方式对软件进行持续的质量检查。而持续集成(CI)则是将自动化测试与代码提交流程相结合,确保每次代码提交都能够快速集成并运行测试,从而快速发现问题并减少集成问题。
5.3.3 代码度量与重构
为了维护代码库的长期健康,定期进行代码度量和重构是必要的。通过度量工具,我们可以获取代码复杂度、重复度等关键指标,从而为重构决策提供数据支持。重构不仅涉及重写代码,还包括改进设计模式和架构,以适应新的需求和挑战。
flowchart LR
A[代码提交] -->|触发CI| B[自动化测试]
B -->|成功| C[代码部署]
B -->|失败| D[通知开发人员]
C -->|监控应用| E[收集反馈]
E -->|存在问题| D
E -->|运行正常| F[回归测试]
F -->|问题| D
F -->|无问题| G[下一次提交]
5.4 代码库协作工具与实践
5.4.1 协作工具的多样性
协作工具是帮助团队成员有效沟通与协作的软件,它包括项目管理工具、即时通讯工具和文档协作工具等。这些工具能够帮助团队更好地组织工作,比如使用JIRA进行任务管理、Slack进行即时通讯、Confluence进行文档共享等。
5.4.2 提交信息规范与代码共享
良好的提交信息能够帮助团队成员理解代码变更的目的和范围。一个清晰的提交信息通常包括操作类型、描述更改的简短总结,以及对问题的引用。此外,共享代码库中的代码片段和常见模式可以提高开发效率,这可以通过代码片段库或团队内部共享文档来实现。
5.4.3 开源项目协作的特殊考量
开源项目通常具有更加松散和开放的协作模式。这种模式下,贡献者可能遍布全球,使用不同的语言和工具。因此,开源项目的协作工具往往需要更多的适应性,比如包容不同文化背景的沟通方式,提供更为灵活的权限管理等。同时,开源项目更需要关注代码的授权问题,确保代码的自由使用和再分发。
5.5 面向未来的代码协作趋势
5.5.1 AI在代码协作中的应用
人工智能技术已经开始渗透到软件开发的各个环节。在代码协作领域,AI可以协助自动化代码审查、提供编程建议、甚至预测代码缺陷。通过学习大量的代码库和模式,AI能够识别出代码中潜在的问题和改进点,从而提高开发效率和代码质量。
5.5.2 跨地域与文化的协作挑战
随着全球化的推进,软件开发团队越来越依赖于跨地域的协作。这要求团队成员能够跨越语言、文化和时区的差异进行有效沟通。适应这种工作模式的工具和服务,如多语言实时翻译和时区感知的会议安排,正变得越来越重要。
5.5.3 代码协作的可持续性问题
在追求技术进步的同时,软件开发行业也越来越重视可持续性问题。这不仅包括编写高效且易于维护的代码以减少资源消耗,还包括降低碳足迹的协作实践。例如,鼓励远程工作以减少通勤带来的排放,或是优化服务器使用以减少能源消耗等。团队协作方式的调整,将直接影响到软件产业的可持续发展目标。
journey
title 代码协作的未来趋势
section AI的辅助
代码审查: 4: 使用AI辅助代码审查提高效率
代码编写建议: 3: 利用AI提供编写建议
预测代码缺陷: 5: AI预测减少代码缺陷
section 跨地域协作
多语言实时翻译: 6: 实现更高效的跨语言沟通
时区感知会议: 2: 安排更容易参与的时区感知会议
section 可持续性
远程工作: 5: 鼓励远程工作减少通勤排放
优化服务器使用: 3: 减少能源消耗提高服务器效率
通过了解这些代码协作的最佳实践,我们可以更好地把握现代软件开发的趋势,以及如何在实践中应用这些策略来提升个人和团队的工作效率和代码质量。
6. 大数据技术架构分析与应用
随着信息技术的快速发展,大数据已经成为企业分析与决策的核心资产。企业需要高效地处理海量数据,并从中提取价值。本章将深入分析大数据技术架构,并探讨其在实际应用中的最佳实践。本章内容旨在为中高级IT专业人士提供大数据技术的深入理解和应用指南。
6.1 大数据技术架构概览
大数据技术架构包含多个层次,从数据采集到数据存储,再到数据处理和分析,最终为用户提供数据洞察。这一过程涵盖了数据的整个生命周期。
6.1.1 大数据技术架构核心组成
大数据技术架构通常包括以下几部分:
- 数据采集层 :主要负责从不同的数据源(如日志、传感器、社交媒体等)收集数据。
- 数据存储层 :负责存储收集到的原始数据,通常使用分布式文件系统(如HDFS)和NoSQL数据库(如HBase)。
- 数据处理层 :处理存储层中的数据,常见的处理框架包括MapReduce、Spark和Flink等。
