hadoop2.7.2 window win7 基础环境搭建
hadoop环境搭建相对麻烦,需要安装虚拟机过着cygwin什么的,所以通过查资料和摸索,在window上搭建了一个,不需要虚拟机和cygwin依赖,相对简便很多。下面运行步骤除了配置文件有部分改动,其他都是参照hadoop下载解压的share/doc/index.html。hadoop下载:http://apache.opencas.org/hadoop/common
hadoop环境搭建相对麻烦,需要安装虚拟机过着cygwin什么的,所以通过查资料和摸索,在window上搭建了一个,不需要虚拟机和cygwin依赖,相对简便很多。
下面运行步骤除了配置文件有部分改动,其他都是参照hadoop下载解压的share/doc/index.html。

hadoop下载:http://apache.opencas.org/hadoop/common/
解压至无空格目录下即可,下面是目录结构:
下面配置windows环境:
Java JDK :
我采用的是1.8的,配置JAVA_HOME,如果默认安装,会安装在C:\Program Files\Java\jdk1.8.0_51。此目录存在空格,启动hadoop时将报错,JAVA_HOME is incorrect ...此时需要将环境变量JAVA_HOME值修改为:C:\Progra~1\Java\jdk1.8.0_51,Program Files可以有Progra~代替。
Hadoop 环境变量:
新建HADOOP_HOME,指向hadoop解压目录,如:D:/hadoop。path环境变量中增加:%HADOOP_HOME%\bin;。
Hadoop 依赖库:
winutils相关,hadoop在windows上运行需要winutils支持和hadoop.dll等文件,下载地址:http://download.csdn.net/detail/fly_leopard/9503059
注意hadoop.dll等文件不要与hadoop冲突。为了不出现依赖性错误可以将hadoop.dll放到c:/windows/System32下一份。
hadoop环境测试:
起一个cmd窗口,起到hadoop/bin下,hadoop version,显示如下:

hadoop基本文件配置:hadoop配置文件位于:hadoop/etc/hadoop下
core-site.xml / hdfs-site.xml / mapred-site.xml / yarn-site.xml
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hadoop272/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hadoop272/data/dfs/datanode</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>格式化系统文件:
hadoop/bin下执行 hdfs namenode -format
待执行完毕即可,不要重复format。
格式化完成后到hadoop/sbin下执行 start-dfs启动hadoop
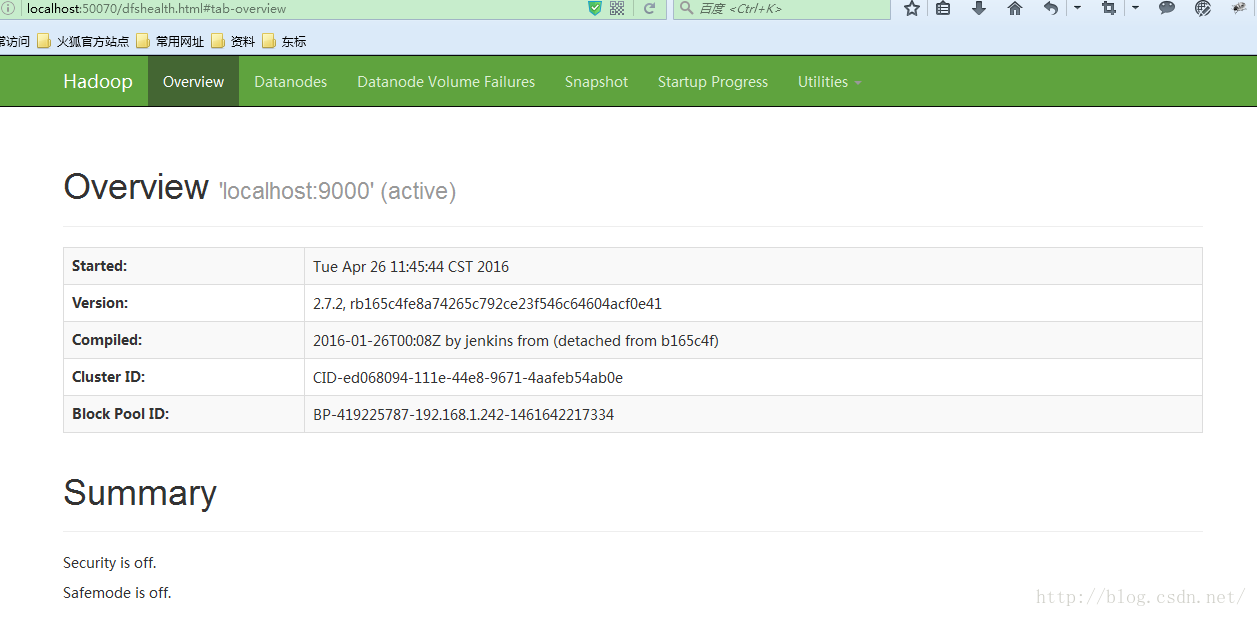
访问:http://localhost:50070
(不是必须的 ) 创建目录:用于输入和输出,linux上是/user/用户名/xx windows上可能没具体要求,我创建也是按照liunx目录方式的。参照的api doc上面
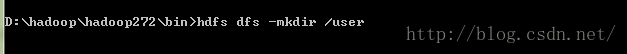

