从jvm的角度来看java的多线程
最近在学习jvm,发现随着对虚拟机底层的了解,对java的多线程也有了全新的认识,原来一个小小的synchronized关键字里别有洞天。决定把自己关于java多线程的所学整理成一篇文章,从最基础的为什么使用多线程,一直深入讲解到jvm底层的锁实现。多线程的目的为什么要使用多线程?可以简单的分两个方面来说:- 在多个cpu核心下,多线程的好处是显而易见的,不然多个cpu核心只跑一个线程其他的核心
最近在学习jvm,发现随着对虚拟机底层的了解,对java的多线程也有了全新的认识,原来一个小小的synchronized关键字里别有洞天。决定把自己关于java多线程的所学整理成一篇文章,从最基础的为什么使用多线程,一直深入讲解到jvm底层的锁实现。
多线程的目的
为什么要使用多线程?可以简单的分两个方面来说:
- 在多个cpu核心下,多线程的好处是显而易见的,不然多个cpu核心只跑一个线程其他的核心就都浪费了;
- 即便不考虑多核心,在单核下,多线程也是有意义的,因为在一些操作,比如IO操作阻塞的时候,是不需要cpu参与的,这时候cpu就可以另开一个线程去做别的事情,等待IO操作完成再回到之前的线程继续执行即可。
多线程带来的问题
其实多线程根本的问题只有一个:线程间变量的共享
java里的变量可以分3类:
- 类变量(类里面static修饰的变量)
- 实例变量(类里面的普通变量)
- 局部变量(方法里声明的变量)
下图是jvm的内存区域划分图:

根据各个区域的定义,我们可以知道:
1. 类变量 保存在“方法区”
2. 实例变量 保存在“堆”
3. 局部变量 保存在 “虚拟机栈”
“方法区”和“堆”都属于线程共享数据区,“虚拟机栈”属于线程私有数据区。
因此,局部变量是不能多个线程共享的,而类变量和实例变量是可以多个线程共享的。事实上,在java中,多线程间进行通信的唯一途径就是通过类变量和实例变量。也就是说,如果一段多线程程序中如果没有类变量和实例变量,那么这段多线程程序就一定是线程安全的。
以Web开发的Servlet为例,一般我们开发的时候,自己的类继承HttpServlet之后,重写doPost、doGet处理请求,不管我们在这两个方法里写什么代码,只要没有操作类变量或实例变量,最后写出来的代码就是线程安全的。如果在Servlet类里面加了实例变量,就很可能出现线程安全性问题,解决方法就是把实例变量改为ThreadLocal变量,而ThreadLocal实现的含义就是让实例变量变成了“线程私有”的,即给每一个线程分配一个自己的值。
现在我们知道:其实多线程根本的问题只有一个:线程间变量的共享,这里的变量,指的就是类变量和实例变量,后续的一切,都是为了解决类变量和实例变量共享的安全问题。
如何安全的共享变量
现在唯一的问题就是要让多个线程安全的共享变量(下文中的变量一般特指类变量和实例变量),上文提到了一种ThreadLocal的方式,其实这种方式并不是真正的共享,而是为每个线程分配一个自己的值。
比如现在有一个特别简单的需求,有一个类变量a=0,现在启动5个线程,每个线程执行a++;如果用ThreadLocal的方式,最后的结果就是5个线程都拥有一份自己的a值,最终结果都是1,这显然不符合我们的预期。
那么如果不使用ThreadLocal呢?直接声明一个类变量a=0,然后让5个线程分别去执行a++;这样结果依旧不对,而且结果是不确定的,可能是1,2,3,4,5中的任一个。这种情况叫做竞态条件(Race Condition),要理解竞态条件先要理解Java内存模型:要理解java的内存模型,可以类比计算机硬件访问内存的模型。由于计算机的cpu运算速度和内存io速度有几个数量级的差距,因此现代计算机都不得不加入一层尽可能接近处理器运算速度的高速缓存来做缓冲:将内存中运算需要使用的数据先复制到缓存中,当运算结束后再同步回内存。如下图:
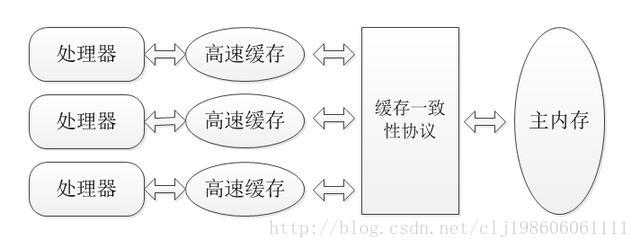
