大数据集成课程设计--Hive多维统计分析案例实战--hive安装--Hadoop安装--centos安装
从搭建集群到统计数据一条龙服务。一共三台虚拟机,请使用内存大于等于8G的主机。1、资源下载为了方便大家,所以提供各种安装包,节省查找时间1、虚拟机vmware16。下载地址:阿里云盘:「VMware-workstation-full-16.2.1-18811642.exe」https://www.aliyundrive.com/s/DKewRAUoVeg 提取码: tm08 点击链接保存,或者复制
一共三台虚拟机,请使用内存大于等于8G的主机。
目录
3、在soft里面新建文件夹jdk用来存放jdk解压后的包:
一、资源下载
为了方便大家,所以提供各种安装包,节省查找时间
1、虚拟机vmware16。下载地址:阿里云盘:
「VMware-workstation-full-16.2.1-18811642.exe」https://www.aliyundrive.com/s/DKewRAUoVeg 提取码: tm08 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看。
2、centos7。下载地址:种子链接:
magnet:?xt=urn:btih:A8896BD19E95DBFF5846423ACD28EDEEEC0CA075
3、Hadoop安装包。下载地址:阿里云盘:
4、hive安装包。下载地址:阿里云盘:
Index of /dist/hive/hive-3.1.2 (apache.org)
我用的是3.1.2版本
先这几个吧,等后面需要再提供其他的软件下载地址。
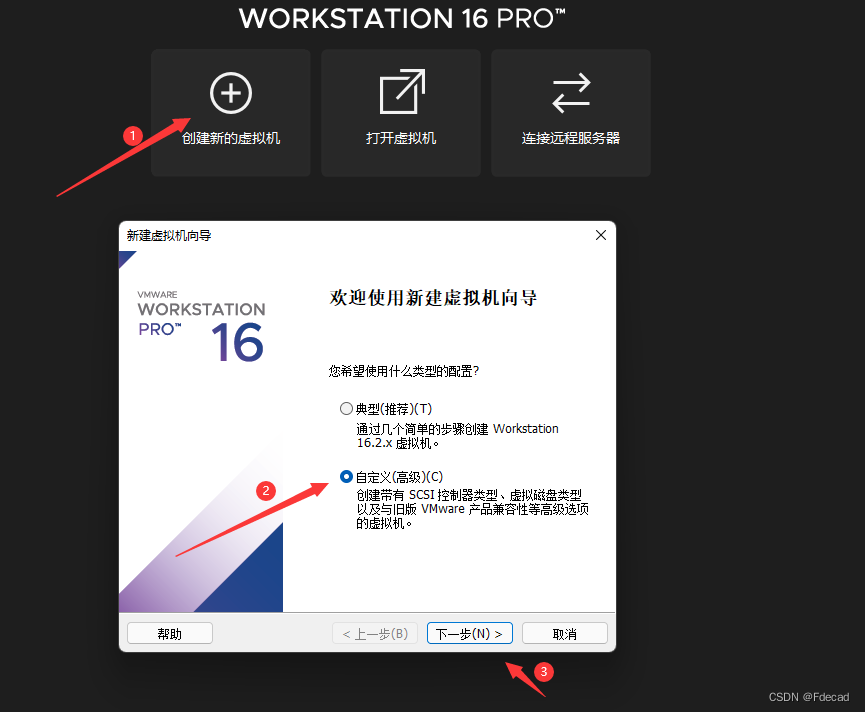
二、创建虚拟机













最后一步点完成就行。

三、安装centos7
转载链接:
CentOS 7教程(一)-初步入门及安装 - 知乎 (zhihu.com)
记得选GNOME安装!
四、安装hadoop
完全分布式安装。
我们搭建集群一共包含三台机器,分别命名为master、slave1、slave2。
1、首先将安装包放入我们安装好的centos虚拟机中。
准备安装包:Hadoop-3.1.2和jdk1.8.0_251

2、将其解压至/opt/soft目录下
tar -zxvf hadoop-3.2.2.tar.gz -C /opt/soft/hadoop解压完成之后像下图:

配置hadoop的环境变量:
vi /etc/profile
在最后一行插入:
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop/hadoop-3.2.2
export HADOOP_CONF_FILE=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

source /etc/profile3、在soft里面新建文件夹jdk用来存放jdk解压后的包:
解压jdk:
tar -zxvf jdk-8u251-linux-x64.tar.gz -C /opt/soft/jdk配置环境变量:
vi /etc/profile
在最后一行插入:
#java environment
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_251
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
更新环境变量:
source /etc/profile查看是否成功:
java -version
4、把虚拟机master复制两台出来

