Apache Kylin 深入Cube和查询优化
作者:李栋,Kyligence Inc技术合伙人兼高级软件架构师,Apache Kylin Committer & PMC Member,专注于大数据技术研发,KyBot技术负责人。毕业于上海交通大学计算机系;曾任eBay全球分析基础架构部高级工程师、微软云计算和企业产品部软件开发工程师;曾是微软商业产品Dynamics亚太团队核心成员,参与开发了新一代基于云端的ERP解决方案。近
作者:李栋,Kyligence Inc技术合伙人兼高级软件架构师,Apache Kylin Committer & PMC Member,专注于大数据技术研发,KyBot技术负责人。毕业于上海交通大学计算机系;曾任eBay全球分析基础架构部高级工程师、微软云计算和企业产品部软件开发工程师;曾是微软商业产品Dynamics亚太团队核心成员,参与开发了新一代基于云端的ERP解决方案。
近几年,Apache Kylin作为一个高速的开源分布式大数据查询引擎正在迅速崛起。它充分发挥Hadoop、Spark、HBase等技术的优势,通过对超大规模数据集进行预计算,实现秒级甚至亚秒级的查询响应时间,同时提供标准SQL接口。目前,Apache Kylin已在全球范围得到了广泛应用,如百度、美团、今日头条、eBay等,支撑着单个业务上万亿规模的数据查询业务。在超高性能的背后,Cube是至关重要的核心。一个优化得当的Cube既能满足高速查询的需要,又能节省集群资源。本文将从多个方面入手,介绍如何通过优化Cube提升系统性能。
Cube基本原理
在传统多维分析就有多维立方体(OLAP Cube)的概念。Apache Kylin在大数据领域对Cube进行了扩展,通过执行 MapReduce/Spark任务构建Cube,对业务所需的维度组合和度量进行预聚合,当查询到达时直接访问预计算聚合结果,省去对大数据的扫描和运算,这就是Apache Kylin高性能查询的基本实现原理。
如图1所示,Apache Kylin会对SQL的查询计划进行改写,把源表扫描、多表连接、指标聚合等在线计算转换成对预计算结果的读取,极大减少了在线计算和I/O读写的代价。 而查询所访问的预计算结果保存在Cuboid当中(见图1红色方框),Cuboid大小只和维度列的基数有关,和源数据行数无关,这使得查询的时间复杂度可以取得一个量级的提升。
