细胞实例分割:DoNet: Deep De-overlapping Network for Cytology Instance Segmentation 论文阅读笔记
首先表明细胞分割对于生物分析和癌症监视有着重要作用,接着指出现有的一些挑战:大量的半透明细胞簇重叠使得彼此边界混乱;原子核拟态和碎片存在混淆(太专业的术语不好翻译)。于是本文提出一种解耦合-重组策略:De-overlapping Network (DoNet):提出一种双路径区域分割模块来显式地将细胞簇解耦合为交叉区域;提出一种重组模块来引导整合语义一致性的互补区域;
细胞实例分割:DoNet: Deep De-overlapping Network for Cytology Instance Segmentation 论文阅读笔记
写在前面
新的一周又开始了,冲冲冲~
这是一篇关于医学图像处理的实例分割文章,博主也是第一次阅读这种类型的论文,增长见识,顺便可以和那些医学生们联系联系,整点文章~
- 论文地址:DoNet: Deep De-overlapping Network for Cytology Instance Segmentation
- 代码地址:https://github.com/DeepDoNet/DoNet
- 收录于:CVPR 2023
- PS:2023 年每周一篇博文,主页更多干货,欢迎关注,4千粉丝期待有你呦~
一、Abstract
首先表明细胞分割对于生物分析和癌症监视有着重要作用,接着指出现有的一些挑战:大量的半透明细胞簇重叠使得彼此边界混乱;原子核拟态和碎片存在混淆(太专业的术语不好翻译)。于是本文提出一种解耦合-重组策略:De-overlapping Network (DoNet):提出一种双路径区域分割模块来显式地将细胞簇解耦合为交叉区域;提出一种重组模块来引导整合语义一致性的互补区域;设计一种 Mask 引导的区域提议策略 Mask-guided Region Proposal Strategy (MRP) 来整合细胞注意力图,用于细胞内的实例预测。数据集采用 ISBI2014、CPS。
二、引言
首先指出细胞分割的重要作用,表明问题:数以千计的细胞天然的堆叠,从而造成内部或者外部间的变动。话题一转,表明细胞分割技术的底层重要性。顺势指出现有方法存在的问题:细胞间天然聚集从而导致过度重叠、边界不清晰;背景像素存在很强的干扰,例如气泡等。像 Mask R-CNN 的方法未能建模半透明细胞簇中交互区域和互补区域的联系,从而使得这种跨区域的分割性能不佳。
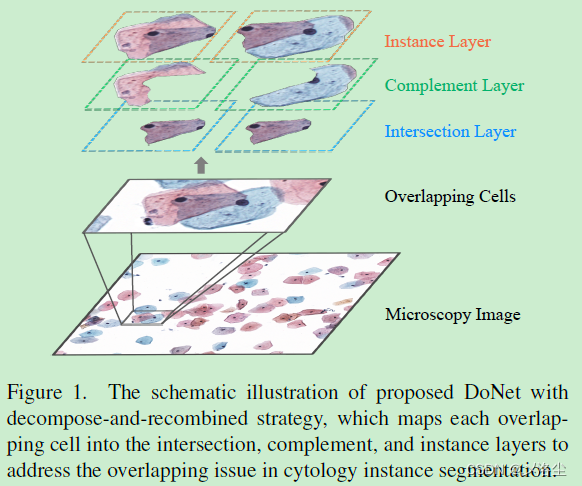
本文提出一种解耦合-重组的策略用于半透明细胞实例分割,名为 De-overlapping Network (DoNet),如下图所示:

对于每个具有多个蜂窝状子区域的细胞簇来说,DoNet 首先通过预测细胞簇的 Mask 来隐式地学习子区域内的隐藏交互,然后通过交互层、互补层、实例层,显式地建模其中的组成成分以及彼此关系。
具体来说,首先采用 Mask R-CNN 得到粗糙的预测图,之后跟着一个双路径区域分割模块 Dual-path Region segmentation Module (DRM) 。之后结合第一阶段的特征以及粗糙的 masks,从而将细胞簇解耦合到交互的以及互补的子区域。然后采用语义一致引导重组模块 semantic Consistency-guided Recombination Module (CRM) 对齐精细化的实例与子区域内的预测 mask。最后采用提出的 Mask 引导的区域提议模块 Mask-guided Region Proposal Module (MRP) 使得模型重点关注于细胞簇内的区域。
贡献总结如下:
- 提出一种解耦合-重组策略的降重叠网络用于细胞实例分割,提出 DRM 解耦合所有的细胞区域,CRM 隐式、显式地建模细胞组成部分的交互、互补关系;
- 提出 mask 引导的区域提议模块 MRP,利用细胞注意力图来细化内部细胞簇,施加细胞簇的先验信息到模块内,缓解背景干扰带来的影响;
- 在 ISBI2014、CPS 数据集上表现很好。
三、相关工作
细胞学实例分割
主要存在的挑战:例如在 ISBI2014 数据集中:细胞聚集成簇、剧烈的背景噪声干扰、半透明重叠的细胞区域。有两种解决这一问题的方式:先分割-后精炼,端到端的训练。但是仍缺乏必要的对重叠区域的感知能力,导致出现混乱的细胞边界。本文提出一种去重叠网络 DoNet,来隐式地或显式地建模完整的实例及其子区域。
遮挡实例分割
像 Mask R-CNN 并不能解决遮挡问题,于是具有能够感知和推理能力的模型出现了,称之为 amodal perception,相应的实例分割模型称之为 amodal instance segmentation,例如 Occlusion R-CNN (ORCNN) 、BCNet、ASBU。
这些模型本质上旨在增强 amodal 的感知和推理能力。这些方法重点关注从部分可见区域中推理到不可见区域,而本文提出的方法旨在解决交互区域和互补区域的不一致问题。
四、方法
4.1 预览
问题概述
给定包含 K K K 张图像的数据集,对应的标注为 D = { ( X k , Y k ) } k = 1 K \mathcal{D}=\left\{\left(\mathcal{X}_{k},\mathcal{Y}_{k}\right)\right\}_{k=1}^K D={(Xk,Yk)}k=1K,其中每个标注包含 bounding boxes(BBox) B k = { b k , i } i = 1 N k \mathcal{B}_k=\{b_{k,i}\}_{i=1}^{N_k} Bk={bk,i}i=1Nk,目标类别 C k = { c k , i } i = 1 N k \mathcal{C}_k=\{c_{k,i}\}_{i=1}^{N_k} Ck={ck,i}i=1Nk,相应的实例 mask E k = { e k , i } i = 1 N k \mathcal{E}_k=\{e_{k,i}\}_{i=1}^{N_k} Ek={ek,i}i=1Nk,其中 N k N_k Nk 为第 k k k 张图像的实例数量。本文重点关注分割细胞实例 c k , i ∈ { nuclei , cytoplasm } c_{k,i}\in\{\text{nuclei},\text{cytoplasm}\} ck,i∈{nuclei,cytoplasm} 中的细胞核和细胞质。对于每一个细胞簇,基于其细胞间的位置关系,通过逻辑操作将其 Mask 解耦合为交集区域 O k = { o k , i } i = 1 N k \mathcal{O}_k=\{o_k,i\}_{i=1}^{N_k} Ok={ok,i}i=1Nk 和互补区域 M k = { m k , i } i = 1 N k \mathcal{M}_k=\{m_{k,i}\}_{i=1}^{N_k} Mk={mk,i}i=1Nk,从而建模彼此之间的关系。
工作流程

