openEuler 20.03 LTS SP3 4.19.90内核与标准版4.19.113内核 distribute_cfs_runtime代码差异对比 ARM64
_lockfunc。
diff -y kernel/sched/fair.c
static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b
{ {
struct cfs_rq *cfs_rq; struct cfs_rq *cfs_rq;
u64 runtime; u64 runtime;
u64 starting_runtime = remaining; u64 starting_runtime = remaining;
rcu_read_lock(); rcu_read_lock();
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs
throttled_list) { throttled_list) {
struct rq *rq = rq_of(cfs_rq); struct rq *rq = rq_of(cfs_rq);
struct rq_flags rf; struct rq_flags rf;
rq_lock(rq, &rf); | rq_lock_irqsave(rq, &rf);
if (!cfs_rq_throttled(cfs_rq)) if (!cfs_rq_throttled(cfs_rq))
goto next; goto next;
/* By the above check, this should never be t /* By the above check, this should never be t
SCHED_WARN_ON(cfs_rq->runtime_remaining > 0); SCHED_WARN_ON(cfs_rq->runtime_remaining > 0);
runtime = -cfs_rq->runtime_remaining + 1; runtime = -cfs_rq->runtime_remaining + 1;
if (runtime > remaining) if (runtime > remaining)
runtime = remaining; runtime = remaining;
remaining -= runtime; remaining -= runtime;
cfs_rq->runtime_remaining += runtime; cfs_rq->runtime_remaining += runtime;
/* we check whether we're throttled above */ /* we check whether we're throttled above */
if (cfs_rq->runtime_remaining > 0) if (cfs_rq->runtime_remaining > 0)
unthrottle_cfs_rq(cfs_rq); unthrottle_cfs_rq(cfs_rq);
next: next:
rq_unlock(rq, &rf); | rq_unlock_irqrestore(rq, &rf);
if (!remaining) if (!remaining)
break; break;
} }
rcu_read_unlock(); rcu_read_unlock();
return starting_runtime - remaining; return starting_runtime - remaining;
} diff 对比
4600c4697
< rq_lock(rq, &rf);
---
> rq_lock_irqsave(rq, &rf);
4619c4716
< rq_unlock(rq, &rf);
---
> rq_unlock_irqrestore(rq, &rf);
4635c4732rq_lock函数在标准版4.19.113的实现
sched.h - kernel/sched/sched.h - Linux source code (v4.19.113) - Bootlin
static inline void
rq_lock(struct rq *rq, struct rq_flags *rf)
__acquires(rq->lock)
{
raw_spin_lock(&rq->lock);
rq_pin_lock(rq, rf);
}rq_lock_irqsave在欧拉4.19.90内核的实现与标准版4.19.113一致
sched.h - kernel/sched/sched.h - Linux source code (v4.19.113) - Bootlin
static inline void
rq_lock_irqsave(struct rq *rq, struct rq_flags *rf)
__acquires(rq->lock)
{
raw_spin_lock_irqsave(&rq->lock, rf->flags);
rq_pin_lock(rq, rf);
}
继续对比raw_spin_lock与raw_spin_lock_irqsave,参考《奔跑吧Linux内核》
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
#endifraw_spin_lock
spinlock.h - include/linux/spinlock.h - Linux source code (v4.19.113) - Bootlin
#define raw_spin_lock(lock) _raw_spin_lock(lock)spinlock.c - kernel/locking/spinlock.c - Linux source code (v4.19.113) - Bootlin
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
#endifspinlock_api_smp.h - include/linux/spinlock_api_smp.h - Linux source code (v4.19.113) - Bootlin
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}展开后的代码
static inline __attribute__((always_inline, unused)) __attribute__((no_instrument_function)) void __raw_spin_lock(raw_spinlock_t *lock)
{
__asm__ __volatile__("": : :"memory");
do { } while (0);
do_raw_spin_lock(lock);
}
preempt_disable()
CONFIG_PREEMPT_COUNT未定义
preempt.h - include/linux/preempt.h - Linux source code (v4.19.113) - Bootlin
