Hadoop云计算的初步认识
在说Hadoop之前,作为一个铁杆粉丝先粉一下Google。Google的伟大之处不仅在于它建立了一个强悍的搜索引擎,它还创造了几项革命性的技术:GFS,MapReduce,BigTable,即所谓的Google三驾马车。Google虽然没有公布这几项技术的实现代码,但它发表了详细的设计论文,这给业界带来了新鲜气息,很快就出现了类似于Google三驾马车的开源实现,Hadoop就是其中的一个。
·
在说Hadoop之前,作为一个铁杆粉丝先粉一下Google。Google的伟大之处不仅在于它建立了一个强悍的搜索引擎,它还创造了几项革命性的技术:GFS,MapReduce,BigTable,即所谓的Google三驾马车。Google虽然没有公布这几项技术的实现代码,但它发表了详细的设计论文,这给业界带来了新鲜气息,很快就出现了类似于Google三驾马车的开源实现,Hadoop就是其中的一个。
1.什么是Hadoop
Hadoop主要是由HDFS和MapReduce组成,HDFS是一个分布式文件系统(Hadoop Distributed File System),MapReduce则是用于并行处理大数据集的软件框架。因此,Hadoop是一个能够对大量数据进行分布式处理的软件框架,它是一种技术的实现。
Hadoop是Apache基金会下的一款开源软件,它实现了包括分布式文件系统HDFS和MapReduce框架在内的云计算软件平台的基础架构,并且在其上整合了包括数据库、云计算管理、数据仓储等一系列平台,其已成为工业界和学术界进行云计算应用和研究的标准平台。Hadoop现在已经广泛应用于包括国外的FaceBook,Twitter,Yahoo!等公司,国内的百度,阿里等,Hadoop运行在数以千计的服务器和数以万计的CPU的集群上。
Hadoop是Apache基金会下的一款开源软件,它实现了包括分布式文件系统HDFS和MapReduce框架在内的云计算软件平台的基础架构,并且在其上整合了包括数据库、云计算管理、数据仓储等一系列平台,其已成为工业界和学术界进行云计算应用和研究的标准平台。Hadoop现在已经广泛应用于包括国外的FaceBook,Twitter,Yahoo!等公司,国内的百度,阿里等,Hadoop运行在数以千计的服务器和数以万计的CPU的集群上。
通俗的说Hadoop是一套开源的、基础是Java的、目前能够让数千台普通、廉价的服务器组成一个稳定的、强大的集群,使其能够对pb级别的大数据进行存储、计算。已经具有了强大稳定的生态系统,也具有很多使用的延伸产品。比如做查询的Pig, 做分布式命名服务的ZooKeeper, 做数据库的Hive等等。
基于Hadoop,用户可编写处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。Hadoop已被全球几大IT公司用作其”云计算”环境中的重要基础软件,如:雅虎正在开发基于Hadoop的开源项目Pig, 这是一个专注于海量数据集分析的分布式计算程序。亚马逊公司则基于Hadoop推出了Amazon S3(Amazon Simple Storage Service ),提供可靠,快速,可扩展的网络存储服务。因此,Hadoop是云计算中一部分技术的实现,而不是全部。
基于Hadoop,用户可编写处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。Hadoop已被全球几大IT公司用作其”云计算”环境中的重要基础软件,如:雅虎正在开发基于Hadoop的开源项目Pig, 这是一个专注于海量数据集分析的分布式计算程序。亚马逊公司则基于Hadoop推出了Amazon S3(Amazon Simple Storage Service ),提供可靠,快速,可扩展的网络存储服务。因此,Hadoop是云计算中一部分技术的实现,而不是全部。
2.关于MapReduce
Hadoop说起来很简单,一个存储系统(HDFS),一个计算系统(MapReduce)。仅此而已。模型虽然简单,但我觉得它的精妙之处也就在这里。目前,通过提高CPU主频来提升计算性能的时代已经结束了,因此并行计算、分布式计算在业界发展了起来,但是这也往往意味着复杂的设计与实现,如果能找到一种方法,只需要写简单的程序就能实现分布式计算,那就太好了。
我们可以回想下当初做的课堂作业,它可能是一个处理数据的程序,没有多线程,没有进程间通信,数据输入都是来自键盘(stdin),处理完数据之后打印到屏幕(stdout),这时的程序非常简单。后来我们学习了多线程、内存管理、设计模式,写出的程序越来越大,也越来越复杂。但是当学习使用Hadoop时,我们发现又回到了最初,尽管底层是一个巨大的集群,可是我们操作文件时就像在本地一样简单,写MapReduce程序时也只需要在单线程里实现数据处理。