- 数据分析层 :分析处理后数据,包括数据挖掘、机器学习和统计分析等,常用工具包括Hive、Presto和机器学习库等。
- 数据展现层 :将分析结果可视化,便于用户理解和决策,常用的工具有Tableau、Power BI和Kibana等。
6.1.2 大数据技术架构的特点
大数据技术架构具有以下特点:
- 高扩展性 :架构设计支持水平扩展,能够处理PB级别的数据。
- 高容错性 :系统能够在部分组件故障时继续运行,保证数据不丢失。
- 高性能 :框架设计能够高效利用集群资源,缩短数据处理时间。
- 实时性与批量处理 :同时支持实时处理和批量处理两种模式。
6.2 大数据技术架构的实践应用
6.2.1 大数据存储解决方案
在大数据场景下,存储解决方案必须考虑到数据的规模、读写速度和可靠性。Hadoop分布式文件系统(HDFS)是一个广泛使用的存储方案。
HDFS工作原理
HDFS是一个高度容错性的系统,适合运行在廉价硬件上。HDFS的数据以块(block)的形式存储,通常一个块的大小为64MB或128MB。这些块被分布在集群中的多个节点上,每个块都会有副本以保证容错。
# HDFS基本操作命令示例
hadoop fs -mkdir /data
hadoop fs -put localfile /data
hadoop fs -ls /
以上命令展示了如何在HDFS中创建目录、上传文件到HDFS和列出HDFS根目录下的文件或目录。
6.2.2 大数据处理框架的应用
在处理层,Apache Spark已经成为事实上的标准之一,它提供了一个快速、通用的计算引擎。
Apache Spark应用示例
Spark支持批处理、流处理和机器学习等多种工作模式。
// Spark示例代码:计算文本文件中单词的出现频率
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
此代码段展示了如何使用Spark对HDFS中的文本文件进行单词计数操作。数据被加载为RDD(弹性分布式数据集),然后经过扁平化、映射和归约操作得到每个单词的频率。
6.2.3 大数据分析与可视化
大数据分析和可视化是将原始数据转化为可行动见解的重要步骤。这里以Kibana和Elasticsearch结合使用的例子来展示如何进行大数据可视化。
Kibana与Elasticsearch结合应用
Elasticsearch是一个基于Lucene构建的开源搜索引擎,常用于存储和检索日志数据,而Kibana提供了一个强大的数据可视化界面。
// Elasticsearch索引映射示例
PUT /my_index
{
"mappings": {
"properties": {
"timestamp": { "type": "date" },
"message": { "type": "text" }
}
}
}
这段代码展示了如何定义一个Elasticsearch索引,包括其数据结构映射。索引被创建后,可以将数据索引到Elasticsearch中,并通过Kibana来展示日志时间序列的图表,提供对数据的洞察。
6.3 大数据技术的未来趋势
随着技术的进步,大数据技术也不断发展。本节将探讨一些大数据技术的未来趋势。
6.3.1 多模型数据库
多模型数据库支持多种数据模型(如键值对、文档、图形等)在同一系统中共存,为解决复杂数据查询提供了新的可能性。
6.3.2 人工智能与大数据的结合
人工智能(AI)和机器学习(ML)技术的发展,使得大数据分析变得更加强大和智能化。AI和ML可以用于预测分析,优化数据处理流程,提高数据价值的提取效率。
6.3.3 边缘计算
随着物联网(IoT)的广泛应用,数据的生成点越来越分散,边缘计算允许数据在最接近源的位置进行处理,从而减少延迟并提高性能。
通过本章节的介绍,我们了解了大数据技术架构的核心组成部分,实战应用以及未来的发展趋势。这些内容不仅对于大数据入门者有着基础性的教育意义,同时也为资深IT专业人士提供了深入的技术洞见和行业应用案例。希望本章内容能够为您的大数据学习之旅提供指导和启发。
7. 微服务架构下的接口设计与实践
在微服务架构中,接口设计不仅仅是一个编程概念,它更是服务间通信的核心。本章节将深入探讨如何在微服务架构下进行接口设计,以及如何确保接口的高效、安全和可维护。
5.1 微服务架构与接口设计
微服务架构将复杂的应用程序分解为一组小型的、松耦合的服务。每个服务实现特定的业务功能,并通过定义良好的接口与其他服务进行通信。这种设计模式允许不同的服务独立开发、部署和扩展。