#define preempt_disable() barrier()compiler-gcc.h - include/linux/compiler-gcc.h - Linux source code (v4.19.113) - Bootlin
#define barrier() __asm__ __volatile__("": : :"memory")raw_spin_lock_irqsave
CONFIG_INLINE_SPIN_LOCK_IRQSAVE=y
spinlock.c - kernel/locking/spinlock.c - Linux source code (v4.19.113) - Bootlin
#ifndef CONFIG_INLINE_SPIN_LOCK_IRQSAVE
unsigned long __lockfunc _raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
return __raw_spin_lock_irqsave(lock);
}
EXPORT_SYMBOL(_raw_spin_lock_irqsave);
#endifspinlock_api_smp.h - include/linux/spinlock_api_smp.h - Linux source code (v4.19.113) - Bootlin
static inline unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
unsigned long flags;
local_irq_save(flags);
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
/*
* On lockdep we dont want the hand-coded irq-enable of
* do_raw_spin_lock_flags() code, because lockdep assumes
* that interrupts are not re-enabled during lock-acquire:
*/
#ifdef CONFIG_LOCKDEP
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
#else
do_raw_spin_lock_flags(lock, &flags);
#endif
return flags;
}参考资料
关中断
可以通过下面两个函数中的其中任何一个 关闭当前处理器上的所有中断处理, 这两个函数定义在 <asm/system.h>中:
void local_irq_save(unsigned long flags);
void local_irq_disable(void);
local_irq_save的调用把当前的中断状态(开或关)保存到flags中,然后禁用当前处理器上的中断。注意, flags 被直接传递, 而不是通过指针来传递,这是由于 local_irq_save被实现为宏 。
local_irq_disable不保存状态而关闭本地处理器上的中断发送; 只有我们知道中断并未在其他地方被禁用的情况下,才能使用这个版本。
————————————————
版权声明:本文为CSDN博主「hello_courage」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012247418/article/details/104180225
展开后的代码
# 104 "./include/linux/spinlock_api_smp.h"
static inline __attribute__((always_inline, unused)) __attribute__((no_instrument_function)) unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
unsigned long flags;
do { do { ({ unsigned long __dummy; typeof(flags) __dummy2; (void)(&__dummy == &__dummy2); 1; }); flags = arch_local_irq_save(); } while (0); } while (0);
__asm__ __volatile__("": : :"memory");
do { } while (0);
# 119 "./include/linux/spinlock_api_smp.h"
do_raw_spin_lock_flags(lock, &flags);
return flags;
}差异部分源码:
unsigned long flags;
local_irq_save(flags);展开后
unsigned long flags;
do { do { ({ unsigned long __dummy; typeof(flags) __dummy2; (void)(&__dummy == &__dummy2); 1; }); flags = arch_local_irq_save(); } while (0); } while (0);arch_local_irq_save
irqflags.h - arch/arm64/include/asm/irqflags.h - Linux source code (v4.19.113) - Bootlin
/*
* CPU interrupt mask handling.
*/
static inline unsigned long arch_local_irq_save(void)
{
unsigned long flags;
asm volatile(
"mrs %0, daif // arch_local_irq_save\n"
"msr daifset, #2"
: "=r" (flags)
:
: "memory");
return flags;
}先把原来的daif (DAIF)寄存器值保存到flags,然后把2写入了daifset 寄存器,也就是屏蔽了除了debug 外所有的exception。
关于内联汇编:
- 先看输出部,%0操作数对应"=r" (flags),即flags变量,其中“=”表示被修饰的操作数的属性是只写,“r”表示使用一个通用寄存器。
- 接着看输入部,在上述例子中,输入部为空,没有指定参数。
- 最后看损坏部,以“memory”结束。
- 该函数主要用于把PSTATE寄存器中的DAIF域保存到临时变量flags中,然后关闭IRQ。
在Linux内核代码中常常会使用到GCC内联汇编,GCC内联汇编的格式如下。
__asm__ __volatile__(指令部: 输出部: 输入部: 损坏部)
GCC内联汇编在处理变量和寄存器的问题上提供了一个模板和一些约束条件。
- 在指令部(AssemblerTemplate)中数字前加上%,如%0、%1 等,表示需要使用寄存器的样板操作数。若指令部用到了几个不同的操作数,就说明有几个变量需要和寄存器结合。
- 指令部后面的输出部(OutputOperands)用于描述在指令部中可以修改的C语言变量以及约束条件。每个输出约束(constraint)通常以“=”或者“+”号开头,然后是一个字母(表示对操作数类型的说明),接着是关于变量结合的约束。输出部可以是空的。“=”号表示被修饰的操作数只具有可写属性,“+”号表示被修饰的操作数只具有可读可写属性。
