Athena SQL报错:must be an aggregate expression or appear in GROUP BY clause
其实,我们并不能用平时在navicat、javaDao写的MySQL语句和Athena SQL相提并论。归根结底就是“Athena SQL一般是大数据查询,所以会严格。
疑问:为什么Athena SQL要求select子句的字段一定是聚合函数或必须出现在group by中。
其实,我们并不能用平时在navicat、javaDao写的MySQL语句和Athena SQL相提并论。归根结底就是“Athena SQL一般是大数据查询,所以会严格。”
一、举例,如有下一张表和查询语句:

SELECT
EVENTS,
version
FROM
system_memory_available
GROUP BY
version
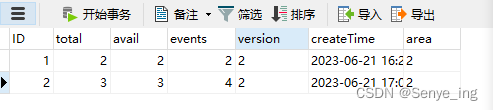
1、在navicat的查询结果:

2、而在Athena中,以上sql会报错,指出“events 一定得是一个聚合函数或者必须出现在GROUP BY子句中”
在Athena中修正后的sql:
SELECT
EVENTS,
version
FROM
system_memory_available
GROUP BY
version,
EVENTS
相应执行结果(因为举例,所以结果截图使用navicat的):

二、原因
其实我们本意是想按照version分组,但是表中version对应着两个events,那么group by version的时候它应该展示哪个evnets呢?
从上面各自的执行的结果知道,MySQL直接是顺序优先显示第一个,而Athena会要求你进一步去分组。
除了书写规范原因,另外一个是,select子句的字段要求出现在group by中可以减少查询结果行数,防止冗余数据。
三、也可以深入从执行角度去了解。
执行顺序:
from——>where——>group by——>select
要点:
1、使用聚合函数时,select子句中只能存在以下三种元素。
常数
聚合函数
聚合键
2、在GROUP BY子句中不能使用select子句中定义的列的别名。
由于group by子句的执行优先级高于select,因此如果在select中定义的列的别名,group by子句并不知道。
3、GROUP BY子句的结果是随机的。
4、WHERE子句中不能使用聚合函数,只有SELECT子句、HAVING子句和ORDER BY中才能使用聚合函数。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)