基于阿里云的数据仓库架构设计
文章目录基于阿里云的数据仓库架构(未完)产品对比离线数仓实时数仓基于阿里云的数据仓库架构(未完)产品对比阿里云产品同类产品简介RDSMySQL、PostgreSQL关系型数据库服务,是阿里提供的云数据库,有各种版本,例如MySQL版、PostgreSQL版、SQLServer版等DTSCanal、DataX、Sqoop、Flume数据传输服务,功能丰富,包.....................
·
基于阿里云的数据仓库架构设计
产品对比
| 阿里云产品 | 同类产品 | 简介 |
|---|---|---|
| RDS | MySQL、PostgreSQL | 关系型数据库服务,是阿里提供的云数据库,有各种版本,例如MySQL版、PostgreSQL版、SQLServer版等 |
| DTS | Canal、DataX、Sqoop、Flume | 数据传输服务,功能丰富,包括集数据迁移、数据订阅、数据实时同步的功能,适用于RDMS、NoSQL、大数据等产品 |
| DataHub | Kafka | 数据总线,主要功能和Kafka类似,但是有更多的接口、功能 |
| MaxCompute | Hadoop | 通用的离线计算平台(原名ODPS),支持SQL、MapReduce、UDF、Graph、Spark on MaxCompute等计算模型。调度系统是伏羲,存储系统是盘古 |
| RealtimeCompute | Spark、Flink | 实时计算框架(以前版本是StreamCompute),底层基于Blink |
| DataWorks | - | 可视化的一站式大数据工场,包括数据集成、开发、治理、服务、质量、安全等功能,具体地说就是方便你使用MaxCompute、RealtimeCompute |
| AnalyticDB | GreenPlum、LibrA | OLAP,分析型数据库,基于MPP架构,主要包括MySQL版、PostgreSQL版 |
| DataV | Tableau、PowerBI | 可视化数据展示工具,主要做大屏展示 |
| QuickBI | Tableau、PowerBI | 相较于DataV更为灵活,主要做数据分析,运营、分析师使用较多 |
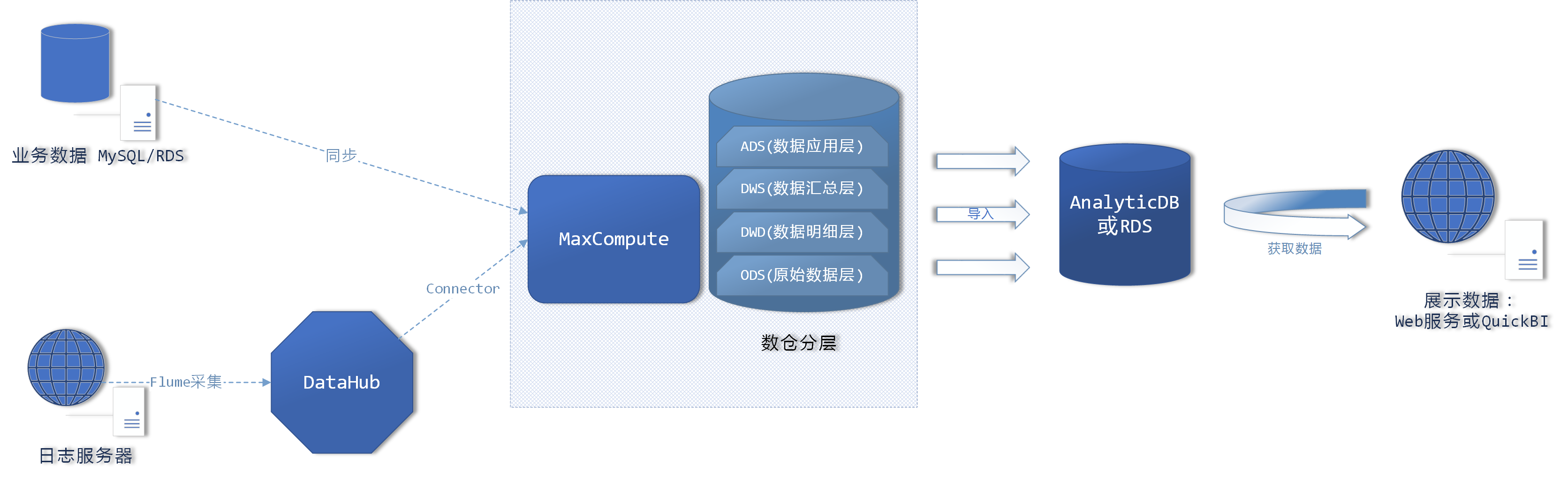
离线数仓
- 架构设计图

- 说明
- 原始数据主要来源于两部分
- 日志服务器产生的用户行为数据
- 业务数据库产生的数据
- 当然你还可以导入各种数据,例如网络爬虫的数据、数据市场购买的数据等等
- 数据导入部分
- 日志数据采用Flume进行导入DataHub既可(TailDirSource + MemoryChannel + DataHubSink)
- 业务数据直接利用MaxCompute同步进入平台即可
- 数据仓库建设部分,需要进行多层划分
- ODS(原始数据层)- 最原始的数据,只做最简单的格式检查,以及数据压缩
- DWD(数据明细层)- 数据明细层,开始进行维度建模,需要进行各种ETL清洗、抽取、拆分、降维,得到维度表、事实表。(注:如果需要复杂的即席分析,那么建议该层进入OLAP库)
- DWS(数据汇总层)- 针对明细层的数据做一个轻度聚合,进行各种统计指标的初步汇总,方便后面应用层直接使用
- DWT(数据主题层)- 不同部门或业务的数据作为一个主题(数据量较少时一般不需要分Topic)
- ADS(数据应用层)- 应用层是最终的数据结果,包括最终需要的各类指标,还需要导入到关系型数据库中,方便Web端查询
- 分析用数据库
- 此部分可选用AnalyticDB、RDS或自建关系型库,都可以,主要是为了方便后续系统查询
- 如果数据量不大,分析量小,直接采用RDS或自建关系型库即可
- 如果因业务需求需要进行大量变化的数据分析(OLAP),那么建议使用AnalyticDB
- 数据展示部分
- 根据需求选择阿里的QuickBI或自行定制化设计Web数据展示界面均可
- 原始数据主要来源于两部分
- 注意:Lambda架构的话,还需要加入实时指标统计
实时数仓
- 架构设计图