- 输入部(InputOperands)用来描述在指令部只能读取的C语言变量以及约束条件。输入部描述的参数只有只读属性,不要试图修改输入部的参数内容,因为GCC编译器假定输入部的参数内容在内嵌汇编之前和之后都是一致的。在输入部中不能使用“=”或者“+”约束条件,否则编译器会报错。另外,输入部可以是空的。
- 损坏部(Clobbers)一般以“memory”结束。“memory”告诉GCC编译器,内联汇编代码改变了内存中的值,强迫编译器在执行该汇编代码前存储所有缓存的值,在执行完汇编代码之后重新加载该值,目的是防止编译乱序。“cc”表示内嵌代码修改了状态寄存器的相关标志位。
参考:
浅谈 arch_local_irq_save 及arm64 debug exceptions_朝搴夕揽的博客-CSDN博客GCC内联汇编常见陷阱 - 知乎浅谈 arch_local_irq_save 及arm64 debug exceptions_朝搴夕揽的博客-CSDN博客
do_raw_spin_lock_flags
CONFIG_DEBUG_SPINLOCK is not set
spinlock.h - include/linux/spinlock.h - Linux source code (v4.19.113) - Bootlin
static inline void
do_raw_spin_lock_flags(raw_spinlock_t *lock, unsigned long *flags) __acquires(lock)
{
__acquire(lock);
arch_spin_lock_flags(&lock->raw_lock, *flags);
}__acquire(lock); 用于编译阶段检查锁成对,即加锁、解锁成对(具体后续研究?)
spinlock.h - include/linux/spinlock.h - Linux source code (v4.19.113) - Bootlin
#define arch_spin_lock_flags(lock, flags) arch_spin_lock(lock)qspinlock.h - include/asm-generic/qspinlock.h - Linux source code (v4.19.113) - Bootlin
#define arch_spin_lock(l) queued_spin_lock(l)qspinlock.h - include/asm-generic/qspinlock.h - Linux source code (v4.19.113) - Bootlin
/**
* queued_spin_lock - acquire a queued spinlock
* @lock: Pointer to queued spinlock structure
*/
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
u32 val;
val = atomic_cmpxchg_acquire(&lock->val, 0, _Q_LOCKED_VAL);
if (likely(val == 0))
return;
queued_spin_lock_slowpath(lock, val);
}
atomi_cmpchg_acquire
atomic.h - arch/arm64/include/asm/atomic.h - Linux source code (v4.19.113) - Bootlin
#define atomic_cmpxchg_acquire(v, old, new) \
cmpxchg_acquire(&((v)->counter), (old), (new))cmpxchg.h - arch/arm64/include/asm/cmpxchg.h - Linux source code (v4.19.113) - Bootlin
#define cmpxchg_acquire(...) __cmpxchg_wrapper(_acq, __VA_ARGS__)cmpxchg.h - arch/arm64/include/asm/cmpxchg.h - Linux source code (v4.19.113) - Bootlin
#define __cmpxchg_wrapper(sfx, ptr, o, n) \
({ \
__typeof__(*(ptr)) __ret; \
__ret = (__typeof__(*(ptr))) \
__cmpxchg##sfx((ptr), (unsigned long)(o), \
(unsigned long)(n), sizeof(*(ptr))); \
__ret; \
})展开__cmpxchg_acq
# 140 "./arch/arm64/include/asm/cmpxchg.h"
static inline __attribute__((always_inline, unused)) __attribute__((no_instrument_function)) __attribute__((always_inline)) unsigned long __cmpxchg_acq(volatile void *ptr, unsigned long old, unsigned long new, int size) { switch (size) { case 1: return __cmpxchg_case_acq_1(ptr, (u8)old, new); case 2: return __cmpxchg_case_acq_2(ptr, (u16)old, new); case 4: return __cmpxchg_case_acq_4(ptr, old, new); case 8: return __cmpxchg_case_acq_8(ptr, old, new); default: do { extern void __compiletime_assert_141(void) __attribute__((error("BUILD_BUG failed"))); if (!(!(1))) __compiletime_assert_141(); } while (0); } do { ; asm volatile(""); __builtin_unreachable(); } while (0); }
发现源码位于arch/arm64/include/asm/cmpxchg.h
cmpxchg.h - arch/arm64/include/asm/cmpxchg.h - Linux source code (v4.19.113) - Bootlin
#define __CMPXCHG_GEN(sfx) \
static __always_inline unsigned long __cmpxchg##sfx(volatile void *ptr, \
unsigned long old, \
unsigned long new, \
int size) \
{ \
switch (size) { \
