
GaussDB关键技术原理:高弹性(一)
本篇将分享GaussDB高弹性方面的相关知识,从CBI索引方面对hashbucket展开介绍。
GaussDB关键技术原理:高可用篇,从GaussDB数据库DCF、双集群容灾、逻辑复制及两地三中心跨Region容灾方面对GaussDB高可用能力进行了解读。本篇将分享GaussDB高弹性方面的相关知识,从CBI索引方面对hashbucket展开介绍。
目录
1 前言
GaussDB支持hash分布表,hash分布表的数据行根据hash分布列进行hash计算,计算出的hash值被打散到各个DN。随着业务增长数据规模变大,DN的承载能力会逐渐不够,这样就需要对DN节点数量进行扩充。节点数量扩充后,存储于原DN节点的数据就需要进行数据重新分布。目前GaussDB采用的是share-nothing的本地盘架构,各个DN节点独立维护各自的数据,这种架构下数据重分布的难度很大。
如下图x所示,在线扩容从时间轴上看主要由两部分组成:
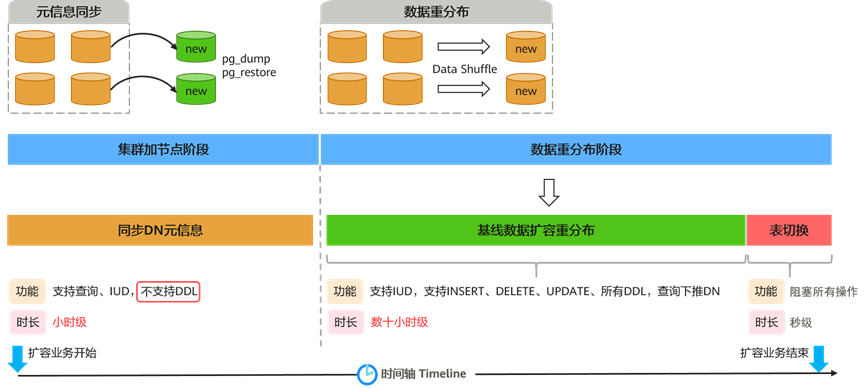
图x 在线扩容示意图
-
集群加节点阶段:对新加入的DN节点进行元信息的同步,然后更新集群拓扑,启动新节点。设置包含新节点的Installation NodeGroup信息,将老集群的NodeGroup设置为待重分布的状态。
-
数据重分布阶段:对分布在老集群的用户表通过数据重分布搬迁至新集群,在新加节点完成业务上线。数据重分布主要有两种方式,一种逻辑搬迁方式,主要通过SQL接口进行,另一种是物理搬迁的方式,直接通过文件拷贝和日志多流追增进行。本节主要介绍逻辑数据重分布的过程。
由此可见,在线数据重分布是在线扩容的关键步骤。目前已经支持了以表为粒度的逻辑数据重分布,其核心思想是采用SQL接口将原表的数据导入到一个按照新分布方式存储的新表上,然后进行两个表的元数据切换。处理在线业务的核心思想是:将DML操作的UPDATE拆分成INSERT和DELETE,所有INSERT都采用追增写入的模式,写入原表的尾部,通过CTID确定每轮处理数据的范围,使用“{节点ID}+{元组ID}”表示删除的元组位置,原表的数据直接删除,新表的数据追增删除,直至原表和新表数据收敛追平,详细步骤如下图x。

图x 重分布过程中在线业务处理过程
P1:将原表设置为追增模式,创建新表(新增两列表示元组ID和节点ID)、delete_delta表记录删除原组的位置信息,并将新表索引失效,提升基线数据批量插入的效率。
P2_1:采用“insert into 新表select * from 原表”的方式完成基线数据的插入。此时用户业务采用追加写的方式写在原表的后面,删除的数据直接进行删除并且将原组ID和节点ID记录在delete_delta表中。
P2_2:重建新表的索引,此阶段引入了并行建索引来提升重建索引的效率。
P3:采用多轮追增(推进CTID、DELETE、INSERT)的方式完成新表和元数据的数据追平。
P4:拿原表的8级锁,完成元数据切换,保留原表的元信息和新表的数据文件信息。
逻辑数据重分布的方式比较类似于VACUUM FULL的运行机制,存在很多约束和限制。首先新老表同时存在,会占用双份磁盘空间影响磁盘的利用率。其次,如果要支持在线的数据重分布,采用SQL接口的方式挑战会比较大,例如表锁冲突,shared-buffer资源争抢等问题。如果两个具有相同分布规则的表需要进行JOIN操作,重分布期间可能存在一个表完成数据重分布,另一个表没有完成,这个阶段两个表就可能存在跨节点的分布式JOIN,与原有的本地JOIN相比性能会下降十分严重。