采用 Mask R-CNN 为基础模型,后面跟着 Dual-path Region segmentation Module (DRM):将实例特征作为交互层和互补层的输入来预测细胞质的交集区域
O
^
k
,
i
\hat{O}_{k,i}
O^k,i 和互补区域
m
^
k
,
i
\hat{m}_{k,i}
m^k,i。然后根据相应的位置关系解耦合后,采用一致性引导的重组模块和 RoIAlign 模块来归一化 DRM 的输出实例特征,并产生重组后的 masks
e
^
k
,
i
r
\hat{e}^r_{k,i}
e^k,ir。之后,重组后的细胞质 mask 通过 Mask-guided
Region Proposal (MRP) 作为先验信息用于细胞簇内的目标检测。
粗糙的 Mask 分割
讲述下 Mask R-CNN 的流程:FPN + RPN,通过 RoIAlign 产生 RoI 特征
f
k
,
i
r
o
i
f_{k,i}^{roi}
fk,iroi,通过检测头产生类别
c
^
k
,
i
\hat{c}_{k,i}
c^k,i 和 BBox
b
^
k
,
i
\hat{b}_{k,i}
b^k,i,通过实例 Mask 头产生
e
^
k
,
i
c
\hat{e}^c_{k,i}
e^k,ic。其中
e
^
k
,
i
c
\hat{e}^c_{k,i}
e^k,ic 可能包含混乱的边界,于是将
e
^
k
,
i
c
\hat{e}^c_{k,i}
e^k,ic 视为粗糙的 Mask,为后续的 DRM 子区域解耦合提供先验信息并抑制背景噪声。训练损失如下:
L
c
o
a
r
s
e
=
L
r
e
g
+
L
c
l
s
+
L
c
m
a
s
k
\mathcal L_{coarse}=\mathcal L_{reg}+\mathcal L_{cls}+\mathcal L_{cmask}
Lcoarse=Lreg+Lcls+Lcmask其中
L
r
e
g
L_{reg}
Lreg 为 BBox 回归损失,smooth-L1,
L
c
l
s
L_{cls}
Lcls 为类别分类的 cross-entropy(CE) 损失,
L
c
m
a
s
k
L_{cmask}
Lcmask 为分割的逐像素 CE 损失。
4.2 解耦合和重组策略
双路径区域分割模块 Dual-path Region Segmentation Module (DRM)
DRM 由一个交互 Mask 头
H
o
H_o
Ho 和一个同样结构的互补 Mask 头
H
m
H_m
Hm 组成。令
f
k
,
i
c
f_{k,i}^{c}
fk,ic 表示 Mask 头输入的语义特征。
H
o
H_o
Ho 和
H
m
H_m
Hm 采用拼接后的
f
k
,
i
r
o
i
f_{k,i}^{roi}
fk,iroi 和
f
k
,
i
c
f_{k,i}^{c}
fk,ic 作为输入,来预测细胞簇中的交集和互补区域
o
^
k
,
i
\hat {o}_{k,i}
o^k,i,
m
^
k
,
i
\hat{m}_{k,i}
m^k,i。具体来说,每个头由 4 个卷积层组成,产生
14
×
14
×
256
14\times14\times256
14×14×256 的特征,接着一个反卷积层生成
28
×
28
×
1
28\times28\times1
28×28×1 的语义 mask。在所有头中增加逐像素 CE 损失来显式地构建解耦合:
L
d
e
c
=
1
K
∑
k
=
1
K
1
N
k
∑
i
=
1
N
k
(
L
c
e
(
o
^
k
,
i
,
o
k
,
i
)
+
L
c
e
(
m
^
k
,
i
,
m
k
,
i
)
)
\mathcal{L}_{dec}=\frac{1}{K}\sum_{k=1}^{K}\frac{1}{N_k}\sum_{i=1}^{N_k}\left(\mathcal{L}_{ce}(\hat{o}_{k,i},o_{k,i})+\mathcal{L}_{ce}(\hat{m}_{k,i},m_{k,i})\right)
Ldec=K1k=1∑KNk1i=1∑Nk(Lce(o^k,i,ok,i)+Lce(m^k,i,mk,i))
语义一致性引导的重组模块 Semantic Consistency-guided Recombination Module (CRM)
令
f
k
,
i
o
f_{k,i}^{o}
fk,io 和
f
k
,
i
m
f_{k,i}^{m}
fk,im 分别表示交互 mask 头和互补 mask 头最后一层之前的输入特征,这两种特征作为残差信息而融合到
f
k
,
i
r
o
i
f_{k,i}^{roi}
fk,iroi 中,之后输入给 mask 头。然后复用 Mash 头
H
i
H_i
Hi 来预测整个的实例。CRM 产生的精细化的 mask
e
^
k
,
i
r
\hat {e}_{k,i}^r
e^k,ir 采用分割损失
L
r
m
a
s
k
\mathcal{L}_{rmask}
Lrmask 优化:
L
r
m
a
s
k
=
1
K
∑
k
=
1
K
1
N
k
∑
i
=
1
N
k
L
c
e
(
e
^
k
,
i
r
,
e
k
,
i
)
\mathcal{L}_{rmask}=\frac{1}{K}\sum_{k=1}^K\frac{1}{N_k}\sum_{i=1}^{N_k}\mathcal{L}_{ce}(\hat{e}_{k,i}^r,e_{k,i})
Lrmask=K1k=1∑KNk1i=1∑NkLce(e^k,ir,ek,i)此外,在重组的 mask
e
^
k
,
i
r
\hat {e}_{k,i}^r
e^k,ir 和融合
o
^
k
,
i
\hat {o}_{k,i}
o^k,i 以及
m
^
k
,
i