case 1: \
return __cmpxchg_case##sfx##_1(ptr, (u8)old, new); \
case 2: \
return __cmpxchg_case##sfx##_2(ptr, (u16)old, new); \
case 4: \
return __cmpxchg_case##sfx##_4(ptr, old, new); \
case 8: \
return __cmpxchg_case##sfx##_8(ptr, old, new); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}arm64平台下指针长度8字节,int占4字节,参考如下测试
#include<stdio.h>
typedef struct {
int counter;
} atomic_t;
void main(){
atomic_t xx;
printf("%d, %d\n", sizeof(xx), sizeof(&xx));
}
[root@localhost tmp]# ./a.out
4, 8
则入参 sizeof(*(ptr)) = 4
进入case 4处理逻辑
__cmpxchg_case_acq_4
宏展开kernel/locking/spinlock.c,查找
# 473 "./arch/arm64/include/asm/atomic_lse.h"
static inline __attribute__((always_inline, unused)) __attribute__((no_instrument_function)) unsigned long __cmpxchg_case_acq_4(volatile void *ptr, unsigned long old, unsigned long new) { register unsigned long x0 asm ("x0") = (unsigned long)ptr; register unsigned long x1 asm ("x1") = old; register unsigned long x2 asm ("x2") = new; asm volatile(".if ""1"" == 1\n" "661:\n\t" "bl\t" "__ll_sc___cmpxchg_case_acq_4" "\n" ".rept " "2" "\nnop\n.endr\n" "\n" "662:\n" ".pushsection .altinstructions,\"a\"\n" " .word 661b - .\n" " .word 663f - .\n" " .hword " "5" "\n" " .byte 662b-661b\n" " .byte 664f-663f\n" ".popsection\n" ".pushsection .altinstr_replacement, \"a\"\n" "663:\n\t" " mov " "w" "30, %" "w" "[old]\n" " cas" "a" "" "\t" "w" "30, %" "w" "[new], %[v]\n" " mov %" "w" "[ret], " "w" "30" "\n" "664:\n\t" ".popsection\n\t" ".org . - (664b-663b) + (662b-661b)\n\t" ".org . - (662b-661b) + (664b-663b)\n" ".endif\n" : [ret] "+r" (x0), [v] "+Q" (*(unsigned long *)ptr) : [old] "r" (x1), [new] "r" (x2) : "x16", "x17", "x30", "memory"); return x0; }atomic_lse.h - arch/arm64/include/asm/atomic_lse.h - Linux source code (v4.19.113) - Bootlin
__CMPXCHG_CASE(w, b, 1, )atomic_lse.h - arch/arm64/include/asm/atomic_lse.h - Linux source code (v4.19.113) - Bootlin
#define __CMPXCHG_CASE(w, sz, name, mb, cl...) \
static inline unsigned long __cmpxchg_case_##name(volatile void *ptr, \
unsigned long old, \
unsigned long new) \
{ \
register unsigned long x0 asm ("x0") = (unsigned long)ptr; \
register unsigned long x1 asm ("x1") = old; \
register unsigned long x2 asm ("x2") = new; \
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
__LL_SC_CMPXCHG(name) \
__nops(2), \
/* LSE atomics */ \
" mov " #w "30, %" #w "[old]\n" \
" cas" #mb #sz "\t" #w "30, %" #w "[new], %[v]\n" \
" mov %" #w "[ret], " #w "30") \
: [ret] "+r" (x0), [v] "+Q" (*(unsigned long *)ptr) \
: [old] "r" (x1), [new] "r" (x2) \
: __LL_SC_CLOBBERS, ##cl); \
\
return x0; \
}atomic_cmpxchg_acquire arm64架构下的源码已经挖到底了,ARM64汇编后续分析。
queued_spin_lock_slowpath
qspinlock.c - kernel/locking/qspinlock.c - Linux source code (v4.19.113) - Bootlin
/**
* queued_spin_lock_slowpath - acquire the queued spinlock
* @lock: Pointer to queued spinlock structure
* @val: Current value of the queued spinlock 32-bit word
*
* (queue tail, pending bit, lock value)
*
* fast : slow : unlock
* : :
* uncontended (0,0,0) -:--> (0,0,1) ------------------------------:--> (*,*,0)
* : | ^--------.------. / :
* : v \ \ | :
* pending : (0,1,1) +--> (0,1,0) \ | :
* : | ^--' | | :
* : v | | :
* uncontended : (n,x,y) +--> (n,0,0) --' | :
