使用Mac版Docker搭建Hadoop集群(搭建集群与简单测试)
本文将开始正式介绍使用Mac版的Docker搭建Hadoop集群,基于的原始镜像是java:8,而不是hadoop,目的就是将虚拟机搭建集群的方式完全使用docker容器实现。如果是基于hadoop镜像,步骤将变得更加简单,可以参考docker 容器实现 hadoop分布式集群部署。前一篇文章已经做好了准备工作,接下来的工作主要是修改配置文件,假设当前已经在安装好的hadoop路径下,进入etc/
本文将开始正式介绍使用Mac版的Docker搭建Hadoop集群,基于的原始镜像是java:8,而不是hadoop,目的就是将虚拟机搭建集群的方式完全使用docker容器实现。如果是基于hadoop镜像,步骤将变得更加简单,可以参考docker 容器实现 hadoop分布式集群部署。
前一篇文章已经做好了准备工作,接下来的工作主要是修改配置文件,假设当前已经在安装好的hadoop路径下,进入etc/hadoop,修改以下配置文件:
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/lib/hadoop/data</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>namenode节点ip:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>secondary namenode节点ip或主机名:9868</value>
</property>
</configuration>注意这里的dfs.namenode.http-address值为节点ip+端口,其中的节点ip一般情况下可换为主机名,但Mac的宿主机和容器间是隔离的,最好写节点ip,然后运行namenode节点的容器时使用端口映射 -p 9870:9870,这样才能在宿主机访问到hdfs页面。
yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-service</name>
<value>mapreduce-shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>然后编辑workers文件,使其内容只有三个主机名:

注意不能有多余的空格和空行。
然后编辑hadoop-env.sh文件,添加两行环境变量(本来这两行在原文件中有,但被注释掉了,可以解除注释,修改相应内容使其生效):
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/lib/hadoop环境变量真实地址根据实际情况填写。最好回到hadoop安装路径,进入sbin目录,修改start-dfs.sh和stop-dfs.sh文件,添加以下内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root接着修改start-yarn.sh和stop-yarn.sh文件,添加以下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root上述这些USER不配好,就会报错:Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined。至此,配置文件基本改好,运行hdfs namenode -format进行初始化,如果运行完之后成功,可以在hadoop目录下看到新生产data和logs文件夹:
进入data/ dfs目录,可以看到name文件夹。
然后回到hadoop目录,运行命令启动HDFS:
sbin/start-dfs.sh如果运行成功,会在data/dfs/目录下看到新生成的data目录,并且使用jps在namenode节点(即hadoop1)查看java进程会看到:

在hadoop3节点会看到只有SecondaryNameNode:

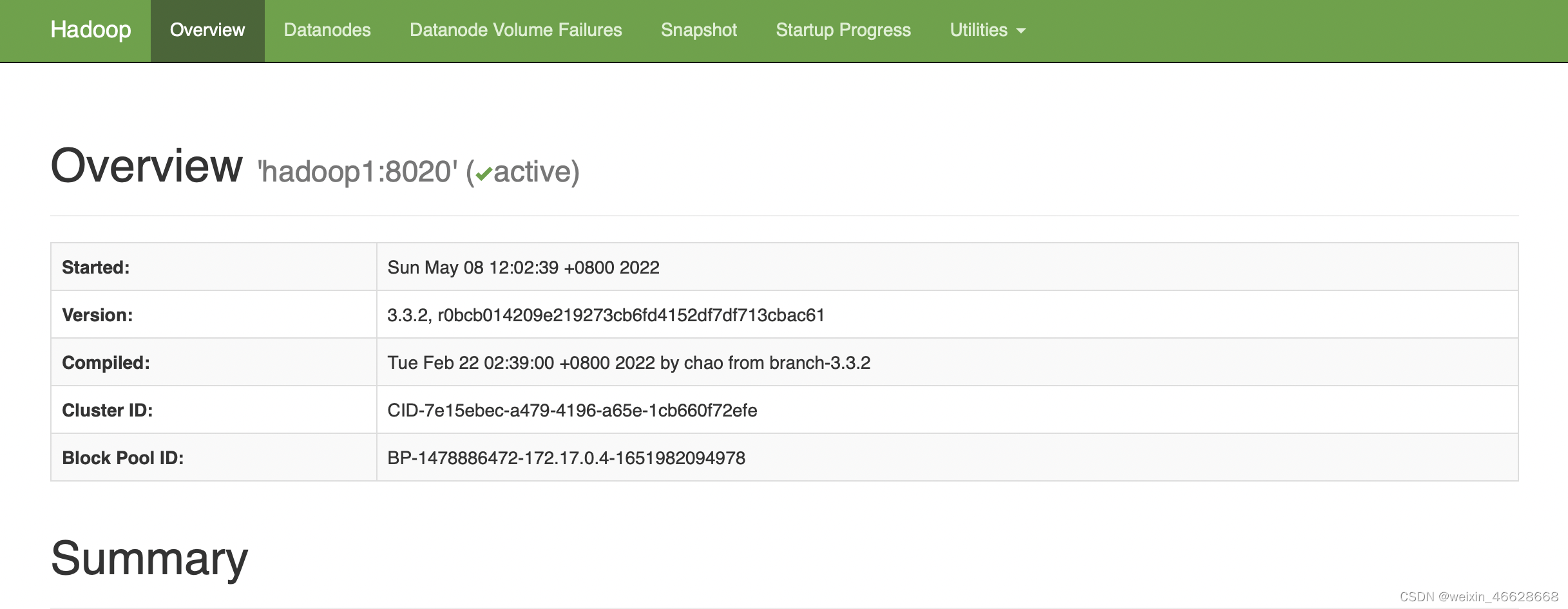
在Safari浏览器输入localhost:9870会看到页面:
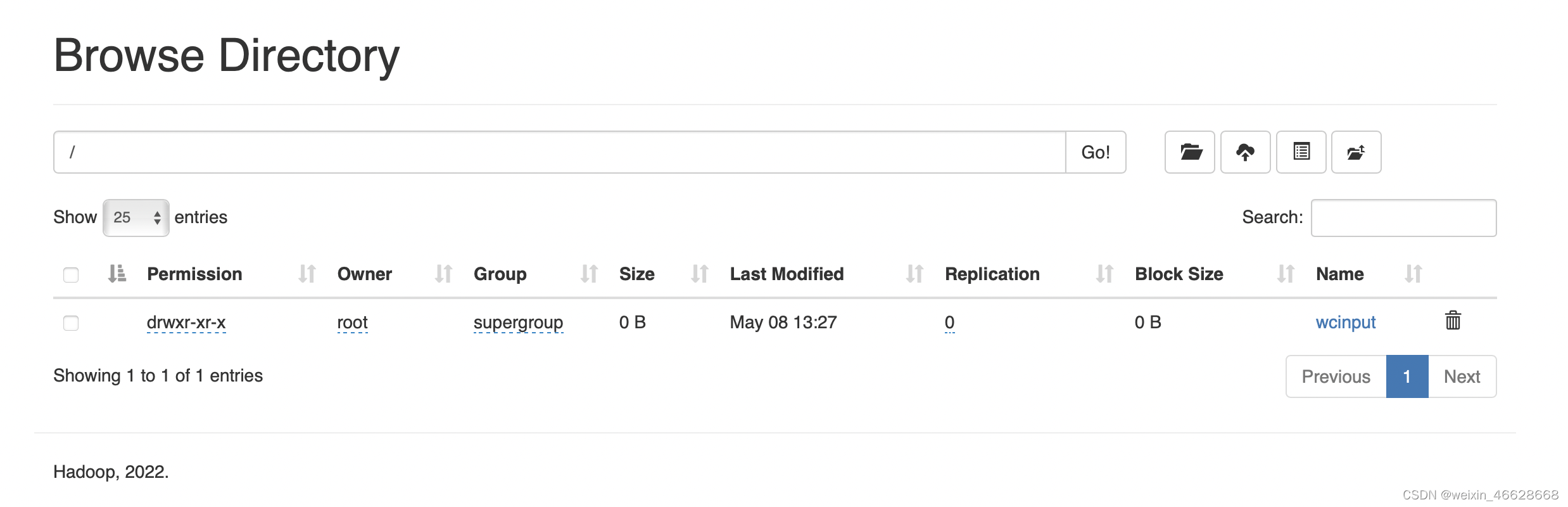
尝试创建目录:
hadoop fs -mkdir /wcinput可以看到前台页面出现了新的目录wcinput:
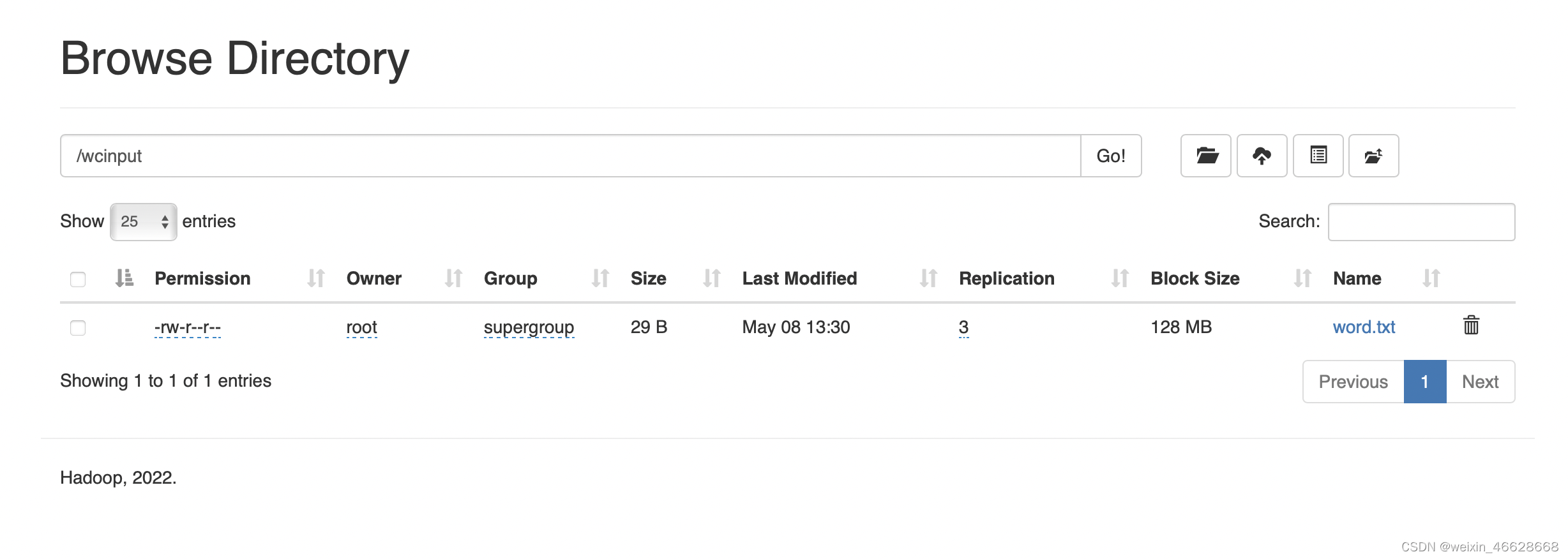
然后尝试上传文件:
hadoop fs -put wcinput/word.txt /wcinput运行结果:
真实数据存在如下路径: 
查看其中的文件:

与原文件内容一致。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)