百度云资深架构师聊百度云存储架构特点
12月9日,2016中国存储峰会在北京举行。在“云存储及灾备技术论坛”,百度云资深架构师王耀介绍了百度云的发展历程,并就百度云存储产品体系中的块存储与对象存储的架构与特点进行了重点分享。在BAT中,百度做公有云比较晚,但在技术上却有很多创新。比如2013年引起广泛关注的ARM存储服务器就是一个很好的例子。最近两年,百度云开始发力,其云存储体系有诸多创新之处。据王耀介绍,目前百度云存
12月9日,2016中国存储峰会在北京举行。在“云存储及灾备技术论坛”,百度云资深架构师王耀介绍了百度云的发展历程,并就百度云存储产品体系中的块存储与对象存储的架构与特点进行了重点分享。
在BAT中,百度做公有云比较晚,但在技术上却有很多创新。比如2013年引起广泛关注的ARM存储服务器就是一个很好的例子。最近两年,百度云开始发力,其云存储体系有诸多创新之处。
据王耀介绍,目前百度云存储产品体系主要是块存储和对象存储,前者除了SSD,还提供普通云硬盘和高性能CDS;在对象存储方面,针对数据迁移成本问题,百度云专门开发了一种存储网关,客户通过云服务器和网关访问对象存储,能大幅降低使用成本。据悉,该产品将在2017年第一季度正式发布。
以下为王耀发言实录:
大家好。首先,介绍一下百度云,作为互联网公司,做云,发力比较晚一些,但是,百度云很多技术,尤其是存储技术,不是这两年凭空造出来的。
百度云发展历程
09年的时候,我们上线自己的一个分布式网页库,12年新一代分布式计算系统上线,单集群规模达到10000。13年的时候,就是业内首次大规模使用ARM存储服务器,提供一些低功耗一些存储,支撑一些对象存储,就是这一年,我们百度网盘开始发力了。其实,这个里面还没有列,14年,15年做了很多存储项目,后面会讲到给百度云做了一些工作。百度没有跨存储的需求,就是对于云而开发的一个。后面进行一些相应的分享。

这边简单介绍一下百度云存储产品体系,主要分两块。第一,块存储,第二,对象存储,块存储,就是配合我们的云主机提供磁盘服务的。然后,这个产品形态主要由几种组成,第一种就是高性能本地SSD盘,很多厂商可以提供。还提供普通云硬盘,还有高性能云磁盘。因为云上面跑虚拟化的时候,很多时候需要对于数据保证做一些那个,肯定对这个数据做一些快照。这个不经常使用,放在这个机型里面这个成本高一些。所以,我们把这个快照放在对象存储里面,我们采用一些编码,就是降低我们的存储一些成本。
讲到这个对象存储,大家可能不会很陌生,因为现在很多用到我们对象存储,很多手机的备份,无论是这些小米,或者Apple,手机备份传到对象存储系统上面。然后,百度对象存储为大家所熟知的百度网盘,百度网盘底层系统,就是这一套对象存储系统,这个在产品形态上面有两种。第一种标准对象存储系统,提供一种多副本存储形式,保存一些比较频繁访问的数据,比如网站首页、图片数据。然后,我们还提供一个低频BOS,提供一些访问频度不是很高的数据存储,采用EC编码降低成本。
然后,我们最近做了新存储,就是一个网关。百度云在运营过程当中发现,很多传统客户上云,他们的数据是符合对象存储的场景的,因为他数据可能非常多,比较在意降低成本。所以,他们数据如果上对象存储,大量的这些数据往对象存储上面搬迁需要很大成本,因为接口原因搬迁成本比较高。我们开发了一个网关,客户可以直接在云上面买一个云服务器,这个云服务器通过这个网关,通过一些协议直接访问对象存储。这个产品将会在明年的Q1面市。

百度云存储挑战与应对
讲了那么多云存储,我们的目的是什么?在我看来4个方面,一是提供一种非常非常易用的云存储,接口非常简单,服务非常好;第二,提供一个高可靠的环境,客户交了钱,存储数据,必须保证这个可靠性;第三就是高可用,因为存储基础设施部署在云上,云提供一个4个9以上的服务可用。第四就是低成本,很多情况下是因为成本,在云上面一些存储可以规模化采购,规模化运维,从而降低整个采购运营成本。
云存储有什么挑战?这个里面第一部分介绍一下云存储面向就是天灾跟人祸。其实这个是遇到过,14年时候,百度曾经有一个机房被雷击了,整个机房就不可以提供服务了。像在今年夏天,有一些移动互联网公司服务出现中断,这是因为机房进水了,这个也是天灾的因素。所以,在一些云上就是考虑怎么避免天灾,还有人祸,某某某因为修管道等等之类把光纤挖断了,导致互联网服务受损了。
除了这些天灾跟人祸之外,我们做云存储的时候,还要遇到很多的一些存储的硬件故障。包括交换机、存储服务器、硬盘等。
对抗天灾,最主要的手段是什么?就是跨地域,做一些冗余备份,有几种方式。第一级,我们提供了地域的冗余,一些重要的服务,我们在华北,华东,华南,三个地域分别部署存储服务。然后,即使在同样一个地域,我们同样也是会部署多个机房,北京,有一些比较大一些机房提供这些数据跨区域的冗余。
然后,针对同样一个区域,我们依然会提供很多的一些服务,就是机房里面提供跨节点,通过一些机制保障数据可靠性。这个里面需要做存储系统的时候,还有很多控制节点,这个也是需要做到一些高可用,这样才可以根本上保障系统是OK的。
OK,这个图是我们的拿一个机房举例,比较纯粹的一个系统,我们在构建这个访问原则的时候,一个机房依然有一个隔离的策略。第一级就是交换机,然后,初期的时候,故障率很高。买的部件也是会出现问题,还有就是节点,因为电源故障,总是有一些故障的。然后,其实我们面临最多的就是第三级,就是磁盘有一些故障,磁盘故障率都是有千分之五故障率,头三年,还没有过保修范围之内。