* queue : | ^--' | :
* : v | :
* contended : (*,x,y) +--> (*,0,0) ---> (*,0,1) -' :
* queue : ^--' :
*/
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 old, tail;
int idx;
BUILD_BUG_ON(CONFIG_NR_CPUS >= (1U << _Q_TAIL_CPU_BITS));
if (pv_enabled())
goto pv_queue;
if (virt_spin_lock(lock))
return;
/*
* Wait for in-progress pending->locked hand-overs with a bounded
* number of spins so that we guarantee forward progress.
*
* 0,1,0 -> 0,0,1
*/
if (val == _Q_PENDING_VAL) {
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,
(VAL != _Q_PENDING_VAL) || !cnt--);
}
/*
* If we observe any contention; queue.
*/
if (val & ~_Q_LOCKED_MASK)
goto queue;
/*
* trylock || pending
*
* 0,0,0 -> 0,0,1 ; trylock
* 0,0,1 -> 0,1,1 ; pending
*/
val = queued_fetch_set_pending_acquire(lock);
/*
* If we observe any contention; undo and queue.
*/
if (unlikely(val & ~_Q_LOCKED_MASK)) {
if (!(val & _Q_PENDING_MASK))
clear_pending(lock);
goto queue;
}
/*
* We're pending, wait for the owner to go away.
*
* 0,1,1 -> 0,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all
* clear_pending_set_locked() implementations imply full
* barriers.
*/
if (val & _Q_LOCKED_MASK)
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
/*
* take ownership and clear the pending bit.
*
* 0,1,0 -> 0,0,1
*/
clear_pending_set_locked(lock);
qstat_inc(qstat_lock_pending, true);
return;
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
queue:
qstat_inc(qstat_lock_slowpath, true);
pv_queue:
node = this_cpu_ptr(&mcs_nodes[0]);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
node += idx;
/*
* Ensure that we increment the head node->count before initialising
* the actual node. If the compiler is kind enough to reorder these
* stores, then an IRQ could overwrite our assignments.
*/
barrier();
node->locked = 0;
node->next = NULL;
pv_init_node(node);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/
if (queued_spin_trylock(lock))
goto release;
/*
* Ensure that the initialisation of @node is complete before we
* publish the updated tail via xchg_tail() and potentially link
* @node into the waitqueue via WRITE_ONCE(prev->next, node) below.
*/
smp_wmb();
/*
* Publish the updated tail.
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
*/
old = xchg_tail(lock, tail);
next = NULL;
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);
/* Link @node into the waitqueue. */
WRITE_ONCE(prev->next, node);
pv_wait_node(node, prev);
arch_mcs_spin_lock_contended(&node->locked);
/*
* While waiting for the MCS lock, the next pointer may have
* been set by another lock waiter. We optimistically load
* the next pointer & prefetch the cacheline for writing
* to reduce latency in the upcoming MCS unlock operation.
*/
next = READ_ONCE(node->next);
if (next)
prefetchw(next);
}
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
* The PV pv_wait_head_or_lock function, if active, will acquire
* the lock and return a non-zero value. So we have to skip the
* atomic_cond_read_acquire() call. As the next PV queue head hasn't
* been designated yet, there is no way for the locked value to become
* _Q_SLOW_VAL. So both the set_locked() and the
* atomic_cmpxchg_relaxed() calls will be safe.