Hadoop就是这样一个东西,简单的文件系统(HDFS),简单的计算模型(MapReduce)。这其中,我觉得HDFS是很自然的东西,如果我们自己实现一个,也很可能是这样的。但是仔细琢磨下MapReduce,会发现它似乎是个新奇事物,不像HDFS的界面那样通俗易懂老少皆宜。MapReduce虽然模型简单,却是一个新的、不广为人所知的概念。比如说,如果说要简化计算,为何要做成Map和Reduce两个阶段,而不是一个函数足矣呢?另外,它也不符合我们耳熟能详的那些设计模式。一句话,MapReduce实在太另类了。
Hadoop的思想来源于Google的几篇论文,Google的那篇MapReduce论文里说:
我们可以回想下当初做的课堂作业,它可能是一个处理数据的程序,没有多线程,没有进程间通信,数据输入都是来自键盘(stdin),处理完数据之后打印到屏幕(stdout),这时的程序非常简单。后来我们学习了多线程、内存管理、设计模式,写出的程序越来越大,也越来越复杂。但是当学习使用Hadoop时,我们发现又回到了最初,尽管底层是一个巨大的集群,可是我们操作文件时就像在本地一样简单,写MapReduce程序时也只需要在单线程里实现数据处理。
Hadoop就是这样一个东西,简单的文件系统(HDFS),简单的计算模型(MapReduce)。这其中,我觉得HDFS是很自然的东西,如果我们自己实现一个,也很可能是这样的。但是仔细琢磨下MapReduce,会发现它似乎是个新奇事物,不像HDFS的界面那样通俗易懂老少皆宜。MapReduce虽然模型简单,却是一个新的、不广为人所知的概念。比如说,如果说要简化计算,为何要做成Map和Reduce两个阶段,而不是一个函数足矣呢?另外,它也不符合我们耳熟能详的那些设计模式。一句话,MapReduce实在太另类了。
Hadoop的思想来源于Google的几篇论文,Google的那篇MapReduce论文里说:
Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages。
这句话提到了MapReduce思想的渊源,大致意思是,MapReduce的灵感来源于函数式语言(比如Lisp)中的内置函数map和reduce。函数式语言也算是阳春白雪了,离我们普通开发者总是很远。简单来说,在函数式语言里,map表示对一个列表(List)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。不过从这样的解释到现实中的MapReduce还太远,仍然需要一个跳跃。再仔细看,reduce既然能做迭代计算,那就表示列表中的元素是相关的,比如我想对列表中的所有元素做相加求和,那么列表中至少都应该是数值吧。而map是对列表中每个元素做单独处理的,这表示列表中可以是杂乱无章的数据。这样看来,就有点联系了。在MapReduce里,Map处理的是原始数据,自然是杂乱无章的,每条数据之间互相没有关系;到了Reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性,至少它们都在一个key下面,于是就符合函数式语言里map和reduce的基本思想了。
这样我们就可以把MapReduce理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。这就回到了最初,终于知道MapReduce为何要这样设计。
这样我们就可以把MapReduce理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。这就回到了最初,终于知道MapReduce为何要这样设计。
3.什么是云计算
云计算是继1980年代大型计算机到客户端-服务器的大转变之后的又一种巨变,但云计算的概念其实早已提出很久,早在上世纪60年代,麦卡锡就提出了把计算能力作为一种像水和电一样的公用事业提供给用户的理念,这成为云计算思想的起源。在20世纪80年代网格计算、90年代公用计算,21世纪初虚拟化技术、SOA、SaaS应用的支撑下,云计算作为一种新兴的资源使用和交付模式逐渐为学界和产业界所认知。因此,云计算的存在只是一种新的商业计算模型和服务模式。

4.Hadoop云计算的关系
因此可以得出一个结论:Hadoop是一个能够对大量数据进行分布式处理的软件框架,它是一种技术的实现,是云计算技术中重要的组成部分,云计算的概念更广泛且偏向业务而不是必须拘泥于某项具体技术,云计算的存在只是一种新的商业计算模型和服务模式。因此,云计算才会出现“横看成岭侧成峰,远近高低各不同”,各种各样层出不穷的理解。5.Hadoop的作用
Hadoop作为大数据存储及计算领域的一颗明星,目前已经得到越来越广泛的应用。下面主要分析了Hadoop的一些典型应用场景,并对其进行了深入分析,主要包括下面几个方面:
日志处理: Hadoop擅长这个
并行计算
ETL: 每个人几乎都在做ETL(Extract-Transform-Load)工作 Netezza关于使用Hadoop做ETL任务的看法)
使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
机器学习: 比如Apache Mahout项目
Hadoop是什么?