所以,这个后面右面举了一个例子,有一个数据,这个数据就是三个副本,放三个不同的交换机,还有不同的机器,不同的磁盘里面去,一个机器一个磁盘坏的时候不影响整个数据的可靠性。对于控制节点的冗余,实际上就是通过构建一个这种复制状态机,提供多个副本,解决数据一致性。具体来讲,实现业界的Raft一致性协议,解决master修复,复制,节点变更。因为Master也是进行一些维护,这个时候频繁替换一些master节点,我们要做很多的冗余。
百度云块存储
首先,介绍一下块存储,块存储其实跟云主机绑定在一起的,云主机跟云磁盘其实是提供一个可用区域级别,一个部署一个服务。每一个可用区内部部署一套系统,提供服务。然后,同时,就是把快照放一个地域范围内,整个就是这个范围内生效。北京两个机房,你这个主机,磁盘放在那个机房的有时候就是进行迁移的时候,先通过快照放在北京,共享一个快照池子,再把主机迁到另外一个机房。

讨论任何云存储的系统之前,我们先要明确一下存储模型是什么样子?对于云磁盘这个存储产品,我们设置存储模型两个字,第一个就是拆,第二个就是聚。由于提供这种逻辑的一种形态,那么,我们需要把这个拆成一个数据的一个块儿,因为这个云磁盘使用当中有很多空洞率。这个使用十几个G,不需要把没有使用过的块儿都是分配出来。所以,可以节省一些成本。
第二点就是什么呢?如果我把所有这个都拆成一个固定大小的块之后,就面临一个问题。大家如果熟悉这个架构设计,其实就是明白,这个当中有一个问题:我为每一个存储设计一个块儿,内存是吃不住的。就是非常的消耗内存,而且没有必要,就是64兆搞一个原型机。就是把拆好的这些,再聚合成一个一个的BlockGroup。然后,我们集群去管理这些BlockGroup就可以了。这样的话把整个量级降低两个量级左右。比如说,一个BlockGroup是64兆,如果我这个副本是一个6.4级,就是两个量级,要不然就是三个量级的降低。