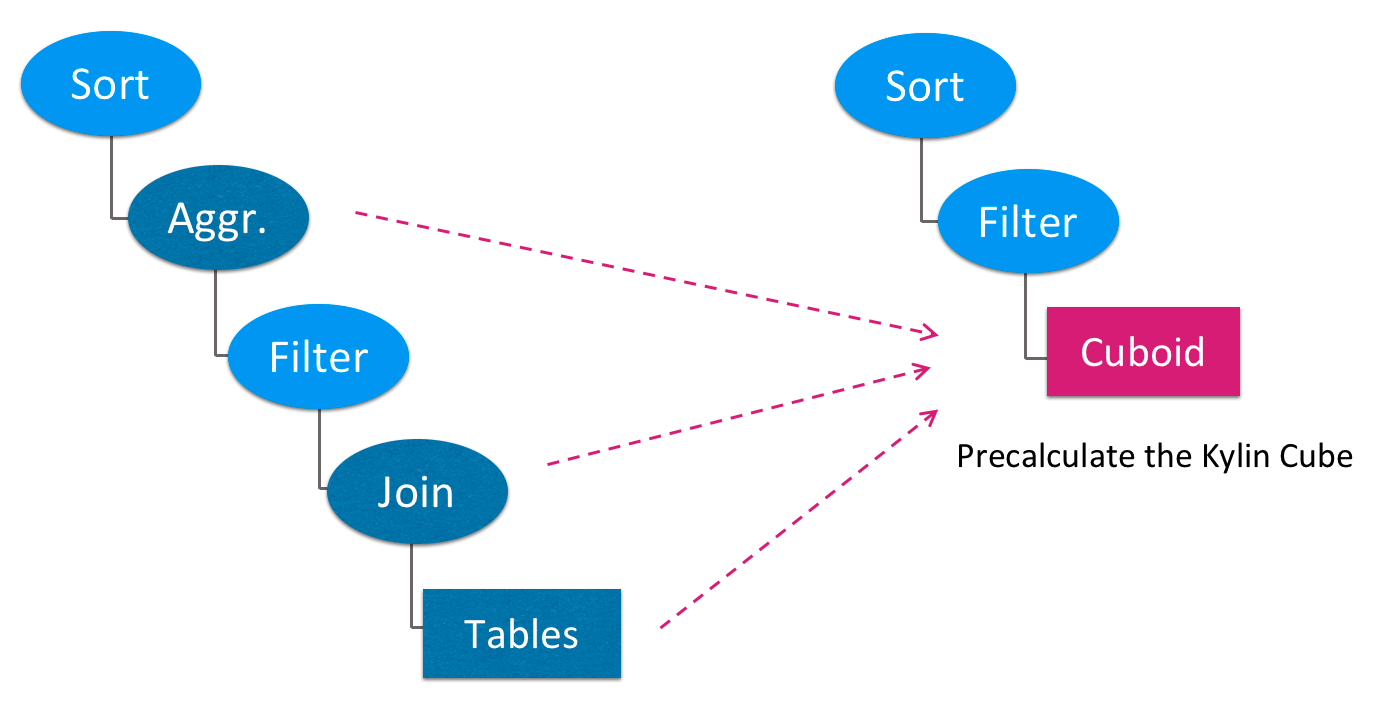
图 - 1预计算查询计划
一个Cuboid对应着一组分析的维度,并保存了度量的聚合结果。Cube就是所有Cuboid的集合,如图2所示,每个节点代表一个Cuboid。当查询到达,Apache Kylin会根据SQL所使用的维度列在Cube中选择最合适的Cuboid,最大程度地节省查询时间。
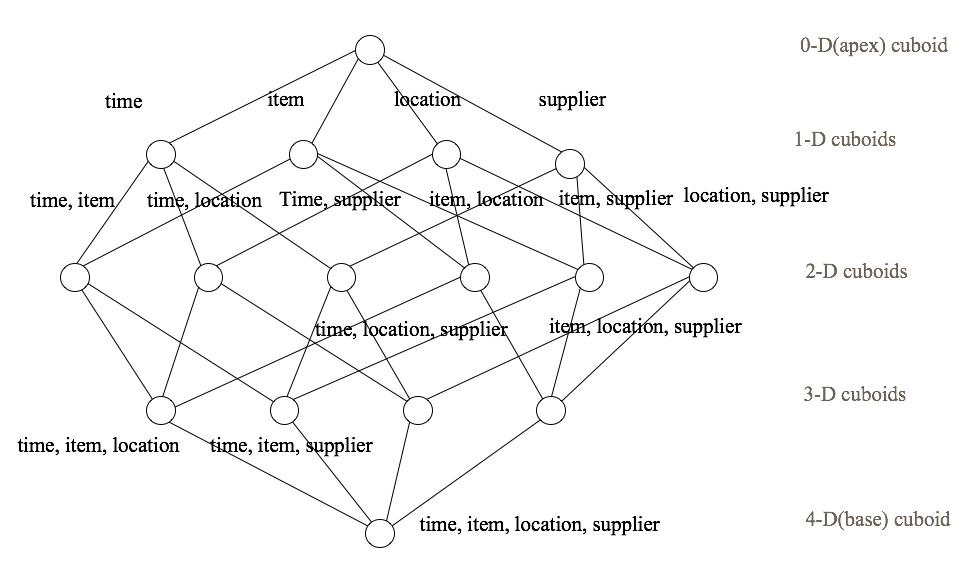
图 - 2 Cube示意图
Cube优化案例
社区不乏一些使用Apache Kylin的成功案例分享,但经常还会看到很多朋友遇到性能问题,例如SQL查询过慢、Cube构建时间过长甚至失败、Cube膨胀率过高等等。究其原因,大多数问题都是由于Cube设计不当造成的。因此,合理地进行Cube优化就显得尤为重要。
这里先分享两个社区用户进行优化的案例:
案例1 – 提升Cube查询效率
背景:某智能硬件企业使用Apache Kylin作为大数据平台查询引擎,对查询性能有较高要求,希望提高查询效率。
数据:
- 9个维度,其中1个维度基数是千万级,1个维度基数是百万级,其他维度基数是10w以内
- 单月原始数据6亿条
优化方案:
- 数据清理:将时间戳字段转换成日期,降低维度的基数
- 调整聚合组:不会同时在查询中出现的维度分别包含在不同聚合组(如崩溃时间、上传时间等)
- 设置必须维度:把某些超低基数维度设为必须维度
优化成果:
- 查询性能:提升5倍
- 构建时间:缩短30%
- Cube大小:减小74%
案例二 – 提升Cube构建效率
背景:某金融企业使用Apache Kylin作为报表分析引擎,发现Cube膨胀率多大、构建时间过长,希望对这一情况进行改善。
硬件:20台高配置PC服务器
数据:事实表有100多万条记录,度量是某些列的平均值
优化方案:
- 维度精简:去除查询中不会出现的维度
- 调整聚合组:设置多个聚合组,每个聚合组内设置多组联合维度
优化成果:
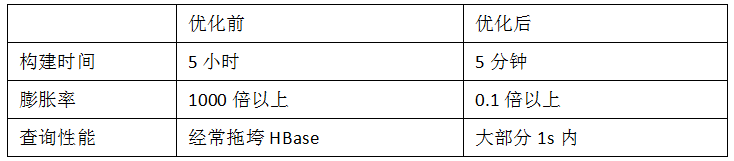
Cube优化原理
从以上案例可以看出,通过Cube调优可以显著改善Apache Kylin的构建性能、查询性能及Cube膨胀率。那么这些改进的背后究竟是什么原理呢?