是google的核心算法MapReduce的一个开源实现。用于海量数据的并行处理。 hadoop的核心主要包含:HDFS和MapReduce, HDFS是分布式文件系统,用于分布式存储海量数据。 MapReduce是分布式数据处理模型,本质是并行处理。
多少数据算海量数据?
个人认为,TB(1024GB)级别往上就可以算海量数据。
谁在使用hadoop?
N多大型互联网公司,这里列的比较全:http://wiki.apache.org/hadoop/PoweredBy
在国内,包括中国移动、百度、网易、淘宝、腾讯、金山和华为等众多公司都在研究和使用它
用它来做什么?
海量数据处理。。。似乎有点虚,用hadoop的地方:
1、最简单的,做个数据备份/文件归档的地方,这利用了hadoop海量数据的存储能力
2、数据仓库/数据挖掘:分析web日志,分析用户的行为(如:用户使用搜索时,在搜索结果中点击第2页的概率有多大)
3、搜索引擎:设计hadoop的初衷,就是为了快速建立索引。
4、云计算:据说,中国移动的大云,就是基于hadoop的
5、研究:hadoop的本质就是分布式计算,又是开源的。有很多思想值得借鉴。
日志处理: Hadoop擅长这个
并行计算
ETL: 每个人几乎都在做ETL(Extract-Transform-Load)工作 Netezza关于使用Hadoop做ETL任务的看法)
使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
机器学习: 比如Apache Mahout项目
Hadoop是什么?
是google的核心算法MapReduce的一个开源实现。用于海量数据的并行处理。 hadoop的核心主要包含:HDFS和MapReduce, HDFS是分布式文件系统,用于分布式存储海量数据。 MapReduce是分布式数据处理模型,本质是并行处理。
多少数据算海量数据?
个人认为,TB(1024GB)级别往上就可以算海量数据。
谁在使用hadoop?
N多大型互联网公司,这里列的比较全:http://wiki.apache.org/hadoop/PoweredBy
在国内,包括中国移动、百度、网易、淘宝、腾讯、金山和华为等众多公司都在研究和使用它
用它来做什么?
海量数据处理。。。似乎有点虚,用hadoop的地方:
1、最简单的,做个数据备份/文件归档的地方,这利用了hadoop海量数据的存储能力
2、数据仓库/数据挖掘:分析web日志,分析用户的行为(如:用户使用搜索时,在搜索结果中点击第2页的概率有多大)
3、搜索引擎:设计hadoop的初衷,就是为了快速建立索引。
4、云计算:据说,中国移动的大云,就是基于hadoop的
5、研究:hadoop的本质就是分布式计算,又是开源的。有很多思想值得借鉴。
6.Java和Hadoop的关系
Java是一种程序设计语言,云计算是一种新的商业计算模型和服务模式。他们实际上是没有直接关系的,但是由于Java 技术具有卓越的通用性、高效性、平台移植性和安全性,并且广泛应用于个人PC、数据中心、游戏控制台、科学超级计算机、智能手机、物联网和互联网,同时拥有全球最大的开发者专业社群。在全球云计算和移动互联网的产业环境下,Java更具备了显著优势和广阔前景,Java已经成为一个庞大而复杂的技术平台。
Java与云计算的关系主要体现在以下几个方面:
Java在云计算中的优势:
Java使云计算更简单,Java具有简单性、兼容性、简易性、安全性、动态性、高性能、解释性、健壮性
Java与云计算的关系主要体现在以下几个方面:
Java在云计算中的优势:
Java使云计算更简单,Java具有简单性、兼容性、简易性、安全性、动态性、高性能、解释性、健壮性
Java与分布式计算:
基于JAVA的分布式程序设计:
基于Socket的编程
基于RMI的分布式编程
基于CORBA的分布式编程
Java与并行计算:
JDK 1.5引入java.util.cocurrent包
Java中的多线程技术实现并行计算( JET 平台)