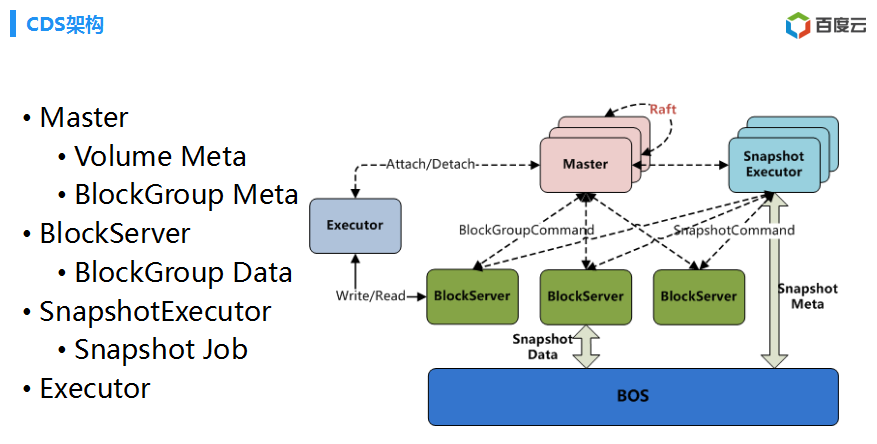
OK。云磁盘这个模型之后,就考虑云磁盘架构怎么实现的。比较像传统分布式存储的架构,几个常见的BlockServer必不可少的。我们的Master,这个限速多少?就是这样一些信息。另外一个,就是刚刚讲到了,聚合很多很多BlockGroup,就是管理这些BlockGroup,这些怎么复制?怎么调度他们?什么节点上来?这个是控制层面一些东西
然后,数据就是存在BlockServer,后面简单讲到数据一个复制跟修复的一些东西。这个里面单独提出一个模块,我们有一个叫做什么呢?SnapshotExecutor,包括执行创建一个快照,回滚一个快照,整个相当于一个分布式任务调度系统,这个是相当于一个分布式调度系统,Master调度任务,就是对应不同的BlockServer,把相应的BlockServer进行快照,然后把数据写到对象存储里面。
刚刚讲到了这个BlockServer进行数据复制,实现这个数据的冗余,还有就是可靠性。
这是一个复制结构,这个复制结构在业界就是比较折中的一个方式,在延迟上面达到比较优的一个折中。然后,另外,我们就是没有实现那种什么呢?就是三副本,都是写成功才可以成功,如果有一个磁盘卡了一下,这个IO就是抖了一下。有时候抖的不是一秒,两秒,甚至是10秒以上的情况。我们实现了什么?就是多数复制成功这样一个机制。那么,主挂了,这个副本有一些成功的可以成功。有一个挂了,有一个慢了,不影响整个复制的过程。
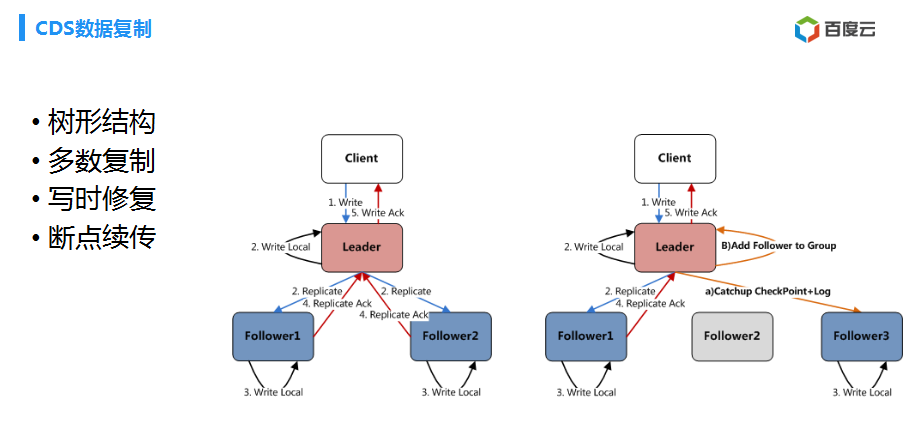
对于云磁盘服务来讲,任何一个块儿,用户都可能在下一时刻访问这些块儿,所以,必须做一个不影响用户现在的读写一种修复机制。我们实现的就是写时修复一种方案。

百度云对象存储系统
介绍一下百度存储系统。这个不单单是简单存储系统,就是一个生态。从这个数据的传输存储,到数据处理,数据分发,整个一个生态。

这个数据传输,亚马逊都是拿一些机箱,一些卡车运输。百度也是一样的,也是进行一些服务。
架构就是三个系统,第一个系统就是接入系统,CloudStorage,等等一系列接入事情。第二个,MetaStorage,这个里面就是什么呢?对象存储提供一种目录数的概念。最后一个叫做DataStorage,难度比较高,提供对应的一些数据存储。

其实对象存储提供这种跨地域容灾,上面就是一个接入层,用户数据,先写入接入层。这个时候数据可以双写。把原型机双写,接下来,写成功了,这个消息队列就是分布式,也是跨区域容灾的。这样的话多个机房可以同步这个列表,看一下有没有成功。

OK,讨论一下,刚刚介绍整个架构,提供了近期一个数据,就是多副本数据,历史数据就是采用编码,跟整个对象存储编码差不多。对于低频BOS,就是采用一些编码,索引跟数据是分离的。这些EC编码使用低功耗。对于低频存储也是用这个接的,我们一个引擎解决这个问题了,把数据放内存当中。EC编码进行什么呢?然后,然后进行编码,然后,存下某一个(英文),存在EC存储里面具体的位置。
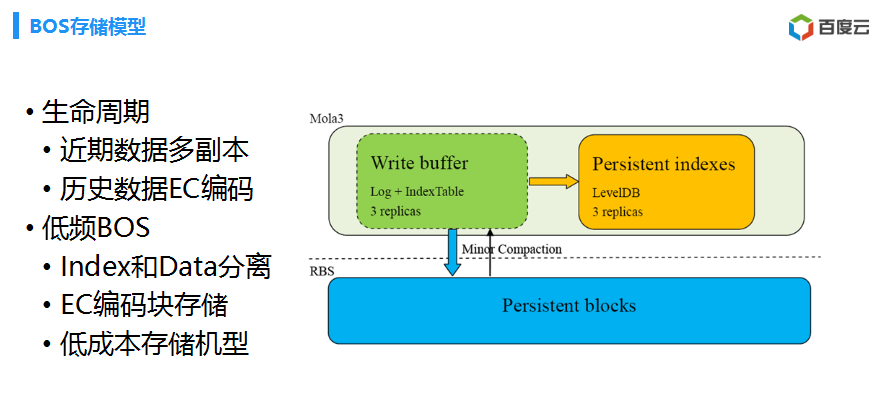
所以,依赖内部一个故障预警一个系统,就是可以做到85%正确率,就是对应这个数据,这样不用读8份数据。这个是RBS架构。



华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)