*
* If PV isn't active, 0 will be returned instead.
*
*/
if ((val = pv_wait_head_or_lock(lock, node)))
goto locked;
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
locked:
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,*,0 -> *,*,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail)
* and nobody is pending, clear the tail code and grab the lock.
* Otherwise, we only need to grab the lock.
*/
/*
* In the PV case we might already have _Q_LOCKED_VAL set.
*
* The atomic_cond_read_acquire() call above has provided the
* necessary acquire semantics required for locking.
*/
if (((val & _Q_TAIL_MASK) == tail) &&
atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release; /* No contention */
/* Either somebody is queued behind us or _Q_PENDING_VAL is set */
set_locked(lock);
/*
* contended path; wait for next if not observed yet, release.
*/
if (!next)
next = smp_cond_load_relaxed(&node->next, (VAL));
arch_mcs_spin_unlock_contended(&next->locked);
pv_kick_node(lock, next);
release:
/*
* release the node
*/
__this_cpu_dec(mcs_nodes[0].count);
}
EXPORT_SYMBOL(queued_spin_lock_slowpath);数据结构
struct rq
sched.h - kernel/sched/sched.h - Linux source code (v4.19.113) - Bootlin
/*
* This is the main, per-CPU runqueue data structure.
*
* Locking rule: those places that want to lock multiple runqueues
* (such as the load balancing or the thread migration code), lock
* acquire operations must be ordered by ascending &runqueue.
*/
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running;
#ifdef CONFIG_NUMA_BALANCING
unsigned int nr_numa_running;
unsigned int nr_preferred_running;
unsigned int numa_migrate_on;
#endif
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
#ifdef CONFIG_NO_HZ_COMMON
#ifdef CONFIG_SMP
unsigned long last_load_update_tick;
unsigned long last_blocked_load_update_tick;
unsigned int has_blocked_load;
#endif /* CONFIG_SMP */
unsigned int nohz_tick_stopped;
atomic_t nohz_flags;
#endif /* CONFIG_NO_HZ_COMMON */
/* capture load from *all* tasks on this CPU: */
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this CPU: */
struct list_head leaf_cfs_rq_list;
struct list_head *tmp_alone_branch;
#endif /* CONFIG_FAIR_GROUP_SCHED */
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
struct task_struct *curr;
struct task_struct *idle;
struct task_struct *stop;
unsigned long next_balance;
struct mm_struct *prev_mm;
unsigned int clock_update_flags;
u64 clock;
u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_capacity;
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
unsigned char idle_balance;
/* For active balancing */
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* CPU of this runqueue: */
int cpu;
int online;
struct list_head cfs_tasks;
struct sched_avg avg_rt;
struct sched_avg avg_dl;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
struct sched_avg avg_irq;
#endif
u64 idle_stamp;
u64 avg_idle;
/* This is used to determine avg_idle's max value */
u64 max_idle_balance_cost;
#endif
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
u64 prev_irq_time;
#endif