点击克隆。出现三台机器。

5、配置ip地址,并让三台机器互相登录
ifconfig 
记录下三台主机的IP地址。
master:192.168.47.130
slave1:192.168.47.133
salve2:192.168.47.134
写入host文件:(三台机器都要写)
vi /etc/hosts

检查一下hostname是否与虚拟机一致,如果不一致请用以下命令更改:
三台机器都要与ip地址匹配,这里只给出了master的修改命令。
hostnamectl set-hostname master关闭防火墙(不关闭可能ping不通):
// 临时关闭防火墙
systemctl stop firewalld
// 禁止开机启动防火墙
systemctl disable firewalld尝试ping一下slave1和slave2:

有回复,可以建立连接。
ssh免密登录:
ssh-keygen -t rsa
ssh-keygen -t rsa一直敲回车,直到出现:

然后上传到slave1和slave2中:
ssh-copy-id root@salve1
ssh-copy-id root@salve2以上步骤在不同机器上都执行一次。
配置成功后,我们可以用:
ssh slave1直接登录到slave1机器上。

6、编写配置文件
以下配置文件都在/opt/soft/hadoop/hadoop-3.2.2/etc/hadoop/下
cd /opt/soft/hadoop/hadoop-3.2.2/etc/hadoop- core-site.xml
vim core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop/hadoop_data/tmp</value>
</property>
</configuration>
- hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop/hadoop_data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop/hadoop_data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>master:50070</value>
</property>
</configuration>
- yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>- mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>- hadoop-env.sh
vim hadoop-env.shexport JAVA_HOME=/opt/soft/jdk/jdk1.8.0_251
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HBASE_HOME/lib/*:classpath把配置文件分发至其它节点:
scp hdfs-site.xml root@slave1:$HADOOP_HOME/etc/hadoop/五个文件都要分发至两台机器上,上条命令仅分发一次。或者把整个目录下的文件都拷贝过去,仅需两次操作。
7、第一次启动hadoop
第一次启动集群要格式化,往后在启动集群就不用了。
hdfs namenode -format启动命令
start-dfs.sh或者:
start-all.sh输入jps查看进程:

启动成功!
如果报错:
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.参考这个教程:Hadoop之——以root身份启动Hadoop3.x报错_hadoop3root用户启动从节点失败-CSDN博客
五、安装hive
1、解压hive
把hive安装包放入opt目录下
cd /opt
tar -zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive 2、设置环境变量
vi /etc/profile在最后一行插入,保存并退出。
#hive
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$PATH
source /etc/profile3、安装mysql
这里贴一个其他博主写的安装过程。
CentOS7 安装MYSQL的教程_A4n9g7e2l的博客-CSDN博客_centos7安装mysql教程 https://blog.csdn.net/Angelxiqi/article/details/119155252mysql安装完成后还要进行安装驱动:
https://blog.csdn.net/Angelxiqi/article/details/119155252mysql安装完成后还要进行安装驱动:
驱动包下载地址:这里还是贴一个下载地址:
Maven Repository: mysql » mysql-connector-java » 5.1.48 (mvnrepository.com)

点击箭头处即可下载。下载好了之后解压,并执行以下命令:
tar -zxvf mysql-connector-java-5.1.48.tar.gz
cd mysql-connector-java-5.1.48
cp mysql-connector-java-5.1.48-bin.jar /opt/hive/lib/ 使用root用户登录mysql:
mysql -uroot -pcreate database hiveDB; 创建用户bee,密码为123123
create user 'bee'@'%' identified by '123123'; 授权用户bee拥有数据库实例hiveDB的所有权限;
grant all privileges on hiveDB.* to 'bee'@'%' identified by '123123'; 刷新
flush privileges; 4、hive配置
在$HIVE_HOME/conf目录下:

vim hive-site.xml编辑如下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/opt/hive/tmp</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive/logs</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<property>
<name>hive.session.id</name>
<value>false</value>
</property>
<property>
<name>hive.session.silent</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>bee</value>
<!-- 这里是之前设置的数据库 -->
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!-- 这里是数据库密码 -->
<value>123123</value>
</property>
</configuration>
vim hive-env.sh插入:
HADOOP_HOME=/opt/soft/hadoop/hadoop-3.2.2
配置完成。
5、第一次启动hive
schematool -dbType mysql -initSchema安装完成。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)