使用 Docker 搭建 Hadoop 分布式环境
对大数据初学者来说,直接用多台物理机搭建Hadoop集群是一个相当痛苦的过程,大多情况下还没开始跑wordcount,可能就被环境搭建劝退了。除了物理机,虚拟机搭建也是一种常见的方式,但这对宿主机也有着很大的性能要求。本文的目标是将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。快来学习吧 ~...
01 安装 Docker
Ubuntu 中安装 Docker 参考 :Docker 安装部署与基础操作
Windows 10 安装 Docker Desktop for Windows
Docker Desktop for Windows 支持 64 位版本的 Windows 10 Pro,且必须开启 Hyper-V(若版本为 v1903 及以上则无需开启 Hyper-V),或者 64 位版本的 Windows 10 Home v1903 及以上版本。
Docker Desktop 安装非常方便,手动下载安装包 下载地址 ,然后直接点击 Docker Desktop Installer.exe 文件安装即可。
安装报错
如果 Docker Desktop 安装过程中出现如下错误:

直接点击报错信息中的链接,更新 Linux 内核即可,
点击链接后进入如下页面

下载这个 WSL2 Linux kernel update package for x64 machines 升级包,并安装之后点击 Docker desktop 安装报错提示框中的 Restart,就能顺利安装完成并启动了。
启动运行 Docker
安装完成之后,桌面可以看到 Docker desktop 快捷方式,双击启动,启动成功之后会在 Windows 任务栏出现如下图的鲸鱼图标。

这时就可以在 PowerShell 使用 Docker 命令使用 Docker 了

国内镜像加速
国内从 Docker Hub 拉取镜像有时会遇到困难,此时需要配置国内镜像源进行加速
Windows 安装的 Docker Desktop 配置十分简单,只需要在任务栏托盘 Docker 图标内右键菜单选择 Settings,打开配置窗口后在左侧导航菜单选择 Docker Engine,在右侧像下边一样编辑 json 文件,之后点击 Apply & Restart 保存后 Docker 就会重启并应用配置的镜像地址了。
{
"registry-mirrors": [
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
]
}
配置完成之后,在 PowerShell 使用 docker info 命令,如果控制台输出如下内容,说明配置成功
Registry Mirrors:
https://hub-mirror.c.163.com/
02 下载 Hadoop 镜像
创建 Hadoop 容器我们需要合适的 Hadoop 镜像,这里我们使用 Github 上高赞的 docker-hadoop 镜像,使用如下命令将镜像克隆到本地
git clone https://github.com/big-data-europe/docker-hadoop.git
然后进入到 docker-hadoop 目录下运行
docker-compose up -d
下载 hadoop 镜像并创建容器。

