[虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(三)(终篇)
[虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(一)[虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(二)接前两篇,这是最终篇,前面的准备工作都完成了之后,我们开始安装和部署hadoop安装和配置Hadoophadoop-2.2.0_x64.tar.gz链接:http://pan.baidu.com/s/1boSGvrp 密码:559ohadoo
[虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(一)
[虚拟机VM][Ubuntu12.04]搭建Hadoop完全分布式环境(二)
接前两篇,这是最终篇,前面的准备工作都完成了之后,我们开始安装和部署hadoop
安装和配置Hadoop
hadoop-2.2.0_x64.tar.gz
链接:http://pan.baidu.com/s/1boSGvrp 密码:559o
hadoop集群中每台机器的配置都基本相同,我们先配置好master,然后复制到slave1和slave2上
1、下载并解压,并重命名目录为hadoop,移动到/usr目录下去
hadoop@master:~$ tar -zxvf hadoop-2.2.0_x64.tar.gz
hadoop@master:~$ mv hadoop-2.2.0 hadoop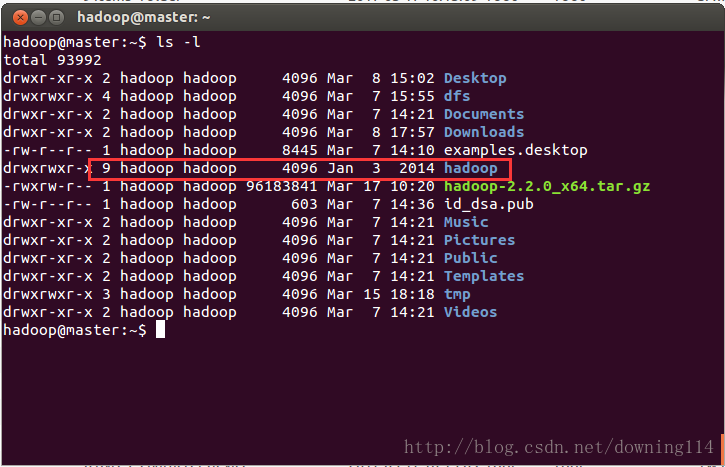
hadoop@master:~$ sudo mv ~/hadoop /usr/2、创建几个关键目录,以备后用:
hadoop@master:~$ mkdir dfs
hadoop@master:~$ mkdir dfs/name
hadoop@master:~$ mkdir dfs/data
hadoop@master:~$ mkdir tmp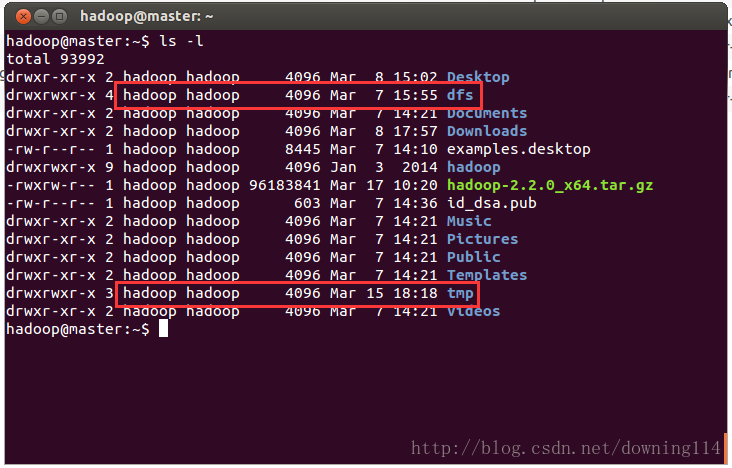
3、修改配置文件:
~/hadoop/etc/hadoop/hadoop-env.sh
~/hadoop/etc/hadoop/yarn-env.sh
~/hadoop/etc/hadoop/slaves
~/hadoop/etc/hadoop/core-site.xml
~/hadoop/etc/hadoop/hdfs-site.xml
~/hadoop/etc/hadoop/mapred-site.xml
~/hadoop/etc/hadoop/yarn-site.xml3.1 修改hadoop-env.sh,将JAVA_HOME后面填写上自己的JDK路径
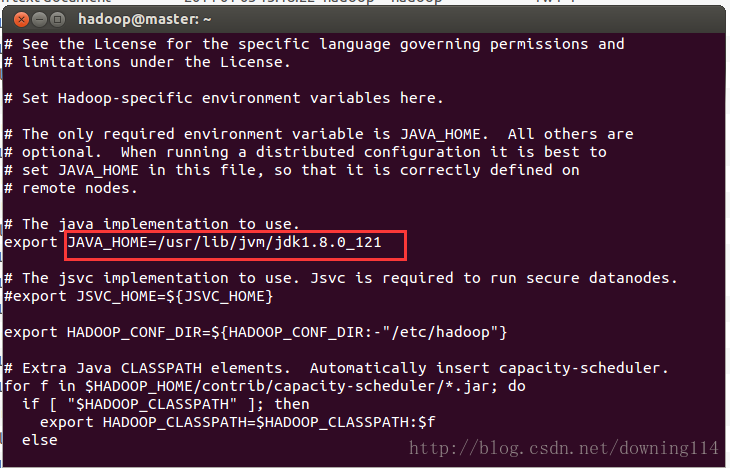
3.2 修改yarn-env.sh,将JAVA_HOME后面填写上自己的JDK路径
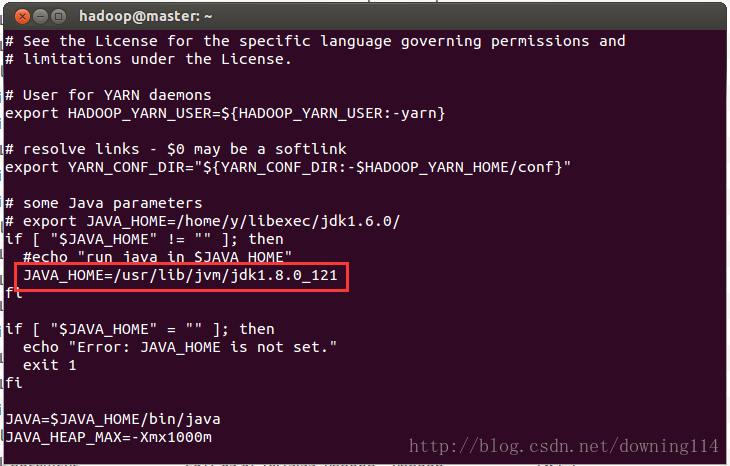
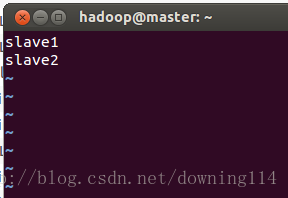
3.3 修改slaves,填写所有的slave节点
3.4 修改core-site.xml,说明:
hdfs://master:8020中的master是hostname,如果你们设置的跟我的不一样请修改file:/home/hadoop/tmp就是刚才第2步设置的目录,如果你们设置的跟我的不一样请修改hadoop.proxyuser.hadoop.hosts和hadoop.proxyuser.hadoop.groups中的第二个hadoop换成自己的用户名