因为jvm要实现跨硬件平台,因此jvm定义了自己的内存模型,但是因为jvm的内存模型最终还是要映射到硬件上,因此jvm内存模型几乎与硬件的模型一样:
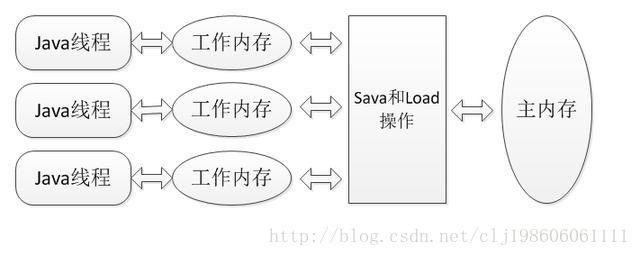
每个java线程都有一份自己的工作内存,线程访问变量的时候,不能直接访问主内存中的变量,而是先把主内存的变量复制到自己的工作内存,然后操作自己工作内存里的变量,最后再同步给主内存。
现在就可以解释为什么5个线程执行a++最后结果不一定是5了,因为a++可以分解为3步操作:
- 把主内存里的a复制到线程的工作内存
- 线程对工作内存里的a执行a=a+1
- 把线程工作内存里的a同步回主内存
而5个线程并发执行的时候完全有可能5个线程都先执行了第一步,这样5个线程的工作内存里a的初始值都是0,然后执行a=a+1后在工作内存里的运算结果都是1,最后同步回主内存的值肯定也是1。而避免这种情况的方法就是:在多个线程并发访问a的时候,保证a在同一个时刻只被一个线程使用。
同步(synchronized)就是:在多个线程并发访问共享数据的时候,保证共享数据在同一个时刻只被一个线程使用。
同步基本思想
为了保证共享数据在同一时刻只被一个线程使用,我们有一种很简单的实现思想,就是在共享数据里保存一个锁,当没有线程访问时,锁是空的,当有第一个线程访问时,就在锁里保存这个线程的标识并允许这个线程访问共享数据。在当前线程释放共享数据之前,如果再有其他线程想要访问共享数据,就要等待锁释放。
我们把这种思想的三个关键点抽出来:
- 在共享数据里保存一个锁
- 在锁里保存这个线程的标识
- 其他线程访问已加锁共享数据要等待锁释放
Jvm的同步实现
可以说jvm中的三种锁都是以上述思想为基础的,只是实现的“重量级”不同,jvm中有以下三种锁(由上到下越来越“重量级”):
- 偏向锁
- 轻量级锁
- 重量级锁
其中重量级锁是最初的锁机制,偏向锁和轻量级锁是在jdk1.6加入的,可以选择打开或关闭。如果把偏向锁和轻量级锁都打开,那么在java代码中使用synchronized关键字的时候,jvm底层会尝试先使用偏向锁,如果偏向锁不可用,则转换为轻量级锁,如果轻量级锁不可用,则转换为重量级锁。具体转换过程下面会讲。
要想深入了解这3种锁需要了解对象的内存结构(MarkWord头),会涉及到字节码的内部存储格式,但是其实我觉得脱离细节的实现,单从原理上理解这三个锁是很容易的,只需要了解两个大体的概念:
MarkWord:java中的每个对象在存储的时候,都有统一的数据结构。每个对象都包含一个对象头,称为MarkWord,里面会保存关于这个对象的加锁信息。
Lock Record: 即锁记录,每个线程在执行的时候,会有自己的虚拟机栈,当个方法的调用相当于虚拟机栈里的一个栈帧,而Lock Record就位于栈帧上,是用来保存关于这个线程的加锁信息。
最初jvm没有前两种锁(前两种都是jdk1.6才引入的),只有重量级锁。
我们之前给出了同步基本思想的三个点,我们也说了jvm的三种锁都是以基本思想为基础的,而这三种锁在第1、2点的实现上本质上是一样的:
- 在共享数据里保存一个锁 //java同步是通过synchronized关键字实现的,synchronized有三种用法:一种是同步块,这种用法需要指明一个锁定对象;一种是修饰静态方法,这种用法相当于锁定Class对象;一种是修饰普通方法,这种用法相当于锁定方法所在的实例对象。因此,在java里能够被synchronized关键字锁定的一定是对象,因此就要在对象里保存一个锁,而对象内存结构里的MarkWord就可以认为是这个锁。三种锁虽然实现细节不同,但是都是使用MarkWord保存锁的。
- 在锁里保存这个线程的标识 //偏向锁是在MarkWord里保存线程id,轻量级锁是在MarkWord里保存指向拥有锁的线程栈中锁记录的指针,重量级锁是在MarkWord中保存指向互斥量的指针(互斥量只向一个线程授予对共享资源的独占访问权,可以认为是记录了线程的标识)而区分这三种锁的关键,就是同步基本思想的第三点:
- 其他线程访问已加锁共享数据要等待锁释放 //这里的等待锁释放是一个抽象的说法,并没有严格要求怎么等待。而重量级锁因为使用了互斥量,这里的等待就是线程阻塞。使用互斥量可以保证所有情况下的并发安全,但是使用互斥量会带来较大的性能消耗。而且在实际的项目代码中,很可能一段本来不会有并发情况的代码被加了锁,这样每次使用互斥量就白白消耗了性能。能不能先假设被加锁的代码不会有并发的情况,等到发现有并发的时候再使用互斥量呢?答案是可以的,轻量级锁和偏向锁都是基于这种假设来实现的。
轻量级锁
轻量级锁的核心思想就是“被加锁的代码不会发生并发,如果发生并发,那就膨胀成重量级锁(膨胀指的锁的重量级上升,一旦升级,就不会降级了)”。
轻量级锁依赖了一种叫做CAS(compare and swap)的操作,这个操作是由底层硬件提供相关指令实现的:
CAS操作需要3个参数,分别是内存位置V,旧的期望值A和新值B。CAS指令执行时,当且仅当V当前值符合旧值A时,处理器用新值B更新V的值,否则不执行更新。上述过程是一个原子操作。
轻量级锁加锁
假设现在开启了轻量级锁,当第一个线程要锁定对象时,该线程首先会在栈帧中建立Lock Record(锁记录)的空间,用于存储对象目前MarkWord的拷贝,然后虚拟机将使用CAS操作尝试将对象的MarkWord更新为指向线程锁记录的指针。如果操作成功,则该线程获得对象锁。如果失败,说明在该线程拷贝对象当前MarkWord之后,执行CAS操作之前,有其他线程获取了对象锁,我们最开始的假设“被加锁的代码不会发生并发”失效了。此时轻量级锁还不会直接膨胀为重量级锁,线程会自旋不停地重试CAS操作寄希望于锁的持有线程主动释放锁,在自旋一定次数后如果还是没有成功获得锁,那么轻量级锁要膨胀为重量级锁:之前成功获取了轻量级锁的那个线程现在依旧持有锁,只是换成了重量级锁,其他尝试获取锁的线程进入等待状态。
轻量级锁解锁
轻量级锁的解锁也是用CAS来操作,如果对象的MarkWord中依然是持有锁线程的锁记录指针,则CAS成功,把锁记录中的原MarkWord的拷贝复制回去,解锁完成;如果对象的MarkWord中保存的不再是持有锁线程的锁记录指针,说明在持有锁线程持有锁期间,这个轻量级锁已经因为其它线程并发获取膨胀为了重量级锁,因此线程在释放锁的同时,还要唤醒(notify)等待的线程。
偏向锁
根据轻量级锁的实现,我们知道虽然轻量级锁不支持“并发”,遇到“并发”就要膨胀为重量级锁,但是轻量级锁可以支持多个线程以串行的方式访问同一个加锁对象。比如A线程可以先获取对象o的轻量锁,然后A释放了轻量锁,这个时候B线程来获取o的轻量锁,是可以成功获取得,以这种方式可以一直串行下去。之所以能实现这种串行,是因为有一个释放锁的动作。那么假设有一个加锁的java方法,这个方法在运行的时候其实从始至终只有一个线程在调用,但是每次调用完却也要释放锁,下次调用还要重新获得锁。
那么我们能不能做一个假设:“假设加锁的代码从始至终就只有一个线程在调用,如果发现有多于一个线程调用,再膨胀成轻量级锁也不迟”。这个假设,就是偏向锁的核心思想。
核心实现
偏向锁的核心实现很简单:假设开启了偏向锁,当第一个线程尝试获得对象锁的时候,也会在栈帧中建立Lock Record锁记录,但是这个Lock Record空间不需要初始化(后面会用到它),然后直接用CAS将自己的线程ID写到对象的MarkWord里,如果CAS操作成功,就获取了偏向锁。线程获取偏向锁后即便是执行完加锁的代码块,也会一直持有锁不会主动释放。因此这个线程以后每次进入这个锁相关的代码块的时候,都不需要执行任何额外的同步操作。
当有另外一个线程尝试获得锁的时候,需要进行revoke操作,分情况讨论:
- 判断持有偏向锁的线程是否还活着,如果线程不处于活动状态,则偏向锁被重置为无锁状态。
- 如果持有偏向锁的线程还活着而且当前线程实际没有持有着锁,则偏向锁被重置为无锁状态。