Java SE 5 中的锁,原子量 并行容器,线程调度 以及线程执行
基于Java的分布并行计算环境Java PVM
云计算开源框架支持:
Hadoop是Java开发,很多其他的云计算相关开源软件也是由Java开发或者提供Java API
Java使得云计算的实现更为简单,而云计算让Java更有活力,找到一个新的结合点。Java在互联网应用有着独特的优势,而云计算是基于互联网的新的商业计算模型和服务模式,两者相结合,势必创造更大价值。
7.理清Nosql,Mongodb,hadoop各种匪夷所思的关系
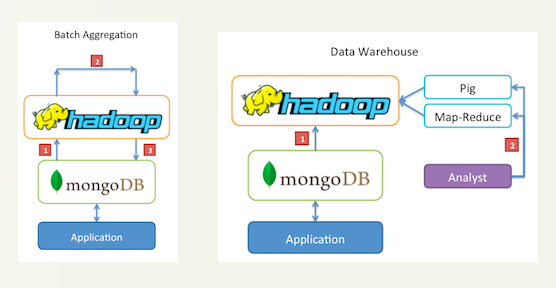
NoSQL,是not only sql,是非关系数据库,不同于oracle等关系数据库。而mongodb是一种非关系型的分布式数据库,是nosql的实现方式之一,nosql理论下的数据库有很多,mongodb仅仅代表其中一种,hadoop是分布式解决方案,是一套包含了很多组件的框架,即为Mapreduce(计算的)和HDFS(文件系统)等等,使用Hadoop和NoSQL型数据库整合可以构造海量数据解决方案,MongoDB作为数据源存储以及数据结果存储,而具体的计算过程在Hadoop中进行.
8.渐进学习Hadoop
(1)先搭建一个单节点的 Hadoop平台,先将那些疑问放一边,先去学习如何搭建这个平台;
(2)尝试用Hadoop管理各类文件,尝试将数据存放于其非关系型数据库中,尝试编写一个MapReduce程序,通过些步骤,能够大概的认识到Hadoop是一个海量的数据、文件的存放平台,上面提供了各种通用的工具以帮助用户更好的去分析、应用与处理这些数据与文件;
(3)考虑一个问题:如果当前有一个任务交给你,去实现一个TB、乃至PB级数据的海量存取与快速查询,你最后如果实现了这一任务,其实就是实现了一个专用任务的Hadoop平台,考虑到未来有很多类似的任务,将你的专用Hadoop平台改造成通用性平台,以方便其他用户使用,那你可能就真正实现了一个类似于Hadoop的应用系统。用这样的思维去看待Hadoop可能会让用户理解的为更透彻,另外当用户对这个认识模糊时,大可以不用太担心,这多半是由于当前的实际工作可能还用不上,如果真碰到这样的大数据处理,通过思考就能很快理解Hadoop的好处。
(4)实现多节点的安装与部署,并尝试设置节点失效,看一下如何去管理与调度、监测任务的执行。
(5)实现大批量专用工具部署,并尝试实现1万个文件的存取、数千万数据的写入与查询,再去重新认识一下Hadoop。
(6)尝试在工作中开始实现Hadoop。
(2)尝试用Hadoop管理各类文件,尝试将数据存放于其非关系型数据库中,尝试编写一个MapReduce程序,通过些步骤,能够大概的认识到Hadoop是一个海量的数据、文件的存放平台,上面提供了各种通用的工具以帮助用户更好的去分析、应用与处理这些数据与文件;
(3)考虑一个问题:如果当前有一个任务交给你,去实现一个TB、乃至PB级数据的海量存取与快速查询,你最后如果实现了这一任务,其实就是实现了一个专用任务的Hadoop平台,考虑到未来有很多类似的任务,将你的专用Hadoop平台改造成通用性平台,以方便其他用户使用,那你可能就真正实现了一个类似于Hadoop的应用系统。用这样的思维去看待Hadoop可能会让用户理解的为更透彻,另外当用户对这个认识模糊时,大可以不用太担心,这多半是由于当前的实际工作可能还用不上,如果真碰到这样的大数据处理,通过思考就能很快理解Hadoop的好处。
(4)实现多节点的安装与部署,并尝试设置节点失效,看一下如何去管理与调度、监测任务的执行。
(5)实现大批量专用工具部署,并尝试实现1万个文件的存取、数千万数据的写入与查询,再去重新认识一下Hadoop。
(6)尝试在工作中开始实现Hadoop。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 3
3 0
0- 0


 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)