#ifdef CONFIG_PARAVIRT
u64 prev_steal_time;
#endif
#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
u64 prev_steal_time_rq;
#endif
/* calc_load related fields */
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK
#ifdef CONFIG_SMP
int hrtick_csd_pending;
call_single_data_t hrtick_csd;
#endif
struct hrtimer hrtick_timer;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
unsigned long long rq_cpu_time;
/* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */
unsigned int yld_count;
/* schedule() stats */
unsigned int sched_count;
unsigned int sched_goidle;
/* try_to_wake_up() stats */
unsigned int ttwu_count;
unsigned int ttwu_local;
#endif
#ifdef CONFIG_SMP
struct llist_head wake_list;
#endif
#ifdef CONFIG_CPU_IDLE
/* Must be inspected within a rcu lock section */
struct cpuidle_state *idle_state;
#endif
};
static inline int cpu_of(struct rq *rq)
{
#ifdef CONFIG_SMP
return rq->cpu;
#else
return 0;
#endif
}raw_spinlock_t
spinlock_types.h - include/linux/spinlock_types.h - Linux source code (v4.19.113) - Bootlin
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;arch_spinlock_t
搜索发现有大力定义
通过bear make 生成出来的compile_commands.json来分析ARM64,即aarch64下的实现
{
"arguments": [
"gcc",
"-c",
"-Wp,-MD,kernel/locking/.spinlock.o.d",
"-nostdinc",
"-isystem",
"/usr/lib/gcc/aarch64-linux-gnu/7.3.0/include",
"-I./arch/arm64/include",
"-I./arch/arm64/include/generated",
"-I./include",
"-I./arch/arm64/include/uapi",
"-I./arch/arm64/include/generated/uapi",
"-I./include/uapi",
"-I./include/generated/uapi",
"-include",
"./include/linux/kconfig.h",
"-include",
"./include/linux/compiler_types.h",
"-D__KERNEL__",
"-mlittle-endian",
"-Wall",
"-Wundef",
"-Wstrict-prototypes",
"-Wno-trigraphs",
"-fno-strict-aliasing",
"-fno-common",
"-fshort-wchar",
"-Werror-implicit-function-declaration",
"-Wno-format-security",
"-std=gnu89",
"-fno-PIE",
"-mgeneral-regs-only",
"-DCONFIG_AS_LSE=1",
"-fno-asynchronous-unwind-tables",
"-Wno-psabi",
"-mabi=lp64",
"-fno-delete-null-pointer-checks",
"-Wno-frame-address",
"-Wno-format-truncation",
"-Wno-format-overflow",
"-Wno-int-in-bool-context",
"-O2",
"--param=allow-store-data-races=0",
"-Wframe-larger-than=2048",
"-fstack-protector-strong",
"-Wno-unused-but-set-variable",
"-Wno-unused-const-variable",
"-fno-omit-frame-pointer",
"-fno-optimize-sibling-calls",
"-fno-var-tracking-assignments",
"-g",
"-gdwarf-4",
"-pg",
"-fno-inline-functions-called-once",
"-Wdeclaration-after-statement",
"-Wno-pointer-sign",
"-fno-strict-overflow",
"-fno-merge-all-constants",
"-fmerge-constants",
"-fno-stack-check",
"-fconserve-stack",
"-Werror=implicit-int",
"-Werror=strict-prototypes",
"-Werror=date-time",
"-Werror=incompatible-pointer-types",
"-Werror=designated-init",
"-DKBUILD_BASENAME=\"spinlock\"",
"-DKBUILD_MODNAME=\"spinlock\"",
"-o",
"kernel/locking/.tmp_spinlock.o",
"kernel/locking/spinlock.c"
],
"directory": "/home/yeqiang/linux-4.19.113",
"file": "kernel/locking/spinlock.c"
},转换为gcc -E,宏展开