为了深入理解Cube,首先要先了解Cuboid生成树。如图3所示,在Cube中,所有的Cuboid组成一个树形结构,根节点是全维度的Base Cuboid,再依次逐层聚合掉每个维度生成子Cuboid,直到出现0个维度时结束。图3中绿色部分就是一条完整的Cuboid生成路径。预计算的过程实际就是按照这个流程构建所有的Cuboid。
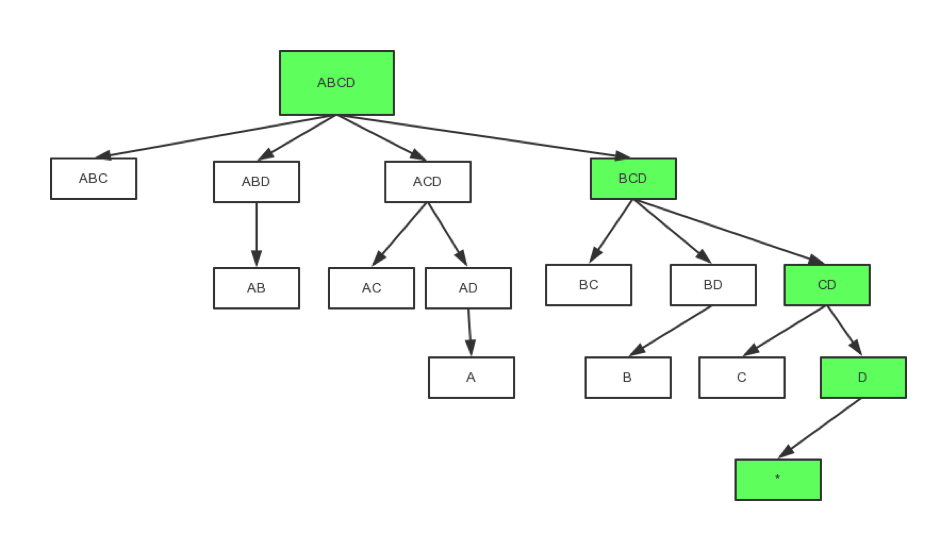
图 - 3 Cuboid生成树
通过这颗Cuboid生成树,我们不难发现:当维度数量过多,就会导致Cuboid数量以指数级膨胀;如果维度基数过大,还会使所在的Cuboid结果集变大。这些都是影响Cube膨胀率和构建时间的重要因素。
但是,所有的Cuboid都是必要的吗?实际上,在多数情况下,我们并不需要这里的每一个Cuboid,因此需要对Cuboid生成树做剪枝。剪枝可以从两个方面入手:数据特性、查询需求。首先介绍数据特性,考虑下图的两个Cuboid,左侧Cuboid包含4个维度(ABCD),右侧Cuboid包含3个维度(ABC),而两个Cuboid都包含相同(或极度相近)行数的记录,说明读取两个Cuboid结果的代价是一样的,同时左侧Cuboid除了具有右侧Cuboid的查询支持能力外,还能支持带有维度D的查询,因此右侧Cuboid就可以被去除。
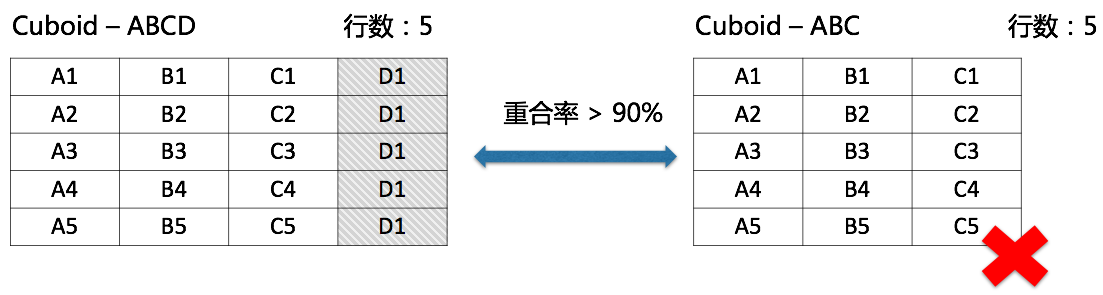
图 - 4 去除冗余Cuboid
再考虑查询需求,在报表或多维分析场景中,有些维度是每次查询都会出现的,如年份;有些维度总是一起出现的,如开始时间、结束时间;有些维度间是有层级关系的,如商品分类或地理信息。充分利用查询的这些实际需求也能去除不需要的Cuboid,例如:如果年份是必要的,那么所有不包含年份维度的Cuboid都可以被去除;如果两个维度总是同时出现,那么这这些维度单独出现的Cuboid就可以被去除。