5.1.1 接口的定义与角色
在微服务架构中,接口扮演着至关重要的角色:
- 服务发现 :服务通过接口实现自我描述,允许服务发现机制识别可用的服务实例。
- 通信协议 :定义了服务间交互的数据格式和协议,如HTTP REST, gRPC等。
- 契约 :作为一种契约,确保服务消费者和服务提供者对交互的预期保持一致。
5.1.2 接口设计原则
微服务架构中的接口设计应遵循以下原则:
- 单一职责 :一个接口只处理一种资源的交互。
- 明确无歧义 :接口的命名和参数应该清晰,不引起误解。
- 版本管理 :接口的变更应该以向后兼容的方式进行版本控制。
5.2 接口技术选型与实现
在选择技术实现接口时,有多种因素需要考量,包括性能、安全性、可维护性等。
5.2.1 RESTful API
RESTful API是一种广泛采用的接口设计方式,它利用HTTP协议的verb(如GET, POST, PUT, DELETE等)来表示操作的类型,并通过URL指向资源。
graph LR
A[客户端] -->|GET /api/users| B[(服务器)]
B -->|200 OK| A
5.2.2 GraphQL
GraphQL提供了一种更灵活的查询语言,允许客户端精确指定所需的数据结构,这在数据交互中尤其有用。
5.2.3 gRPC
gRPC是一种高性能、开源和通用的RPC框架,它基于HTTP/2协议传输,并使用Protocol Buffers作为接口描述语言。
5.3 接口测试与监控
接口一旦设计并实现,就需要进行测试和监控来确保其质量。
5.3.* 单元测试
单元测试是测试接口独立部分的基本工具,它确保每个接口按预期工作。
def test_user_creation():
user = User(name='John', age=30)
assert user.name == 'John'
assert user.age == 30
5.3.2 集成测试
集成测试确保不同服务间的接口协同工作正常。
def test_user_service():
assert User.create('Jane', 25) is not None
5.3.3 性能与监控
接口的性能测试和监控保证了服务的健康性和可用性。
- 监控工具:Prometheus, Grafana等。
- 性能测试工具:JMeter, Locust等。
5.4 安全性考量
在微服务架构中,安全性是接口设计的重要方面。
5.4.1 认证与授权
服务间通信需要确保安全性,通常使用OAuth2.0和OpenID Connect等协议进行认证和授权。
5.4.2 端点保护
接口端点应使用API Gateway进行保护,如使用速率限制、API密钥等机制。
5.4.3 数据加密
敏感数据传输和存储时应使用加密技术,如TLS/SSL和数据加密算法。
5.5 接口文档与契约
清晰的文档是微服务间接口成功的关键。接口文档应提供详细的信息,包括每个接口的请求和响应格式、参数说明和错误代码。
5.5.1 OpenAPI Specification
OpenAPI(以前称为Swagger)提供了一种标准的方式来描述API,允许自动生成文档和客户端库。
5.5.2 自动化文档生成
通过工具如Swagger UI或RAPIDOC可以将OpenAPI规范转换为交互式的API文档。
5.6 未来趋势:服务网格
服务网格如Istio和Linkerd提供了代理服务间的通信,并通过控制平面管理服务网格的流量。
- 流量管理 :包括负载均衡、故障转移、服务发现等。
- 安全性 :提供服务间通信的透明安全机制。
- 监控与故障诊断 :收集性能指标,提供服务网格的可视化。
在这一章节中,我们探讨了微服务架构下的接口设计与实践,从接口设计原则到技术选型,从测试监控到安全性考量,最后以服务网格作为未来趋势的展望。通过深入分析,我们能够为构建高效、安全、可维护的微服务接口提供坚实的基础。
简介:CRUD-CSI可能指一个涉及数据库CRUD操作和特定存储接口的项目或库。CRUD操作是数据库管理的基础,包括创建、读取、更新和删除记录。项目可能提供一种简化这些操作的接口,允许开发者通过ORM框架或直接SQL语句与数据库交互。CSI可能指计算机科学接口或云存储接口,涉及应用程序与服务的交互规范。本项目的实现细节不明确,需要查看源代码或文档以获取更深入的理解。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)