Android面试题详解之算法和数据结构面试题汇总
也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。HashMap中默认的存储大小就是一个容量为16的数组,所以当我们创建出一个HashMap对象时,即使里面没有任何元素,也要分别一块内存空间给它,而且,我们再不断的向HashMap里put数据时,
正文
请说一说HashMap,SparseArrary原理,SparseArrary相比HashMap的优点、ConcurrentHashMap如何实现线程安全?
这道题想考察什么?
1、HashMap,SparseArrary基础原理?
2、SparseArrary相比HashMap的优点是什么?
3、ConcurrentHashMap如何实现线程安全?
考察的知识点
HashMap,SparseArrary、ConcurrentHashMap
考生如何回答
HashMap和SparseArray,都是用来存储Key-value类型的数据。
SparseArray和HashMap的区别:
双数组、删除O(1)、二分查找
- 数据结构方面:hashmap用的是链表。sparsearray用的是双数组。
- 性能方面:hashmap是默认16个长度,会自动装箱。如果key是int 的话,hashmap要先封装成Interger。sparseArray的话就就会直接转成int。所以spaseArray用的限制是key是int。数据量小于1k。如果key不是int小于1000的话。可以用Arraymap。
HashMap的基本原理
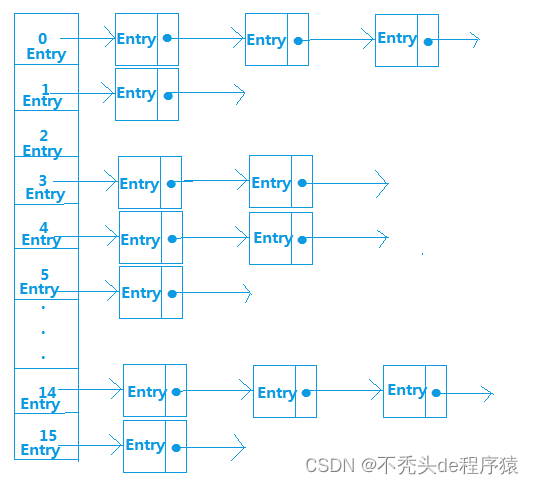
HashMap内部是使用一个默认容量为16的数组来存储数据的,而数组中每一个元素却又是一个链表的头结点,所以,更准确的来说,HashMap内部存储结构是使用哈希表的拉链结构(数组+链表)。

HashMap中默认的存储大小就是一个容量为16的数组,所以当我们创建出一个HashMap对象时,即使里面没有任何元素,也要分别一块内存空间给它,而且,我们再不断的向HashMap里put数据时,当达到一定的容量限制时,HashMap就会自动扩容。
SparseArray的基本原理
SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
private int[] mKeys;
private Object[] mValues;
我们可以看到,SparseArray只能存储key为int类型的数据,同时,SparseArray在存储和读取数据时候,使用的是二分查找法,
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}
也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
添加数据
public void put(int key, E value)
删除数据
public void remove(int key)
获取数据
public E get(int key)
public E get(int key, E valueIfKeyNotFound)
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内
- key必须为int类型,这中情况下的HashMap可以用SparseArray代替:
ConcurrentHashMap基本原理
-
JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry。
-
JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了。
-
JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表。

文末
更多的Android面试题可以扫描免费领取!

↓↓↓【预览】↓↓↓


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)