在Apache Kylin中,可以通过设置Cube的维度组合规则来去除无用的Cuboid。首先,可以通过定义聚合组对维度分组,只在每个聚合组内生成Cuboid。此外,在单个聚合组内部,还可以设置维度组合规则,如:必须维度用于定义一定出现的维度、联合维度用于定义一组同时出现的维度、层级维度用于定义一组有层级关系的维度,详细的Cuboid生成规则如下图所示:
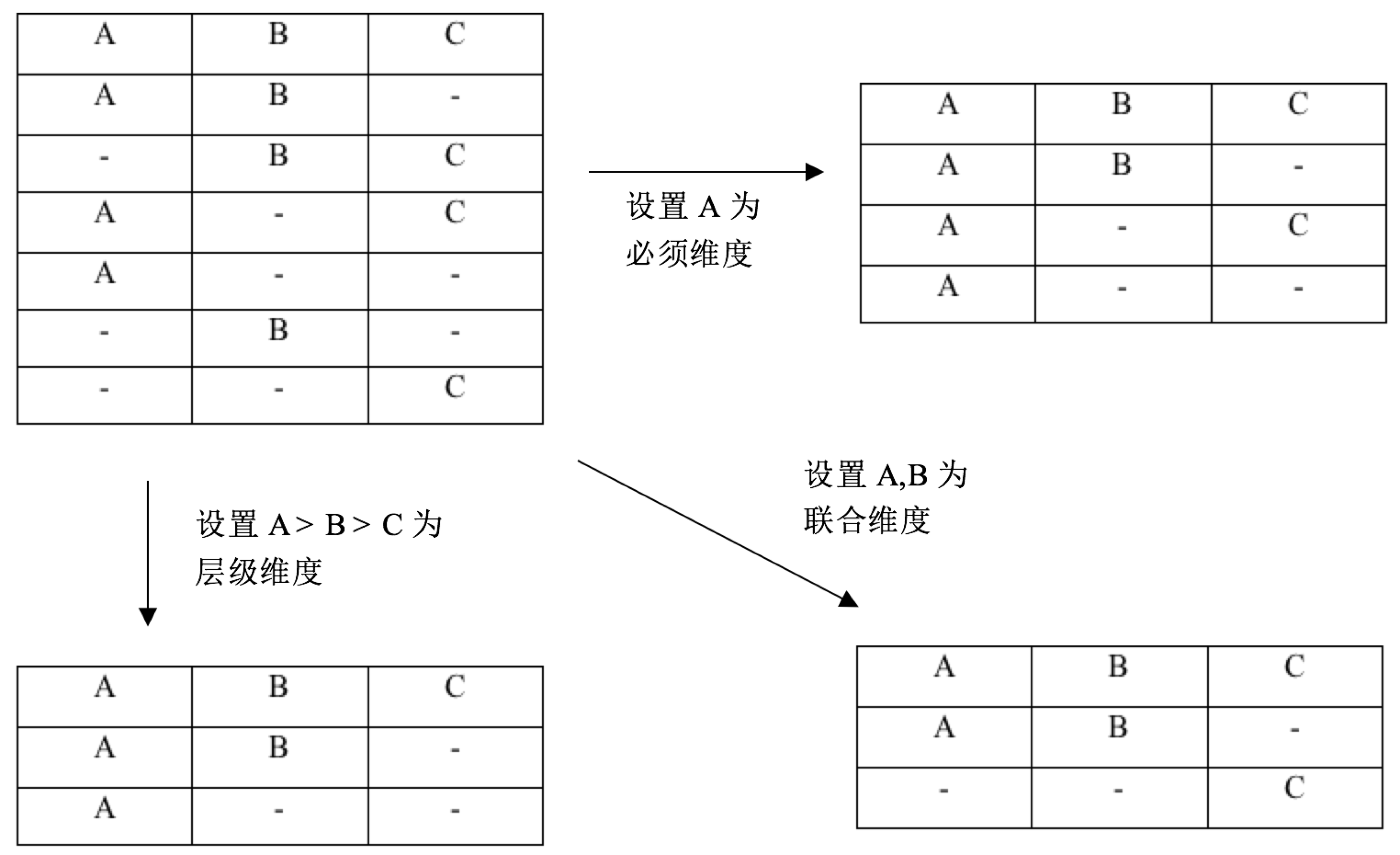
图 - 5聚合组规则
Cube优化工具
上文介绍了Cube设计和优化的基本原理,但是如何实践是一个比较有挑战的事情,需要操作者对这些原理的实现细节、数据特性、查询需求都有较深理解。所谓工欲善其事,必先利其器。这里介绍一个Cube优化的神器KyBot(https://kybot.io),可以通过可视化手段展现Apache Kylin中的各项统计指标,并进行智能化评分及规则,有助于快速定位查询、构建瓶颈和寻找解决方案。
KyBot的使用也十分简单,只需要简单上传包含日志的诊断包,后台会自动对诊断包中的查询、构建日志等历史进行分析,挖掘可能的Cube设计缺陷,通过可视化页面直观地展现出来。如果希望对日志中的敏感信息(如IP地址等)进行脱敏保护,也可以简单解决。
图 - 6 KyBot网站
寻找Cube设计缺陷
当KyBot分析完成,在Cube仪表盘上就能看到Cube的诊断结果了,包括Cube评分、Cube排行、Cube详情等。图7的雷达图展示的就是所有Cube的整体评分,包含查询性能、构建性能、膨胀倍数、使用率、模型设计等5个维度。通过这个评分,就可以一眼对整个Apache Kylin的性能体现有一个直观认识,也可以直观地看出Cube优化的重要性和必要性。例如在这个例子中可以看出,虽然整体的查询、构建性能较好,但模型设计依然有很大提升的空间。