该命令执行完成之后使用 docker container ls 命令查看被启动的容器,我们可以看到如下 5 个节点

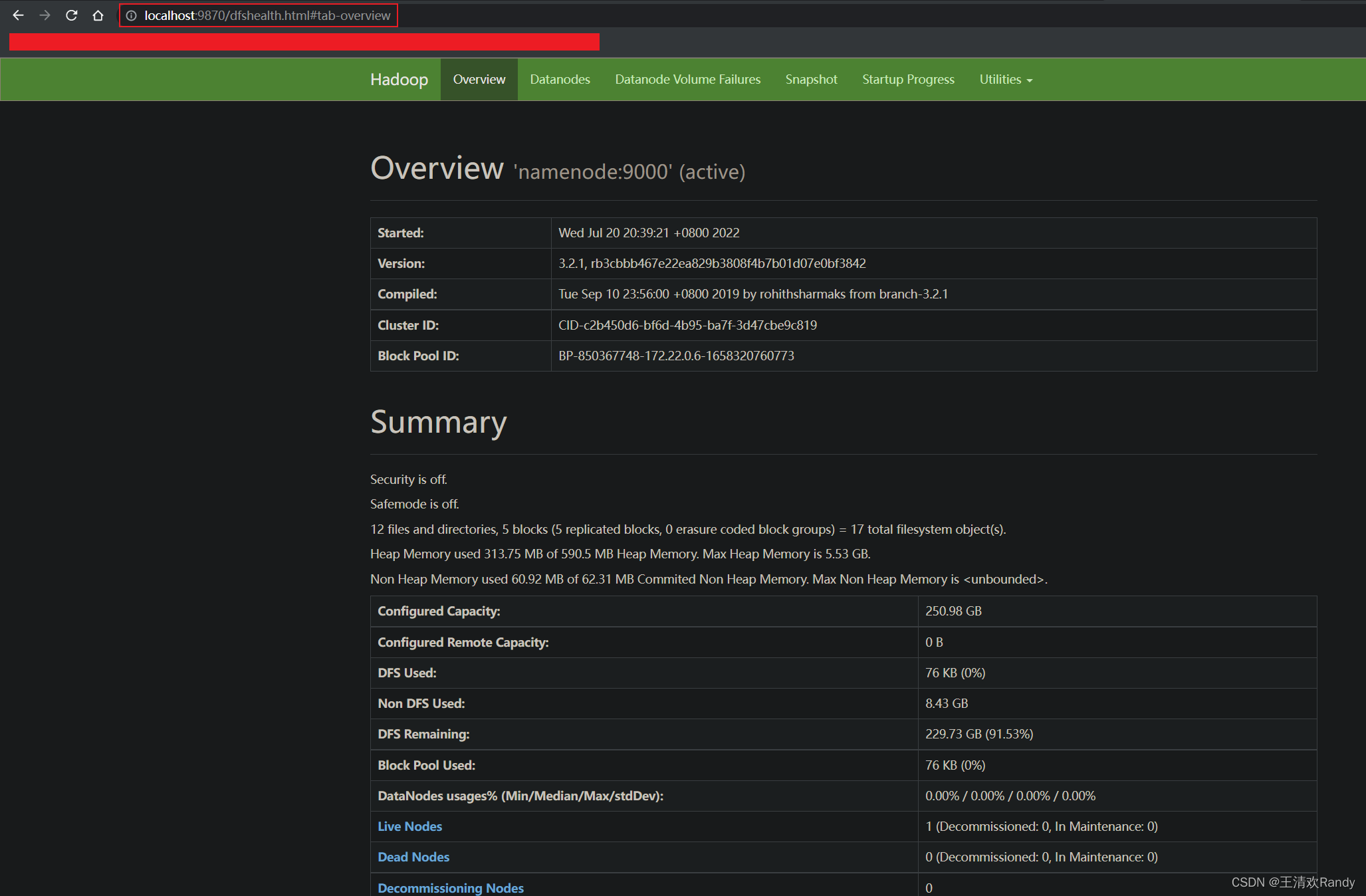
Hadoop 集群被成功启动后,可以通过如下 URL 访问各节点
Namenode: http://<dockerhadoop_IP_address>:9870/dfshealth.html#tab-overview
History server: http://<dockerhadoop_IP_address>:8188/applicationhistory
Datanode: http://<dockerhadoop_IP_address>:9864/
Nodemanager: http://<dockerhadoop_IP_address>:8042/node
Resource manager: http://<dockerhadoop_IP_address>:8088/
通过浏览器访问 Namenode 可以看到如下 Hadoop 集群管理页面

增加数据节点
到这里 Hadoop 集群已经创建完成了,如果想增加节点,可以通过修改 docker-hadoop 中的 docker-compose.yml 文件来实现。
例如,我们给当前集群增加两个数据节点 datanode 对 docker-compose.yml 文件修改如下:
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode2
restart: always
volumes:
- hadoop_datanode2:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode3
restart: always
volumes:
- hadoop_datanode3:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
然后重新执行 docker-compose up -d 增加节点
03 测试 Hadoop 集群
测试准备
我们使用简单的词频统计 mapreduce 任务来测试 Hadoop 集群
首先下载 hadoop-mapreduce-examples jar 包
然后使用如下命令将这个 jar 包拷贝到 namenode 节点
docker cp .\hadoop-mapreduce-examples-2.7.1.jar namenode:/tmp/
然后我们创建一个 input.txt 测试文件,并输入文字内容
We can only go faster, we can only aim higher, we can only become stronger by standing together — in solidarity.
然后也将这个输入文件拷贝到 namenode 节点中
docker cp .\input.txt namenode:/tmp/

开始测试
首先使用如下命令进入到 namenode 容器中,并进入到 tmp 目录
docker exec -it namenode /bin/bash
cd tmp/
然后使用如下命令在 HDFS 中创建一个 input 目录
hdfs dfs -mkdir -p /user/root/input
将输入文件 input.txt 存储到 HDFS 中
hdfs dfs -put input.txt /user/root/input
# 查看输入文件内容
hdfs dfs -cat /user/root/input/input.txt
Tips:可以将文件通过如下命令添加到指定的 Datanode 节点中
hdfs dfs -put Input.txt the-datanode-id

最后使用如下命令在 Hadoop 集群中运行 wordcount 词频统计 mapreduce 任务
hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount input output
# 查看运行结果
hdfs dfs -cat output/part-r-00000

输入文字内容的词频统计结果如下所示
We can only go faster, we can only aim higher, we can only become stronger by standing together — in solidarity.

参考资料

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)