为了解决逻辑扩容在有复杂业务查询场景在线业务的性能劣化问题,我们引入了基于hashbucket表的物理在线扩容方案,不仅可以很好地解决带有JOIN关系业务性能下降的问题,还可以解除预留磁盘空间的约束,同时引入物理扩容的概念,大大提升了在线扩容本身的性能。
2 hashbucket介绍
2.1简介
hashbucket表在DN上的数据按照hash值进行聚簇存储,具有相同hash值的数据会统一管理在一个bucket中。从分布式集群的角度看,hashbucket表将用户表拆分为多个分片的形式存储——每个表切分为N个分片,每个DN存储N/DNnum个分片。拆分使用的规则与hash分布规则一致,使用相同的分布列计算hash值。图x显示的是插入一行数据,在CN上根据分布列计算hash值并取模bucket桶长度BUCKETLEN(图中是6)计算出具体的DN节点,在DN节点上对不同的hash值再进行分片拆分。

图x hashbucket表插入数据逻辑示意图
存储的组织方式如下图x所示,假设用户表是hash分布表,在CN上有6个hash bucket桶,其中1~3对应DN1的数据分片,4~6对应DN2的数据分片。CN上存储一个映射关系表示每个DN分片上有哪些bucket桶,用户存入一条数据时将根据分布列的值计算属于哪个bucket桶,再根据CN上的映射关系路由到对应DN分片进行数据存储。
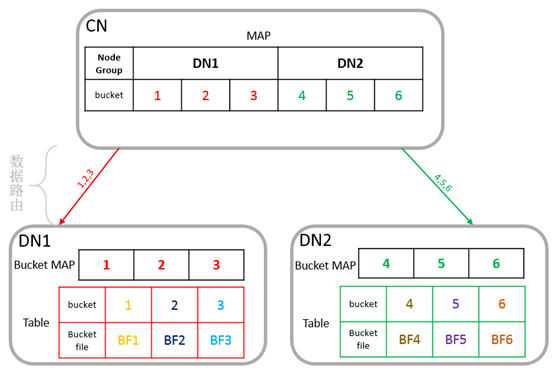
图x 存储组织方式示意图
如果每张hash分布的表都进行文件拆分,将会导致小文件非常多,给文件系统造成比较大的压力,因此hashbucket采用段页式的存储方式,即所有表都采用一组文件进行存储,后续段页式章节会进行详细介绍。
从DN存储节点的角度上看,hashbucket表和普通页式表主要区别在于数据文件管理,事务管理和元数据管理三个方面:
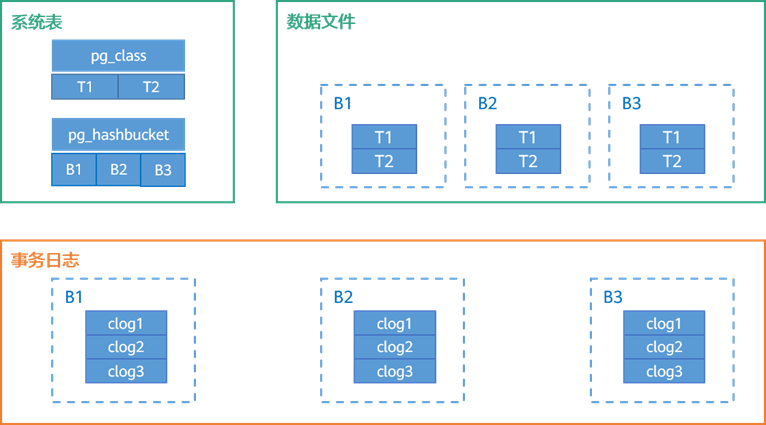
图x 数据管理示意图
-
数据文件: 按照bucket对段页式文件组进行库级别分片存储。
-
事务管理: 按照bucket对CLOG进行实例级分片存储。后文会做详细介绍。
-
元数据管理: pg_class增加库级分片标识、pg_hashbucket增加库级别分片信息。
为了能够在CN和DN区分hashbucket表,在pg_class系统表中增加一列relbucket,CN上存储1,DN上存储3,表示将进行分片存储。另外新增一个库级系统表pg_hashbucket,存储hashbucket相关的信息,定义如下表x所示。
表x 系统表pg_hashbucket
| 属性名 | 数据类型 | 注释 |
| bucketid | oid | CN上为PG_HASHBUCKET系统表所在DATABASE绑定的NodeGroup的OID。DN上此列为空。 |
| bucketcnt | interger | CN上不使用此参数,DN上为当前DN所拥有的bucket数量。 |
| bucketvector | oidvector_extend | CN上不使用此参数,DN上为当前DN所拥有的bucket列表。 |
| bucketmap | text | 用来存储逻辑bucket到物理bucket的映射关系,即16384到1024的映射关系。 |
| bucketversion | oidvector_extend | 记录后续hashbucket扩容过程中发生改变的信息版本号。 |