图 - 7 Cube总体评分雷达图
了解整体性能之后,还需要进一步缩小范围寻找可优化的Cube,通过图8的Cube排行就可以。图中从膨胀倍数、查询次数、慢查询次数对Cube进行了排名,排在首位的就是在这一排名中最需要优化的Cube,例如,膨胀倍数排名第一个Cube的膨胀倍数远远高于其他Cube,说明有巨大的优化空间,如果对数据存储或构建时间有要求,就可以先从这个Cube入手进行优化。同样的,如果对查询效率有要求,就可以从慢查询次数排行入手。
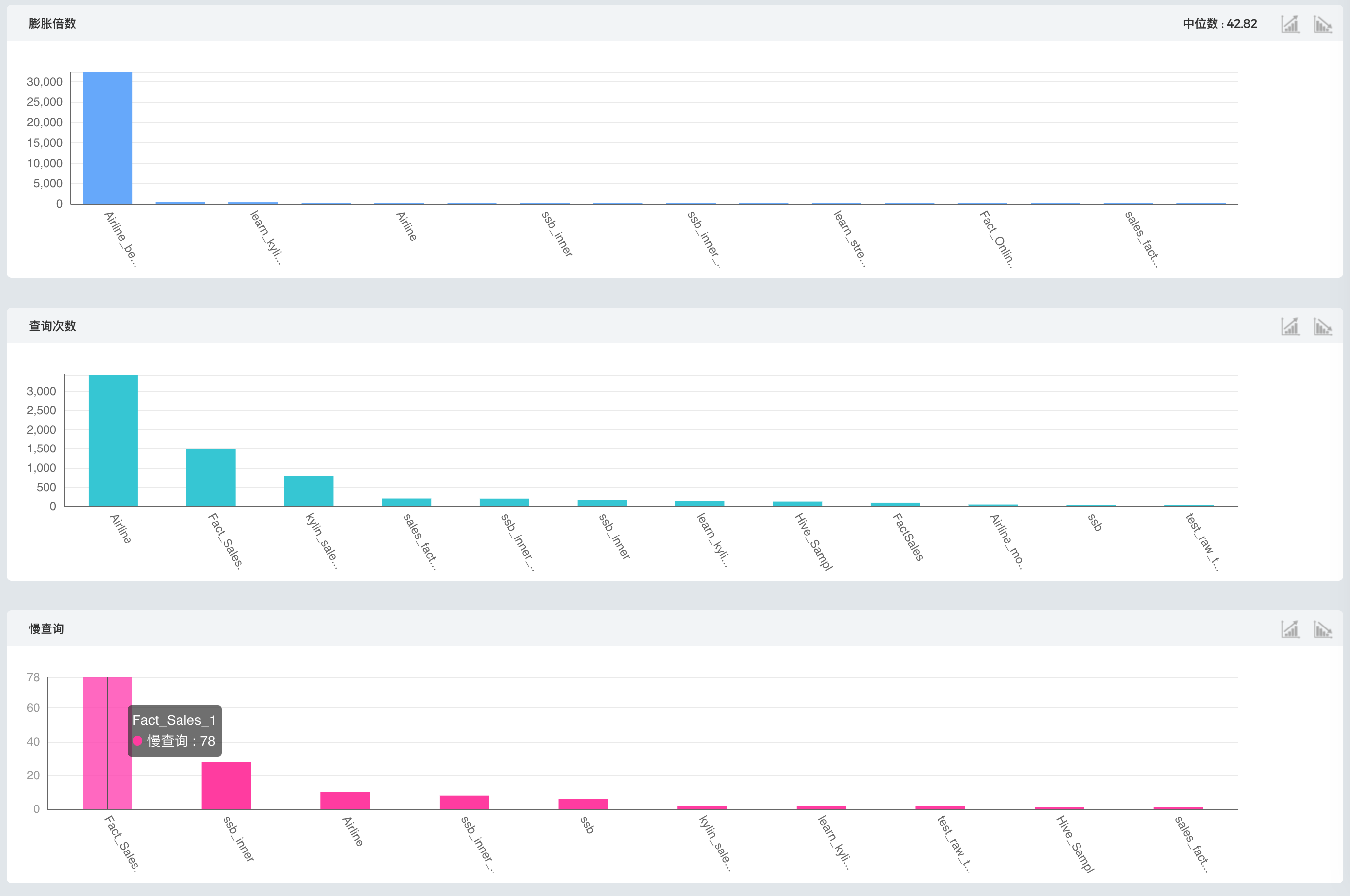
图 - 8 Cube排行
锁定了优化目标,单击这个Cube的柱状图查看Cube详情,如图9所示。图中1区域是当前Cube的评分,可以直观看出Cube在模型设计和查询性能方面有缺陷,其中模型设计的优劣来自对Cuboid重合率和查询匹配度的统计。评分下方的柱状图显示Cuboid重合率排名,Cuboid重合率代表一个Cuboid和他父节点Cuboid行数的比例,如果重合率接近100%,根据上文“Cuboid优化原理”一节,这个Cuboid是可以被去除的。根据图中的例子,有800多个Cuboid重合率高于90%,都是可以被去除的。
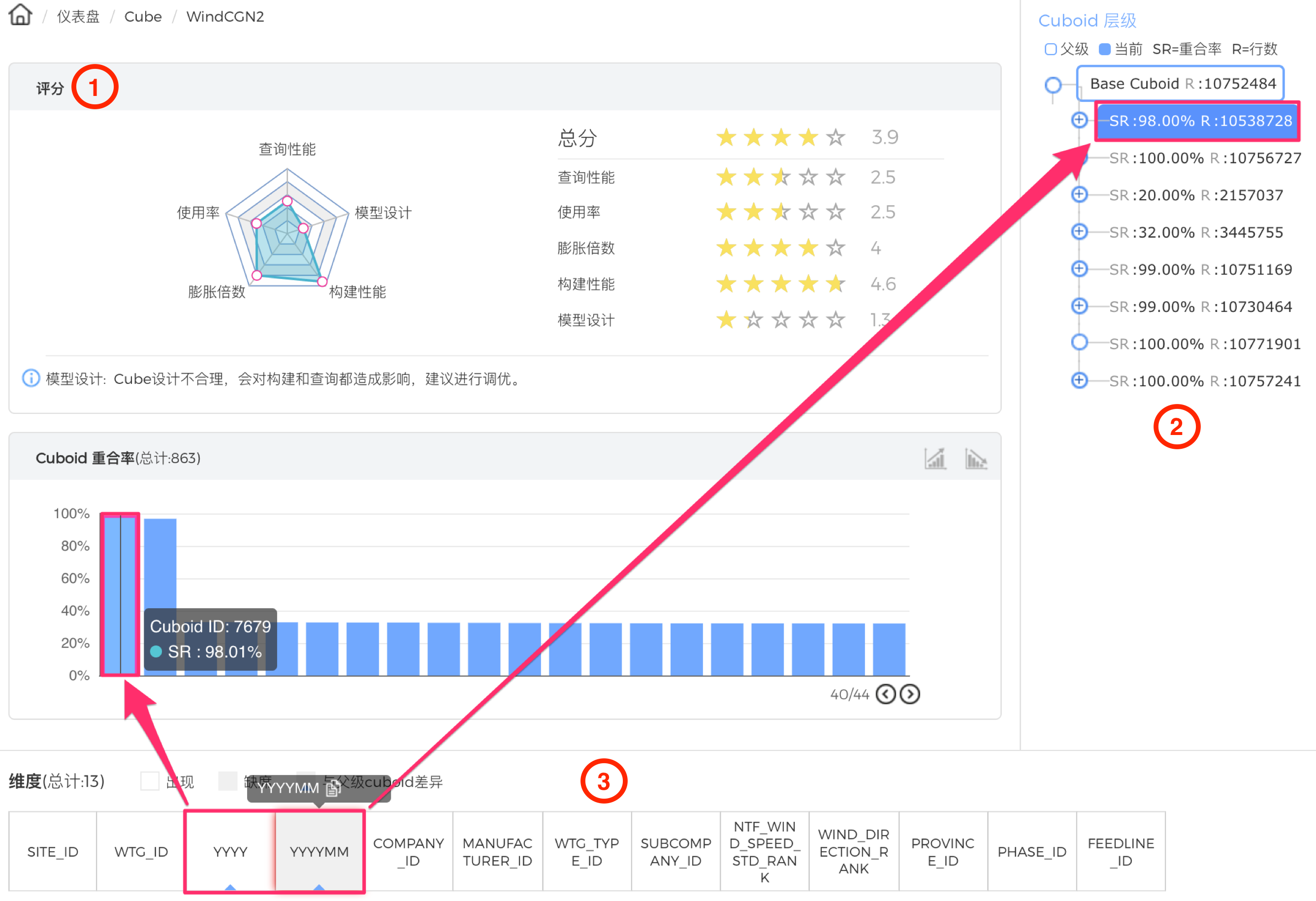
图 - 9 Cube调优
接下来进入实际操刀环节,先来看模型设计的问题。图中2区域是Cuboid层级的树状图,在根节点(Base Cuboid)的8个子节点里,发现有6个节点的重合率超过了98%,且行数超过了1千万,说明这些Cuboid即使比父Cuboid相比少了一个维度,但依然没有减少结果集数量,换句话说,少掉的这个维度收缩力较弱,原因可能是因为这个维度基数较低,或者Cuboid中包含超高基数的维度。