gcc -E -Wp,-MD,kernel/locking/.spinlock.o.d -nostdinc -isystem /usr/lib/gcc/aarch64-linux-gnu/7.3.0/include -I./arch/arm64/include -I./arch/arm64/include/generated -I./include -I./arch/arm64/include/uapi -I./arch/arm64/include/generated/uapi -I./include/uapi -I./include/generated/uapi -include ./include/linux/kconfig.h -include ./include/linux/compiler_types.h -D__KERNEL__ -mlittle-endian -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs -fno-strict-aliasing -fno-common -fshort-wchar -Werror-implicit-function-declaration -Wno-format-security -std=gnu89 -fno-PIE -mgeneral-regs-only -DCONFIG_AS_LSE=1 -fno-asynchronous-unwind-tables -Wno-psabi -mabi=lp64 -fno-delete-null-pointer-checks -Wno-frame-address -Wno-format-truncation -Wno-format-overflow -Wno-int-in-bool-context -O2 --param=allow-store-data-races=0 -Wframe-larger-than=2048 -fstack-protector-strong -Wno-unused-but-set-variable -Wno-unused-const-variable -fno-omit-frame-pointer -fno-optimize-sibling-calls -fno-var-tracking-assignments -g -gdwarf-4 -pg -fno-inline-functions-called-once -Wdeclaration-after-statement -Wno-pointer-sign -fno-strict-overflow -fno-merge-all-constants -fmerge-constants -fno-stack-check -fconserve-stack -Werror=implicit-int -Werror=strict-prototypes -Werror=date-time -Werror=incompatible-pointer-types -Werror=designated-init -DKBUILD_BASENAME=\"spinlock\" -DKBUILD_MODNAME=\"spinlock\" -o kernel/locking/.tmp_spinlock.E.c "kernel/locking/spinlock.c"搜索arch_spinllock_t
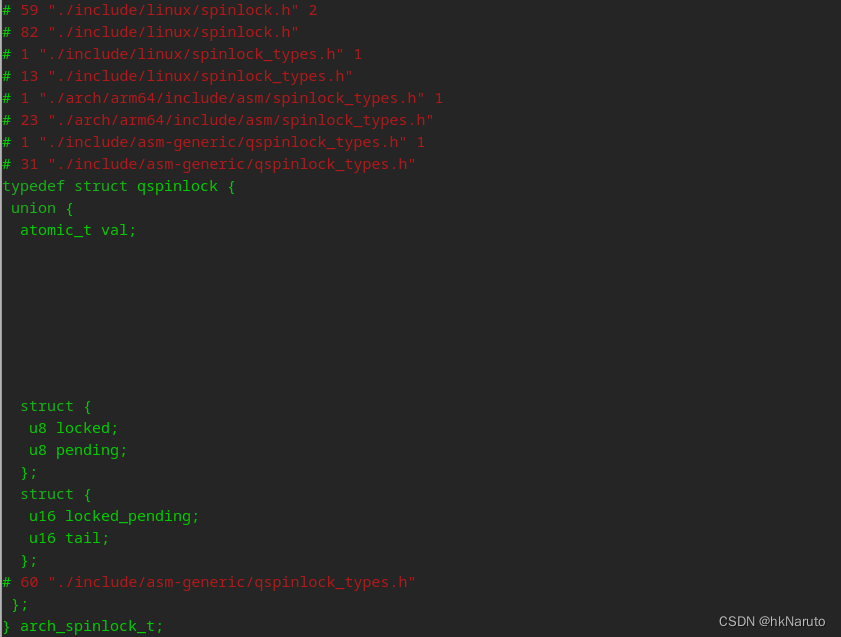
在线源码:
qspinlock_types.h - include/asm-generic/qspinlock_types.h - Linux source code (v4.19.113) - Bootlin
包含路径
#include <linux/spinlock.h> kernel/locking/spinlock.c:20
#include <linux/spinlock_types.h> include/linux/spinlock.h:82
#if defined(CONFIG_SMP) include/linux/spinlock_types.h:12
# include <asm/spinlock_types.h>
#else
#include <asm-generic/qspinlock_types.h> arch/arm64/include/asm/spinlock_types.h:23
typedef struct qspinlock { include/asm-generic/qspinlcok_types.h:31
union {
atomic_t val;
/*
* By using the whole 2nd least significant byte for the
* pending bit, we can allow better optimization of the lock
* acquisition for the pending bit holder.
*/
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
struct {
u16 tail;
u16 locked_pending;
};
struct {
u8 reserved[2];
u8 pending;
u8 locked;
};
#endif
};
} arch_spinlock_t;宏开关
CONFIG_DEBUG_SPINLOCK
CONFIG_DEBUG_LOCK_ALLOC
CONFIG_INLINE_SPIN_LOCK_IRQSAVE=y
其中CONFIG_SMP=y
CONFIG_PREEMPT_COUNT
openEuler 未定义
红旗linux未定义
宏定义?
raw_spin_lock
spinlock.h - include/linux/spinlock.h - Linux source code (v4.19.113) - Bootlin
#define raw_spin_lock(lock) _raw_spin_lock(lock)_raw_spin_lock
spinlock_api_smp.h - include/linux/spinlock_api_smp.h - Linux source code (v4.19.113) - Bootlin
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock) __acquires(lock);__lockfunc
spinlock.h - include/linux/spinlock.h - Linux source code (v4.19.113) - Bootlin
#define __lockfunc __attribute__((section(".spinlock.text")))compiler_types.h - include/linux/compiler_types.h - Linux source code (v4.19.113) - Bootlin
# define __acquires(x) __attribute__((context(x,0,1)))
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)