翻译:Time Series Anomaly Detection Algorithms(时间序列异常检测算法)
在 Statsbot 中, 我们不断回顾了异常检测方法的发展,并在此基础上重新完善了我们的模型。本文概述了最常用的时间序列异常检测算法及其优缺点。本文针对的是只想了解一下异常检测技术现状的无经验读者。我们不想用复杂的数学模型来唬人,所以我们把所有的数学原理推导都放在下面的推荐链接里面了。
在 Statsbot 中, 我们不断回顾了异常检测方法的发展,并在此基础上重新完善了我们的模型。
本文概述了最常用的时间序列异常检测算法及其优缺点。
本文针对的是只想了解一下异常检测技术现状的无经验读者。我们不想用复杂的数学模型来唬人,所以我们把所有的数学原理推导都放在下面的推荐链接里面了。
重要的异常类型
时间序列的异常检测问题通常表示为相对于某些标准信号或常见信号的离群点。虽然有很多的异常类型,但是我们只关注业务角度中最重要的类型,比如意外的峰值、下降、趋势变化以及等级转换。
想象一下,你在自己的网站上跟踪用户数量,发现用户在短时间内出现了意想不到的增长,看起来就像一个峰值。这些类型的异常通常称为附加异常。
关于网站的另一个例子是,当你的服务器宕机时,你会看到在短时间内有零个或者非常少的用户访问。这些类型的异常通常被分类为时间变化异常。
在你处理一些关于转化率问题时,转化率可能会下降。如果发生这种情况,目标度量通常不会改变信号的形状,而是改变在一段时间内它的总价值。根据变化的性质,这些类型的变化通常被称为水平位移或季节性水平位移异常。
通常,异常检测算法应该将每个时间点标记为异常/非异常,或者预测某个点的信号,并衡量这个点的真实值与预测值的差值是否足够大,从而将其视为异常。
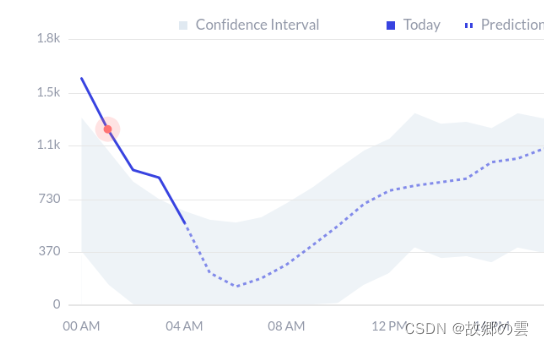
使用后面的方法,你将能够得到一个可视化的置信区间,这有助于理解为什么会出现异常并进行验证。

Statsbot 的异常报告显示,实际的时间序列、预测的时间序列和置信区间有助于理解异常发生的原因。
让我们从应用的角度来回顾一下这两种算法类型,以及找到各类型的异常值。
STL 分解
STL 表示基于损失的季节性分解的过程。该技术能够将时间序列信号分解为三个部分:季节性变化(seasonal)、趋势变化(trend)和剩余部分(residue)。

由上到下依次为:原始时间序列和使用 STL 分解得到的季节变化部分、趋势变化部分以及残差部分。
顾名思义,这种方法适用于季节性的时间序列,这是比较常见的情况。
分析残差的偏差,然后引入残差阈值,这样就能得到一种异常检测得算法。
这里不太明显的地方是,我们为了得到更可靠的异常检测结果,使用了绝对中位偏差。该方法目前最好的实现是 Twitter 的异常检测库,它使用了 Generalized Extreme Student Deviation(广义的 ESD 算法)测试残差点是否是一个离群点。
优点
该方法的优点在于其简单性和健壮性。它可以处理很多不同的情况,并且所有的异常情况仍然可以直观解释。
它主要擅长于附加的异常值检测。如果想要检测一些水平变化,则可以对移动平均信号进行分析。
缺点
该方法的缺点是在调整选项方面过于死板。你所能做的只有通过显著性水平来调整置信区间。
当信号特征发生了剧烈变化时,该方法就失效了。例如,跟踪原本对公众是关闭状态的,却突然对公众开放的网站用户数量。在这种情况下,就应该分别跟踪在启动开放之前和开放之后发生的异常。
分类回归树
分类回归树(CART)是目前最稳健、最有效的机器学习技术之一。它也可以应用于异常检测问题。
首先,可以使用监督学习来训练分类树对异常和非异常数据点进行分类。这里需要标记好的异常数据点。
第二种方法,可以使用无监督学习算法来训练 CART 来预测时序数据的下一个数据点,得到和 STL 分解方法类似的置信区间或预测误差。然后使用广义的 ESD 算法来测试或者使用 Grubbs 检验算法来检查数据点是否位于置信区间之内。
实际的时序数据(绿色),CART 模型预测的时序数据(蓝色),异常检测算法检测到的异常。
分类树学习的最流行实现是 xgboost 库。
优点
这种方法的优点是它不受信号结构的任何约束,而且可以引入许多的特征参数进行学习,以获得更为复杂的模型。
缺点
该方法的缺点是会出现越来越多的特征,这很快会影响到整体的计算性能。在这种情况下,你应该有意识地选择有效特征。
ARIMA 模型
自回归移动平均模型(ARIMA)是一种设计上非常简单的方法,但其效果足够强大,可以预测信号并发现其中的异常。
该方法的思路是从过去的几个数据点来生成下一个数据点的预测,在过程中添加一些随机变量(通常是添加白噪声)。以此类推,预测得到的数据点可以用来生成新的预测。很明显:它会使得后续预测信号数据更平滑。
使用这种方法最困难的部分是选择差异数量、自动回归数量和预测误差系数。
每次使用新信号时,你都应该构建一个新的 ARIMA 模型。
该方法的另一个障碍是信号经过差分后应该是固定的。也就是说,这意味着信号不应该依赖于时间,这是一个比较显著的限制。
异常检测是利用离群点来建立一个经过调整的信号模型,然后利用 t-统计量来检验该模型是否比原模型能更好的拟合数据。
利用原始 ARIMA 模型和对异常值进行调整的 ARIMA 模型构建的两个时间序列。
该方法最受欢迎的实现是 R 语言中的 tsoutliers 包。在这种情况下,你可以找到适合信号的 ARIMA 模型,它可以检测出所有类型的异常。
指数平滑方法
指数平滑方法与 ARIMA 方法非常相似。基本的指数模型等价于 ARIMA (0, 1, 1) 模型。
从异常检测的角度来看,最有趣的方法是 Holt-Winters 季节性方法。该方法需要定义季节性周期,比如周、月、年等等。
如果需要跟踪多个季节周期,比如同时跟踪周和年周期,那么应该只选择一个。通常是选择最短的那个:所以这里我们就应该选择周季节。
这显然是该方法的一个缺点,它会大大影响整体的预测范围。
和使用 STL 或 CARTs 方法一样,我们可以通过统计学方法对离群值进行统计来实现异常检测。
神经网络
与 CART 方法一样,神经网络有两种应用方式:监督学习和无监督学习。
我们处理的数据是时间序列,所以最适合的神经网络类型是 LSTM。如果构建得当,这种循环神经网络将可以建模实现时间序列中最复杂的依赖关系,包括高级的季节性依赖关系。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)