- 说明
- 原始数据主要来源于两部分
- 日志服务器产生的用户行为数据
- 业务数据库产生的数据
- 数据导入部分
- 日志数据采用Flume进行导入DataHub既可(TailDirSource + MemoryChannel + DataHubSink)
- 业务数据需要利用DTS实时导入到DataHub
- 数据仓库建设部分(使用Kappa架构,传统Lambda架构的两条链路缩减为一条,降低了维护成本,但出问题难以处理)
- 原始数据先进入到DataHub,接着由RealtimeCompute进行清洗、关联,得到实时明细数据
- 实时明细数据进入到DataHub,接着由RealtimeCompute进行轻度、高度聚合,得到实时汇总数据
- 实时汇总数据进入到DataHub(也可以直接进入到分析库中),再导入到AnalyticDB
- 注意:如果需要非常高的实时度,那么建议不分层,直接处理得到轻度、高度聚合结果,进入AnalyticDB
- 分析用数据库(建议同离线部分,更推荐AnalyticDB)
- 此部分库从前面DataHub得到了汇总数据
- 接着可以在内部进行指标统计生成应用层数据,直接展示即可
- 或是交由后续服务应用自行调用分析(适用于各种经常变化的分析情况)
- 注:如果需要复杂的即席分析,那么建议DWD层(明细数据)进入OLAP库(例如AnalyticDB)
- 此部分库从前面DataHub得到了汇总数据
- 数据展示部分
- 此部分同离线数仓,不过通常实时部分都是做的大屏展示,包含各类统计指标,可以直接使用阿里的DataV
- 原始数据主要来源于两部分
数仓规范
-
数仓分层规范
分层 概念 说明 ODS(Operational Data Store) 原始数据层 原始数据,格式基本不变,只做少量的校验 DWD(Data Warehouse Detail) 数据明细层 维度建模,数据的标准化、补齐、清洗、拆分、降维等 DWS(Data Warehouse Summary) 数据汇总层 数据轻度聚合,提高复用性 DWT(Data Warehouse Topic) 数据主题层 不同部门或业务的数据作为一个主题(数据量较少时一般不需要分Topic) ADS(Application Data Store) 数据应用层 最终应用展示指标 -
表命名规范(按下划线拼接)
数仓分层 业务 描述 时间周期/存储方式 dwd tmall user_base_info day dwd tmall user_login_info day dws tmall active_user week ads tmall user_retention_rate week ads tmall user_convert month ads tmall page_view day - 举例: dwd_tmall_user_base_info_day
- 举例: dwd_tmall_user_base_info_1d
- 举例: dws_tmall_active_user_7d
-
数据压缩、存储格式的建议
分层 压缩 格式 说明 ODS LZO/Snappy parquet、orc、avro 原始数据较大,并且不会被经常使用,较高的压缩率能够很好的节省空间。同时因为数据会被计算框架处理,因此压缩的格式最好是能被切块的,例如LZO。存储格式方面,需根据后续的处理方式选择,通常选择HIVE中最常用的orc。 DWD LZO/Snappy parquet、orc 明细层通常数据也会较多,因此也需要一个较高的压缩率。并且也会经常被计算框架处理,所以还是需要一个可以切片的压缩格式,例如LZO。由于下一层是汇总层,通常会对该层进行聚合操作,因此采用列式存储能够有效的提高聚合处理的性能,例如orc。 DWS 无 无、parquet、orc 汇总层已经是轻度聚合后的数据,会比前面的层少很多数据,同时考虑ADS层会经常从该层统计指标,因此不压缩是一个较好的选择。存储格式方面可以按普通格式,也可以继续使用列式存储,因为ADS层通常还会对DWS的数据进行聚合。 ADS 无 无 ADS层的数据用于最后界面的指标展示,是最终的数据,数据量较少,因此完全可以不用压缩。格式方面无所谓,如果要强调性能的话,不建议采用列式存储。因为该层通常都是全量读取到关系型库用作展示,几乎不会涉及到聚合操作,并且数据量少不需要减少空间占用,列式存储的优势全无。列式存储反而还需要更多的解析时间。 - 推荐:小表用 ORC + Snappy,大表用 Parquet + LZO
-
维度建模 的四个步骤
- 选择业务过程:选择要做什么业务的分析,例如支付业务、物流业务、销售业务等
- 明确粒度:明确本业务每条数据的最小粒度,例如条、天、周、月等
- 确认维度:确认需要从业务的哪些维度进行分析,例如销售区域的维度、商品分类的维度等
- 确认事实:确认对于不同维度的数据需要进行什么样的计算,也就是度量,例如计数、求平均值、求和等等

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)