| bucketcsn | text | hashbucket重分布前源节点每个bucket对应的最大CSN,用于新节点可见性判断。 |
| bucketxid | text | hashbucket扩容,新节点上线设置的next_xid,用于校验是否在阈值范围内。 |
因此,创建库的时候会生成pg_hashbucket中bucket分片的分布信息,hashbucket表拥有库级的特点,即一个库的所有hashbucket表一定具有相同的分布方式。所有hash分布的用户表都可以采用hashbucket分片存储的方式,用户在创建表时通过指定参数来实现,如下:
CREATE TABLE t1 (a int, b text) WITH (hashbucket=on);hashbucket表在扩容的时候通过物理文件搬迁完成,因此每个库以bucket文件为粒度在新节点上线业务,同时原子性地刷新pg_hashbucket系统表。业务会在DN上访问pg_hashbucket系统表过滤bucket list来找到正确的数据。
由于hashbucket表对数据文件进行了切片,如果直接创建BTree索引,索引也需要进行切片才能访问到正确的数据,如果计划可以直接剪枝则性能不受影响,如果计划不能剪枝则需要遍历1024/DN分片数棵BTree树,会严重影响性能,因此引入一种新的索引——CBI索引,跨bucket索引,所有bucket一棵BTree,索引中增加bucketid信息,来提升性能,下一章节将会详细介绍。
2.2 CBI索引
GaussDB针对hashbucket表有两种索引,bucket全局索引(跨bucket索引,cross-bucket index,CBI)和bucket本地索引(local-bucket index,LBI)。跨bucket索引为hashbucket聚簇存储提供一种跨bucket的索引能力,即在创建索引时,一个索引文件可以对应表级或分区级的所有bucket文件。该索引可以为指定粒度的表提供跨bucket的索引扫描,避免顺序扫描当前表下的大量bucket文件才能查到目标元组,提升查询性能。通过在创建索引时指定“crossbucket=on”可以创建跨bucket索引。
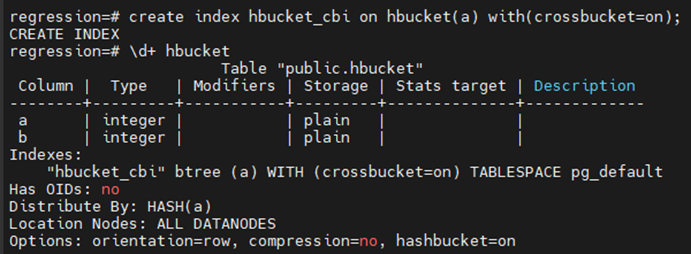
图x 创建CBI索引示意图
hashbucket表跨bucket索引如下图x所示,只有一个跨bucket索引文件,在扫描该索引时能获取目标元组完备的位置信息(元组所在bucket分片等),读取指定的bucket分片就能获取目标元组。
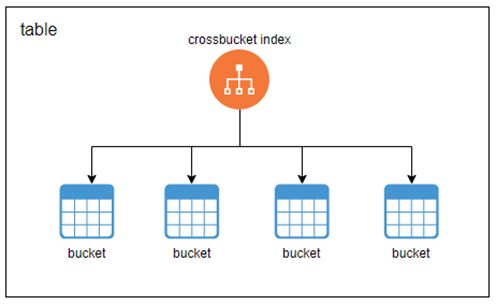
图x CBI索引结构示意图
需要注意的是,在当前版本中跨bucket索引只面向分布式GaussDB,CBI创建的前提是hashbucket聚簇存储开启,仅支持BTree索引,不支持部分索引以及其他类型索引,GLOBAL和LOCAL索引不允许建在同一列,仅支持行存表,GLOBAL CROSSBUCKET索引支持最大列数为30;LOCAL CROSSBUCKET索引支持最大列数为31。
2.2.1 CBI索引元组
索引元组是一种用于建立索引的数据结构,CBI索引元组的结构如下图x所示,包含索引键值、bucket分片id、数据元组信息。当需要访问数据时,通过bucketid找到数据元组所在的bucket分片,然后按数据行id找到对应的数据元组。