通过单击第一个子Cuboid,在区域3查看各个维度的详细信息,不难发现,该Cuboid并没有超高基数维度,而和父级Cuboid差异的维度YYYYMM基数很低。虽然YYYY和YYYYMM两列已是层级维度,但两个维度的基数均很低。同理,发现CATA1_ID和CATA2_ID的组合也是如此,如下图所示。鉴于YYYY、YYYYMM、CATA1_ID、CATA2_ID这4个维度的收缩力较弱,可以合并成一个联合维度。
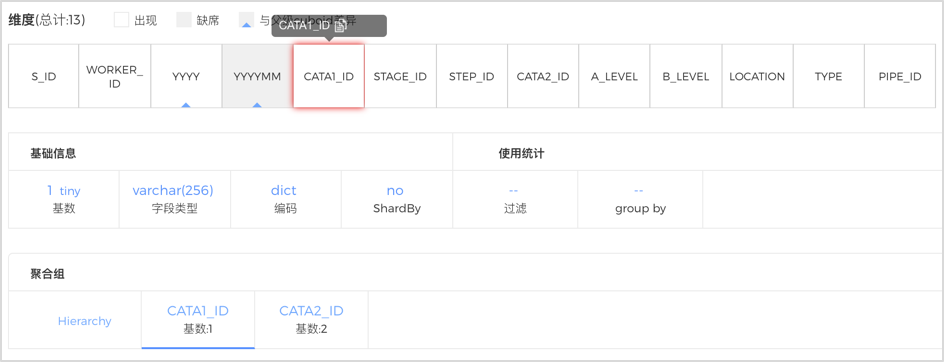
图 - 10 Cube维度信息
此外,还有多个基数较低的维度(LOCATION、TYPE、PIPE_ID)也有收缩力较弱的问题,也应合并成一组联合维度。这样,如下图所示,由于联合维度的引入使Cuboid数从28减小到25,有效地降低了Cube膨胀率、提升构建性能,同时又不影响查询性能。

图 - 11 设置联合维度
最后来看查询效率的问题。如下图所示,发现这个Cube中有一个维度WORKER_ID基数在1300以上,且被设为必须维度。但是在使用统计中看到,这个维度并没有被SQL用到过,这些SQL本身可以访问一个体量较小的Cuboid,但由于WORKER_ID被设为必须维度,所有的Cuboid都会包含这个1300+基数的维度,导致所有Cuboid记录数膨胀,造成查询性能普遍较差。因此,取消这一维度的必须维度设置,势必能够大大提升Cube的查询性能。
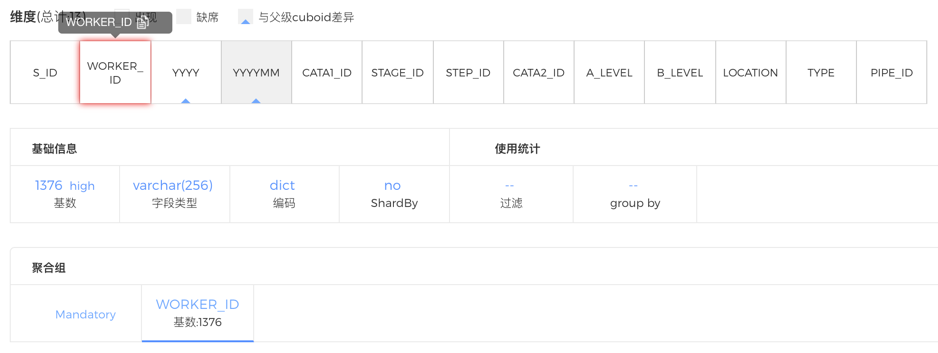
图 - 12 去除不恰当的必须维度
寻找Cube构建瓶颈
在Apache Kylin中,Cube的构建是通过一系列MapReduce和Spark任务完成的,其中MapReduce占多数。在KyBot上也可以看到Cube构建任务的可视化过程,如下图所示,就是一个Cube构建的生命周期,其中每一条绿色泳道代表了构建任务的一个步骤,泳道最长的一步说明耗时最大,如果要优化,就可以首先研究这一步。