\hat {m}_{k,i}
m^k,i 的预测间增加一个语义一致性正则化:
L
c
o
n
s
=
1
K
∑
k
=
1
K
1
N
k
∑
i
=
1
N
k
L
c
e
(
e
^
k
,
i
r
,
F
m
e
r
g
e
(
o
^
k
,
i
,
m
^
k
,
i
)
)
\mathcal{L}_{cons}=\frac{1}{K}\sum_{k=1}^{K}\frac{1}{N_k}\sum_{i=1}^{N_k}\mathcal{L}_{ce}\big(\hat{e}_{k,i}^r,\mathcal{F}_{merge}\big(\hat{o}_{k,i},\hat{m}_{k,i}\big)\big)
Lcons=K1k=1∑KNk1i=1∑NkLce(e^k,ir,Fmerge(o^k,i,m^k,i))其中
F
m
e
r
g
e
\mathcal{F}_{merge}
Fmerge 表示交集区域与互补区域在融合单元
x
o
r
(
)
xor()
xor() 上的融合操作,之后两个子区域的 mask 穿过 Sigmoid 函数用于正则化。然后计算两个 Mask logits 的掩码异或,以合并彼此并抑制冗余的像素。
4.3 Mask 引导的区域提议 Mask-guided Region Proposal
进一步提出 Mask 引导的区域提议 Mask-guided Region Proposal (MRP) 来促进模型在细胞簇区域内部生成原子级别的 Proposals。
对每个图像,在 CRM 中,聚合所有的重组实例预测
e
^
k
,
i
r
\hat{e}_{k,i}^r
e^k,ir 到一个语义 mask
M
^
k
\hat {M}_k
M^k。然后根据 BBox 预测
b
^
k
,
i
\hat{b}_{k,i}
b^k,i 将其映射并求和,得到原始的预测。之后跟着一个 Sigmoid 函数归一化到概率图
M
^
k
\hat {M}_k
M^k,最后通过原始 FPN 中的逐元素乘积对特征
f
k
f_k
fk 进行加权:
f
k
w
=
M
^
k
∘
f
k
f_k^w=\hat{M}_k\circ f_k
fkw=M^k∘fk其中
f
k
w
f_k^w
fkw 为 MRP 中用于原子级别预测的重加权后的特征。于是细胞外的像素被抑制,减少了假阳性样本。此外,MRP 在不同阶段建立了信息交互,自然促进了信息的表示能力。
4.4 端到端学习
用合成的细胞簇拓展数据集
半透明的细胞特性减轻了高度重叠的影响,但是标注以及标注中存在的噪声使得建立大规模数据集很难。
为解决这一问题,本文提出一种实例增强方法用于重叠的细胞数据增强,能够产生大量的合成细胞簇,并且可以基于标注的细胞簇实例,自由地控制重叠比率和透明度。但为了公平,在下面的比较中并未使用这一合成数据集。
整体损失函数
以监督方式训练提出的细胞实例分割框架:
L
=
L
c
o
a
r
s
e
+
λ
d
e
c
L
d
e
c
+
λ
r
m
a
s
k
L
r
m
a
s
k
+
λ
c
o
n
s
L
c
o
n
s
\mathcal{L}=\mathcal{L}_{coarse}+\lambda_{dec}\mathcal{L}_{dec}+\lambda_{rmask}\mathcal{L}_{rmask}+\lambda_{cons}\mathcal{L}_{cons}
L=Lcoarse+λdecLdec+λrmaskLrmask+λconsLcons其中
L
c
o
a
r
s
e
\mathcal{L}_{coarse}
Lcoarse 为用于 RoI 提取和粗糙预测的 mask 预测损失,
L
d
e
c
\mathcal{L}_{dec}
Ldec 为交叉区域和互补区域分割图的解耦合损失,
L
r
m
a
s
k
\mathcal{L}_{rmask}
Lrmask 为细化后的 mask 分割损失,
L
c
o
n
s
\mathcal{L}_{cons}
Lcons 为整个实例和子区域的语义一致损失,
λ
d
e
c
\lambda_{dec}
λdec、
λ
r
m
a
s
k
\lambda_{rmask}
λrmask、
λ
c
o
n
s
\lambda_{cons}
λcons 为分别控制每个部分的超参数。
五、实验
5.1 实验设置
- 数据集:ISBI2014、CPS;
- 评估指标:aggregated Jaccard index (AJI)、average Dice coefficient (Dice)、F1-score (F1)、mean of Average Precision (mAP)、object-based false negative rate ( FN o {\text{FN}_o} FNo)、pixel-based true positive rate ( TP p {\text{TP}_p} TPp)。
实施细节
采用 Mask R-CNN、Detectron2、ResNet-50-based FPN、SGD 0.9、初始学习率 0.001,1K warm-up,60k 迭代,50K 和 55K,分别衰减 0.1 倍。
5.2 结果


5.3 消融实验
网络组件的作用

DRM 的设计选择

CRM 的设计选择
同上表 4。

5.4 定性分析和讨论


六、结论
本文提出一种降重叠网络 DoNet 来解决细胞实例分割中的重叠问题。DoNet 通过显式或隐式地建模细胞簇区域和整个细胞的的交互,从而增强模型对于重叠区域的感知能力。大量的实验表明了 DoNet 效果很好,且能泛化到一般的视觉应用场景上。
写在后面
这篇文章里面的一些关于细胞学的专业名词不是很懂,留下了方便询问医学生的机会,哈哈。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)