图x CBI索引元组结构
2.2.2 CBI索引的实现
-
CBI索引创建
跨bucket索引创建流程如下:解析SQL语句确定要创建的索引是CBI,进入创建索引流程;创建跨bucket索引关系,进入索引构建流程;索引构建流程中判断索引为跨bucket索引时,遍历每个bucket扫描堆表查找要加到索引中的元组,进入BTree构建流程;BTree构建流程中使用堆表关系和索引关系创建BTree索引,保存扫描到的数据元组数和创建的索引元组数。
-
CBI索引扫描
基本思路是,对父表构建索引,索引元组记录所在分片的bucketid,这两个属性作为INCLUDE参数被加入到索引列,封装进索引元组。索引扫描时,先通过BTree遍历找到满足索引键条件的索引元组,然后读取该元组中记录的bucketid,获取目标元组所在的分区和bucket分片,再根据这些信息缩小查找范围获取最终的目标元组。
-
CBI索引插入删除
分布式全局索引插入流程与普通索引插入流程基本一致,需要注意的是唯一性检测流程的适配。当插入的数据不允许重复,会触发唯一性检测,也就需要将当前即将插入的数据与已存在数据进行比较,这就需要对特定范围的数据进行扫描。对于跨Bucket索引,这个特定范围需要根据当前索引元组中存储的bucketid来锁定,实现载入相应的目标表。
-
CBI索引清理
索引清理对于hashbucket表的处理是通过遍历数据表以及对应的索引分片,分别清理各个分片。引入CBI后检查数据表相关的索引是否为CBI,同时收集当前bucket的bucketid和bucket中dead的数据元组进入BTree清理页面流程。在BTree清理页面流程中,如果索引为CBI,则从索引元组中获取目标元组所在的bucketid,清理目标元组对应的索引元组。
2.2.3 CBI元数据
跨bucket索引的元数据可通过系统视图pg_indexes、系统表pg_class查看。系统视图pg_indexes提供对数据库中每个索引的有用信息的访问,包含的关键字段如下表x所示。
表x 系统视图pg_indexes部分字段
| 名称 | 类型 | 描述 |
| tablename | name | 索引所服务的表的名称。 |
| indexname | name | 索引名称。 |
| tablespace | name | 包含索引的表空间名称。 |
| indexdef | text | 索引定义。 |
系统表pg_class存储数据库对象及其之间的关系。与CBI索引相关的字段如下表x,可以查到跨bucket索引的表空间、访问方法等信息。
表x 系统表pg_class部分字段
| 名称 | 类型 | 描述 |
| relname | name | 包含这个关系的名称空间的oid |
| reloptions | text[] | 表或索引的访问方法,使用"keyword=value"格式的字符串。 |
| relbucket | Oid | 当前表是否包含hashbucket分片。有效的oid指向 pg_hashbucket表中记录的具体分片信息。NULL表示不包含hash bucket分片。 |
以上内容从CBI索引方面对hashbucket进行了解读,下篇将从优化器剪枝、执行器方面继续介绍GaussDB高弹性技术,敬请期待!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 54
54 0
0- 0



 已为社区贡献441条内容
已为社区贡献441条内容

所有评论(0)