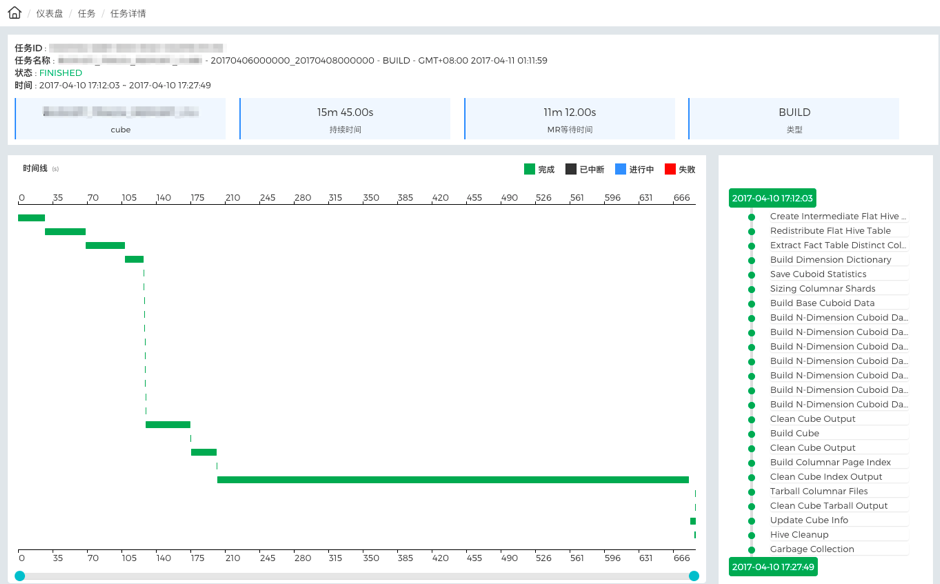
图 - 13 Cube构建生命周期
如果上传了这个任务的任务诊断包,还可以继续查看每一个MapReduce步骤的可视化过程。单击这个耗时最久的泳道,就会打开下图所示的MapReduce生命周期,在这个例子中,我们发现同一时间只有一个Task在运行,第一个task开始前还有较长的等待时间,说明集群资源可能较为紧张。如要优化,建议检查集群资源配置和调度。
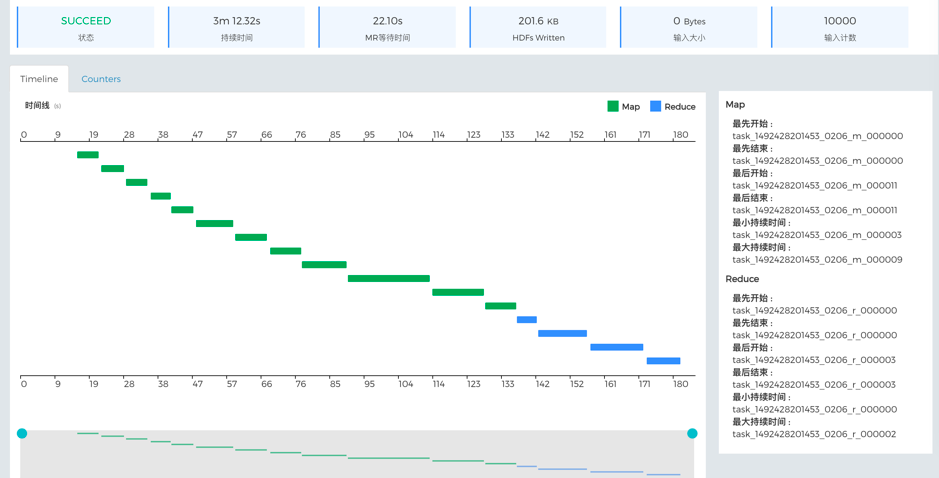
图 - 14 MapReduce任务生命周期
寻找查询瓶颈
查询是Apache Kylin的强项,但也存在种种因素导致某些查询变慢。查询性能一般通过整体的性能、并发统计数据来体现,KyBot的查询仪表盘可以直观展现不同维度的查询统计信息。如下图所示,这里可以看到查询响应时间的90百分位和95百分位、不同响应时间分布、每日性能变化等,用于直观把握查询性能的整体表现;下方的查询次数、人均查询次数、每日查询次数等直观展现Apache Kylin作为查询服务的使用率和并发数。
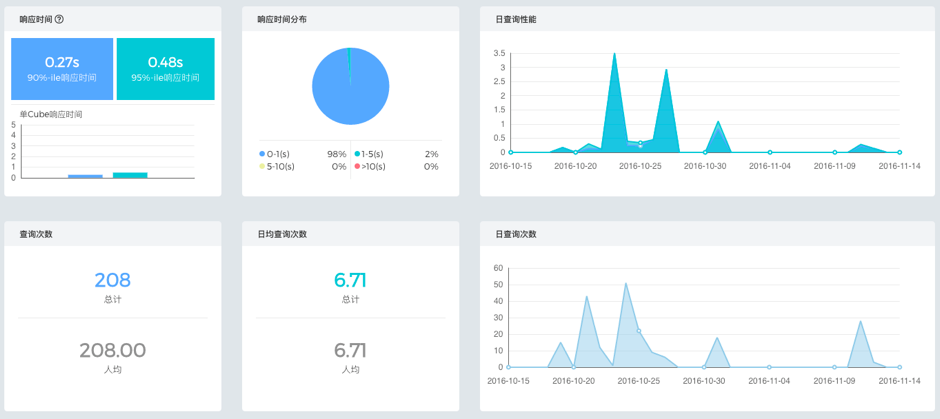
图 - 15 查询统计图
为了提升Apache Kylin的查询性能,首先要定位慢查询。查询仪表盘下方的查询明细列表中可以看到慢查询列表,并从这里进入一个查询的详情页面,如下图所示:
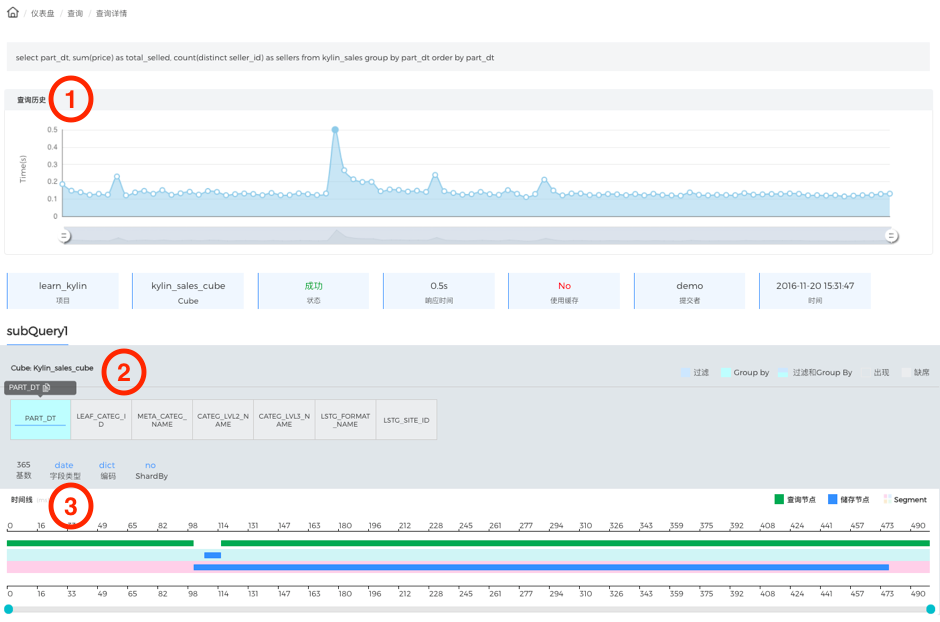
图 - 16 查询详情页
