Redis自带的redis-benchmark使用
1 实验数据Redis自带一个叫redis-benchmark的工具来模拟N个客户端同时发出M个请求。实验进行了如下对比测试:(1) 分别在安静模式下与显式使用命令来运行进行对比;(2) 在单一的key和随机key模式下对比;(3) 在默认50个客户端、100个客户端和10个客户端下对比;(4) 在按顺序执行命令和一次性执行多条命令进行对比。实验硬件条件:在虚拟机下,2个处理器,5G
1 实验数据
Redis自带一个叫redis-benchmark的工具来模拟N个客户端同时发出M个请求。实验进行了如下对比测试:
(1) 分别在安静模式下与显式使用命令来运行进行对比;
(2) 在单一的key和随机key模式下对比;
(3) 在默认50个客户端、100个客户端和10个客户端下对比;
(4) 在按顺序执行命令和一次性执行多条命令进行对比。
实验硬件条件:在虚拟机下,2个处理器,5GB内存,20G硬盘。
分别测试如下命令:
(1) PING_INLINE
(2) PING_BULK
(3) SET:将字符串值value关联到key;
(4) GET:返回key所关联的字符串值,如果key存储的值不是字符串类型,返回一个错误;
(5) INCR:将key中存储的数字值增一。不能转换为数字则报错;
(6) LPUSH:将一个或多个值value插入到列表key的表头;
(7) RPUSH:将一个或多个值value插入到列表key的表尾;
(8) LPOP:移除并返回列表key的头元素;
(9) RPOP:移除并返回列表key的尾元素;
(10) SADD:将一个或多个member元素加入到集合set当中,已经存在于集合的member元素将被忽略;
(11) SPOP:移除并返回集合中的一个随机元素;
(12) LPUSH:将一个或多个value插入到列表key的表头;
(13) LRANGE_100:返回列表key中指定区间内的元素,前100条元素;
(14) LRANGE_300:返回列表key中指定区间内的元素,前300条元素;
(15) LRANGE_500:返回列表key中指定区间内的元素,前500条元素;
(16) LRANGE_600:返回列表key中指定区间内的元素,前600条元素;
(17) MSET:同时设置一个或多个key-value对,value为字符串。
2 实验结果
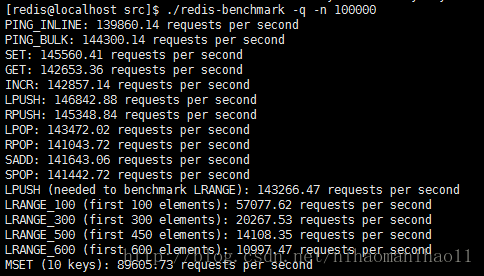
(1)./redis-benchmark -q -n 100000
运行在安静的模式中,且只使用单一的key。
(2)./redis-benchmark -n 100000 -q script load “redis.call(‘set’, ‘foo’, ‘bar’)”
使用直接命令来运行。

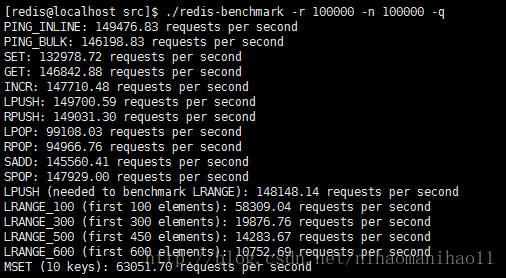
(3)./redis-benchmark -r 100000 -n 100000 -q
运行在安静的模式中,并且设置10万随机key。
(4)默认情况下,每个客户端都是在一个请求完成之后才发送下一个请求的,benchmark默认会模拟50个客户端,这意味着服务器几乎是按顺序读取每个客户端的命令。
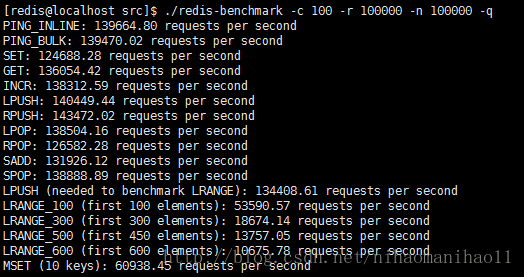
./redis-benchmark -c 100 -r 100000 -n 100000 -q
模拟100个客户端
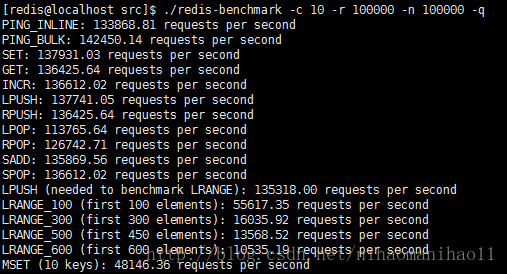
./redis-benchmark -c 10 -r 100000 -n 100000 -q
模拟10个客户端
(5)Redis支持/topics/pipelining,使得可以一次性执行多条命令成为可能。Redis pipelining可以提高服务器的TPS。
./redis-benchmark -r 100000 -n 100000 -P 16 –q
Pipelining 16条命令的测试。
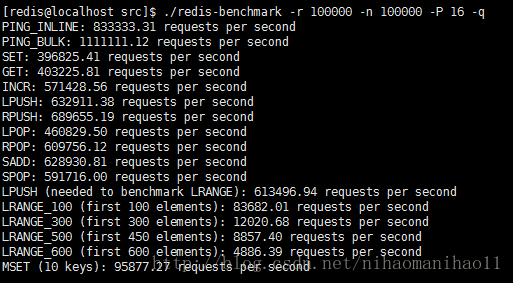
3 实验分析
重点比较SET/GET/INCR/LPUSH/LPOP/SADD/SPOP/LRANGE_100这几个命令的性能。
场景数字代表的意思
1:单一key,50客户端;2:随机key,50客户端;3: 随机key,100客户端;4: 随机key,10客户端;5: 随机key,50客户端,并发执行。
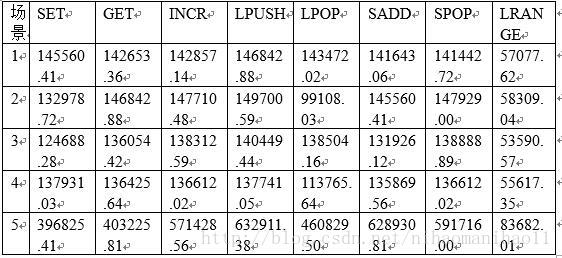
注:表格所有数据的单位:每秒的请求数。
从上面表格可以看出:
(1) 对于相同客户端的情况下,随机key的每秒请求数,SET和LPOP减少,GET、INCR、LPUSH、SADD、SPOP和LRANGE增加了;
(2) 在随机生成key值的情况下,SET、SADD操作随着客户端数增加,每秒请求数减少;考虑到cache命中的情况,其他命令变化趋势没有规律;
(3) 其他条件一致,并发执行情况下,各种命令都是有大幅度增加。
从上面可以得出结论:在真实环境下,应对大数据,大并发,可以通过增加缓存大小,并发执行来提高吞吐量。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)