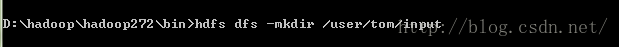

创建完成可以通过hdfs dfs-ls 目录名称查看,也可以在浏览器中查看创建的目录或文件
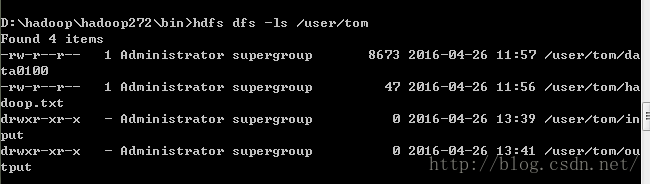
input输入文件到目录:login_weibo2是我自己创建的文本文件,位于hadoop一个盘的。此处是D:/hadoop/login_weibo2

如果了解命令参数输入hdfs dfs回车查看dfs命令参数 。hdfs dfs -put回车查看put相关参数。其他命令也是这样。
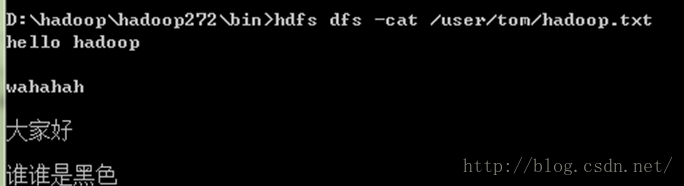
查看input输入的文件内容:
运行hadoop给的examples,做个参考,运行下面命令等待执行完成。hadoop jar jar文件位置 grep 输入目录(包含被处理文件的目录) 输出目录(运行结果输出目录)

然后查看文件夹下多了些东西,就是运行结果输出目录,结果般存在part-r-xxxx里面。

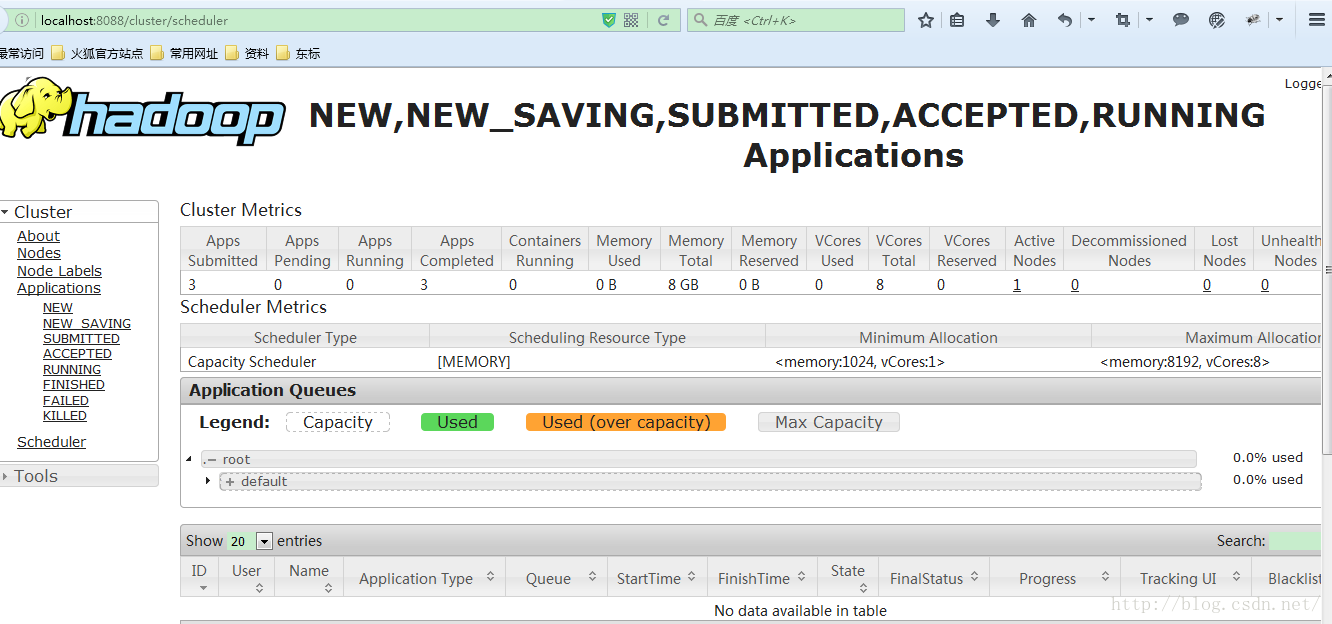
在hadoop/sbin下启动start-yarn,访问http://localhost:8088可查看 资源、节点管理
刚接触hadoop,什么都不是很了解,不对地方欢迎指正。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)