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>3.5 修改hdfs-site.xml,说明:
master:9001中的master是hostname,如果你们设置的跟我的不一样请修改file:/home/hadoop/dfs/name和file:/home/hadoop/dfs/data就是刚才第2步设置的目录,如果你们设置的跟我的不一样请修改
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>3.6 修改mapred-site.xml,说明:其中的master是hostname,如果你们设置的跟我的不一样请修改
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>3.7 修改yarn-site.xml,说明:其中的master是hostname,如果你们设置的跟我的不一样请修改
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>4、master配置完成,我们把hadoop整个目录复制到slave1和slave2上去
hadoop@master:~$ sudo scp -r /usr/hadoop hadoop@slave1:~/
hadoop@master:~$ sudo scp -r /usr/hadoop hadoop@slave2:~/5、使用ssh分别到slave1和slave2机器上将hadoop目录移动到和master相同的目录中去
hadoop@master:~$ ssh slave1
hadoop@slave1:~$ sudo mv ~/hadoop/ /usr/hadoop@master:~$ ssh slave2
hadoop@slave2:~$ sudo mv ~/hadoop/ /usr/6、添加hadoop路径到环境变量中
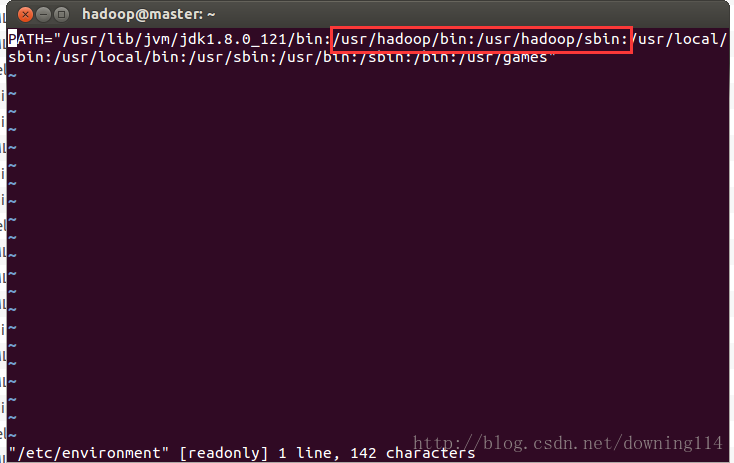
hadoop@master:~$ vi /etc/environment
hadoop@master:~$ source /etc/environment添加以下红框的内容,如果你们的hadoop路径和我的不一样,请修改
7、启动hadoop
格式化namenode
hadoop@master:~$ hdfs namenode –format启动hdfs
hadoop@master:~$ start-dfs.sh启动yarn
hadoop@master:~$ start-yarn.sh8、查看进程
先看master的:
hadoop@master:~$ jps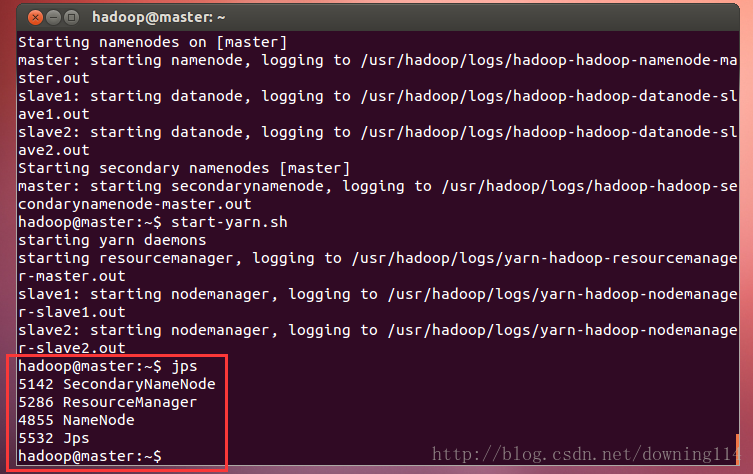
到slave1上查看进程:
hadoop@master:~$ ssh slave1
hadoop@slave1:~$ jps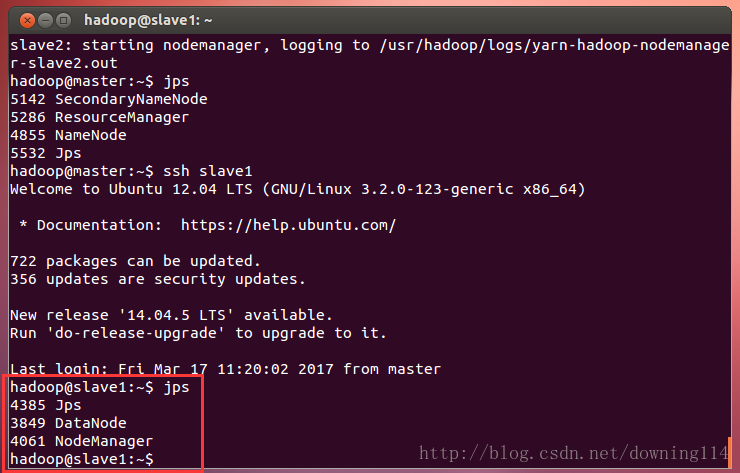
也可以到浏览器中输入http://master:8088/查看:
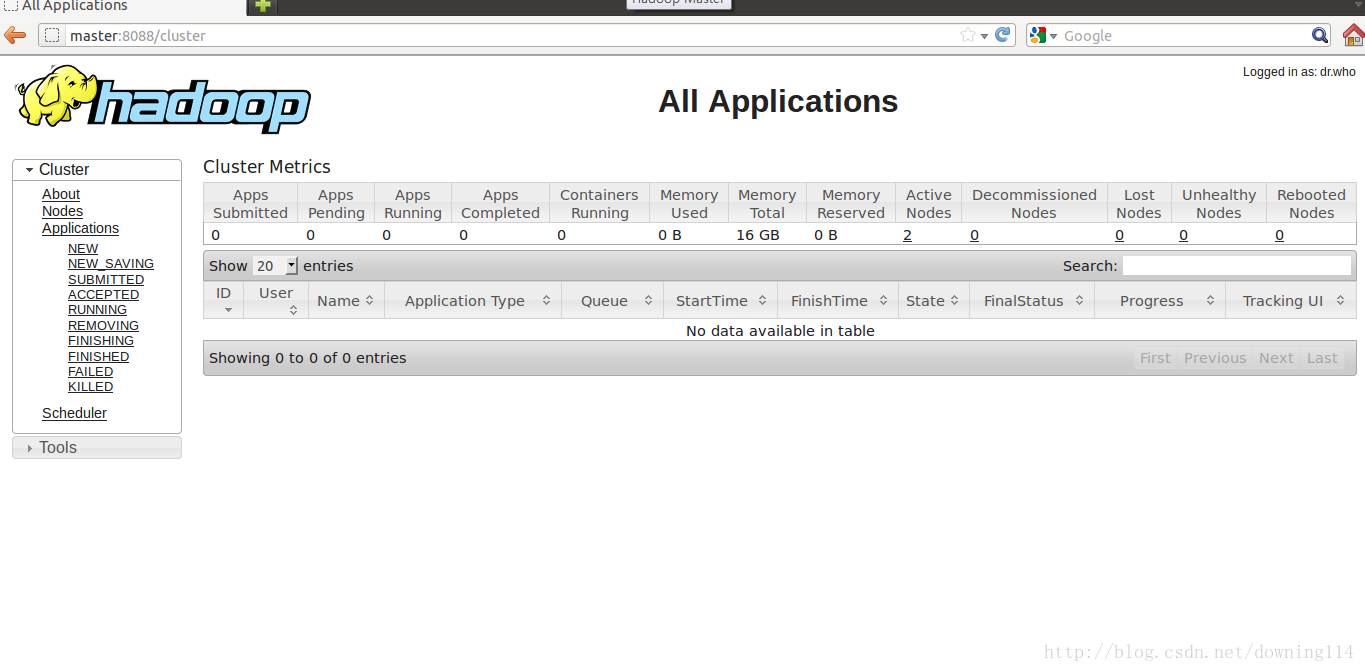
至此,Hadoop完全分布式环境已全部搭建完成!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)