在查询的详情页,区域1是该查询的历史执行记录,通过单击图中的空心圆圈可以定位到某次查询记录。区域2是该查询击中的Cuboid及Rowkey的使用情况,绿色代表这个Rowkey作为查询的过滤条件,蓝色代表Rowkey作为查询的GROUP BY字段,白色代表出现在Cuboid上但没被查询用到的Rowkey。因为Apache Kylin使用HBase作存储引擎,所以参与过滤的Rowkey排在Cuboid前面会对查询性能有帮助。因此,蓝绿颜色的顺序就显得尤为重要了。图17是一个需要优化的查询例子,绿色Rowkey在末尾,可能影响HBase过滤的效率;中间有6个白色Rowkey,是因为这个6个维度被设为了必须维度,其中还有4个是高基数维度,会带来较高的存储扫描和在线计算代价,影响查询的效率。优化方案是取消必须维度的设置或改用联合维度。

图 - 17 待优化查询(1)
图16的区域3是该查询执行的生命周期,其中绿色泳道代表Apache Kylin查询节点的线程,蓝色泳道代表HBase节点的执行线程。图18是一个需要优化的例子,图中两条蓝色泳道长度区别很大,是由于数据切分Region不平衡导致不同Region Server负载差异较大。因此可以通过设置Shard By字段或调整Region切分相关的参数来加速查询。

图 - 18待优化查询(2)
总结
本文着重介绍了Apache Kylin中对Cube和查询进行优化的原理、工具、方案和案例,希望能够帮助使用Apache Kylin的朋友解决工作上的棘手问题。查询需求可能随着业务发展而不断变化,而Cube优化就是不断保证Cube性能的有效手段。为了更加高效地完成调优,使用KyBot是一个最简单的方式,未来的KyBot也会更加自动化和智能化。最后,希望“麒麟神兽”在每一片大数据草原上都能施展最大的威力!
更多精彩,欢迎关注CSDN大数据公众号!


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)