- 如果持有偏向锁的线程还活着而且当前线程实际持有着锁(在同步代码块中),那么试图获得偏向锁的线程将等待一个全局安全点(global safepoint),在全局安全点,【试图获得偏向锁的线程】操作【持有偏向锁的线程的线程栈】,遍历里面的所有栈帧里的所有与当前锁对象相关联的LockRecord,修改LockRecord里的内容为轻量级锁的LockRecord应该有的内容,然后把“最老的”(oldest)一个LockRecord的指针写到对象的MarkWord里,至此,就好像是原来从没有使用过偏向锁,使用的一直是轻量级锁。
上面的第3点基本是照着官方文档翻译的,看了一些书、博客,对这块都说的不明白。
以下是我自己的理解:
一个已经持有偏向锁的线程,再次进入这个锁相关的代码块的时候,虽然不需要执行额外的同步操作,但是依旧会在栈上生成一个空的LockRecord,因此对于一个重入了几次对象锁的线程来说,栈中就有了关联同一个对象的多个LockRecord。
而且在对象的MarkWord里,会记录着加锁的次数,每重入一次,就+1;当每次要解锁的时候,首先会把对象MarkWord里的加锁次数-1,只有当加锁次数减到0的时候,才真正的去执行加锁操作。这个是参考了monitorexit字节码的解释来的:
Note that a single thread can lock an object several times - the runtime system maintains a count of the number of times that the object was locked by the current thread, and only unlocks the object when the counter reaches zero .
而加锁次数减到0的时候,此时对应的锁记录肯定是第一次加锁的锁记录,也就是“最老的”,因此需要把“最老的”锁记录的指针写到对象的MarkWord里,这样当执行轻量级锁解锁的CAS操作的时候就能够成功解锁了。)
偏向锁优化手段
从上述偏向锁核心实现我们可以看出来,当访问一个对象锁的只有一个线程时,偏向锁确实很快,但是一旦有第二个线程来访问,就可能要膨胀为轻量级锁,膨胀的开销是很大的。
所以我们会有一个想法:如果在要给一个对象加偏向锁的时候,能提前知道这个对象会是由单个线程访问还是多个线程访问就好了。那么怎么知道一个没有被访问过的对象是不是仅会被单线程访问呢?我们知道每个对象都有对应的类,我们可以通过和这个对象同属一个类(data type)的其他对象被访问的情况来推测这个对象将要被访问的情况。
因此我们可以从data type的维度来批量操作这个data type下的所有对象的偏向锁:
- 当某个data type下的所有对象的偏向锁发生revoke次数到达一定阈值的时候,将触发bulk rebias:对该data type下所有对象,将偏向锁重置为初始状态(即可以让下一个访问的线程获得锁的状态),如果对象正在持有锁(当前在synchronized块中),则对该对象执行revoke操作使膨胀为轻量级锁。
- 当某个data type下执行的bulk rebias次数达到一定阈值时,会触发bulk revocation,该data type下所有对象的偏向锁被膨胀为轻量级锁,而且未来产生的这个data type的实例对象默认就被禁用了偏向锁。
总结
其实抛开实现的细节,java的多线程很简单:
java多线程主要面临的问题就是线程安全问题
–》
线程安全问题是由线程间的通信造成的,多个线程间不通信就没有线程安全问题
–》
java中线程通信只能通过类变量和实例变量,因此解决线程安全问题就是解决对变量的安全访问问题
–》
java中解决变量的安全访问采用的是同步的手段,同步是通过锁实现的
–》
有三种锁能保证变量只有一个线程访问,偏向锁最快但是只能用于从始至终只有一个线程获得锁,轻量级锁较快但是只能用于线程串行获得锁,重量级锁最慢但是可以用于线程并发获得锁,先用最快的偏向锁,每次假设不成立就升级一个重量。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)