Linux高阶—磁盘性能分析iostat(二)
存储性能定义的三个核心指标:IOPS、Throughput、awaitIOPS的含义是:存储每秒钟可以处理的IO的个数;Throughput吞吐量(带宽)的含义是:存储每秒能处理的数据的总量,单位是MB/S;Await响应时间:单位时间内I/O延时。有些人就会说了,你说定义是否正确?不会胡说八道吧!上图说话:第一张图:业界存储技术性能天花板企业宣传说IOPS能达到 2100000,我相信对于一个世
在分析存储性能之前,需要先了解存储性能定义的三个核心指标:IOPS、Throughput、await
- IOPS的含义是:存储每秒钟可以处理的IO的个数;
- Throughput吞吐量(带宽)的含义是:存储每秒能处理的数据的总量,单位是MB/S;
- Await响应时间:单位时间内I/O延时。
有些人就会说了:你说的定义是否正确?不会胡说八道吧!上图说话:
第一张图:
- 业界存储技术性能天花板企业宣传说IOPS能达到 2100000(存储在所有磁盘写满的情况下每一秒的IO处理能力),我相信对于一个世界500强企业能说这样话,肯定做个相关业务压测才能输出结果,数据来源应该可靠。
- 从业界存储技术性能天花板企业指标监控图可以看出,决定存储性能的三个指标就是IOPS、Throughput、await

第二张图:
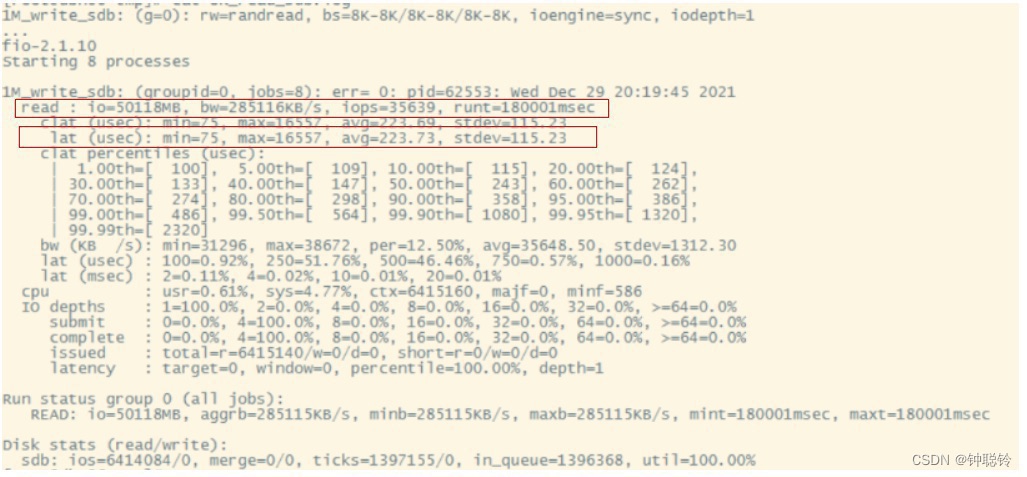
- 开源的FIO也是三个性能指标,按单个磁盘、8KB块、读测试,测试结果信息看方框的数据:

- IOPS:存储每秒钟可以处理的IO的个数iops=35639
- Throughput:bw=285116KB/S=278MB/S
- Await:lat(usec代表微秒) ,平均响应时间avg=223.73微秒=0.2毫秒
看到上面的数据,可能又有人发起挑战了:你的存储带宽每秒钟只能写300MB上下,你这性能太差了吧!
博主可能心里又会想了:这个屌毛,真会找事!心里已经默默骂了一千遍。
正面就这么说:原因是小文件太多了,每秒都快4万了,40000*8KB=320000KB/1024≈300MB,文件数瓶颈导致带宽上不去,反之加大block块大小,文件数下降带宽就能上去了。
总结了以下几种应用场景推荐:
- 小文件随机读写的应用要求存储具有足够的I/O能力,所以要求较高的IOPS,在乎的是处理个数;
- 大文件持续传输型的应用需要的是存储具有充分的带宽(Throughput吞吐量)性能,在乎处理时长;
- 读写需要快速响应,比如说游戏操控,那就关注磁盘await响应时间。
FIO测试案例:
使用FIO进行读写操作为高危操作,请务必提前查询和确认好用于FIO测试的卷挂载详情,并在后续测试过程中,严格使用查询到的测试卷设备名,避免出现对系统盘或者其他业务数据卷进行误操作。
rw=randwread 测试随机读的I/O
rw=randwrite 测试随机写的I/O
rw=read 测试顺序读的I/O
rw=write 测试顺序写的I/O
rw=rw 测试顺序混合写和读的I/O
rw=randrw 测试随机混合写和读的I/O,默认写占30%,读占70%
rwmixwrite=30 在混合读写的模式下,写占30%
1、小块8K随机读:fio -filename=/dev/sdb -direct=1 -rw=randread -bs=8K -numjobs=8 -runtime=180 -group_reporting -name=8KB_randread_sdb -output=/tmp/8K_randread_sdb.log -randrepeat=0 -norandommap&
2、小块8K随机写:fio -filename=/dev/sdb -direct=1 -rw=randwrite -bs=8K -numjobs=8 -runtime=180 -group_reporting -name=8KB_randwrite_sdb -output=/tmp/8K _randwrite_sdb.log -randrepeat=0 -norandommap&
3、小块8K随机混合读写:fio -filename=/dev/sdb -direct=1 -rw=randrw -bs=8K -numjobs=8 -runtime=180 -group_reporting -name=8KB_randrw_sdb -output=/tmp/8K_randrw_sdb.log -randrepeat=0 -norandommap&
4、大块1M顺序读:fio -filename=/dev/sdb -direct=1 -rw=read -bs=1m -numjobs=8 -runtime=180 -group_reporting -name=1M_read_sdb -output=/tmp/1M_read_sdb.log -randrepeat=0 -norandommap&
5、大块1M顺序写:fio -filename=/dev/sdb -direct=1 -rw=write -bs=1m -numjobs=8 -runtime=180 -group_reporting -name=1M_write_sdb -output=/tmp/1M_write_sdb.log -randrepeat=0 -norandommap&
总结以上论证就是说:存储的性能是由三个核心指标:iops、throughput、await来定义存储是不是有性能瓶颈,通过FIO工具可以很直观的展现。
听完博主的论文觉得前言太多了,赶紧进入主题吧!
疑问:iostat工具统计的存储使用率指标 %util能代表存储性能瓶颈吗?
先做一下性能数据收集,然后再仔细分析:
- linux查看磁盘block块大小:/sbin/tune2fs -l /dev/mapper/root_vg-varlv | grep "Block size"或者“stat filename |grep "IO Block"”。
- oracle数据库查看block块大小:show parameter db_block_size
- 通过命令实时查看磁盘负荷情况:iostat –xkd 1,输入如下信息:

还是重点关注3个性能核心指标:iops、throughput、await与多个任务指标。
iops : r/s每秒读处理的IO个数;
iops : w/s每秒写处理的IO个数;
throughput:rKB/s每秒从设备读取的千字节数;
throughput:wKB/s每秒写入设备的千字节数;
await:r_await每一个读IO请求的处理的响应时间,单位是毫秒;
await:w_await每一个写IO请求的处理的响应时间,单位是毫秒;
aqu-sz:表示磁盘I/O队列数;
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位);
%util: 单位时间内处理IO的时间比。例如:单位时间为间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%。
iostat和atop统计的IO对比:
数据处理次数iops:iostat.r/s ->atop.read
数据处理次数iops:iostat.w/s -> atop.write
吞吐量(带宽)throughput:iostat.rkB/s -> atop.MBr/s
吞吐量(带宽)throughput:iostat.wkB/s -> atop.MBw/s
响应时间 await:iostat.await -> atop.avio
单位时间内处理IO的时间比:iostat.%util-> atop.busy
I/O 等待队列长度: iostat.avgqu-sz -> atop.avq
平均 I/O 数据尺寸,每次请求的大小:iostat.avgrq-sz -> atop.KiB/r & KiB/w
如何通过以上指标数据判断磁盘有没有瓶颈呢?
- 查看await值,响应时间是不是长期响应慢,如果是那肯定有问题;
- 查看svctm的值与await很接近,说明IO任务提交之后,IO立即响应了,表示几乎没有I/O等待,磁盘性能很好,反之则有问题;
- 查看aqu-sz队列值,越小越好,反之差值越大,队列越大,说明有问题;
- 查看iops与业务block块大小对比FIO压测数据,看有没有到瓶颈;
- 将throughput数据相加(或者执行sar -n DEV 1 统计网口流量)与光纤能支持的网络带宽对比,看有没有到网络传输瓶颈。
总结:可以通过以上5点判断存储是否有瓶颈,查看%util值能说明设备的繁忙程度,磁盘繁忙不代表性能有问题,只能说明磁盘一直在IO读写。为什么磁盘读写这么繁忙,需要从业务属性去排查。以数据库场景为例,业务查询时:确定一下表数据是不是很大;SQL查询逻辑是否合理;是否有索引;字符集是否一致;内存页太小等都会占用资源,需要业务侧去排查。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)