Ubuntu 16.04下Caffe-SSD的应用(三)——训练VOC2007数据生成模型
前言1.经过前面运行的脚本,在Caffe-ssd/data/VOCdevkit/VOC2007/lmdb目录内应该生成了:VOC2007_test_lmdb 和 VOC2007_trainval_lmdb两个文件夹。2.那之后就开始到训练过程了,训练所用的文件脚本ssd_pascal.py说明。3.我配置的环境是Ubuntu 16.04 LST 64位,Qt5.9,Python2.7,Caf...
前言
1.经过运行前面的脚本,在Caffe-ssd/data/VOCdevkit/VOC2007/lmdb目录内应该生成了:VOC2007_test_lmdb 和 VOC2007_trainval_lmdb两个文件夹。
2.那之后就开始到训练过程,训练所调用的是python examples/ssd/ssd_pascal.py的脚本。
3.我配置的环境是Ubuntu 16.04 LST 64位,Qt5.9,Python2.7,Caffe-SSD,因为只跑CPU版本,所以没有配置CUDA库。
一、训练准备
1.下载预训练模型VGG_ILSVRC_16_layers_fc_reduced.caffemode,在caffe上-ssd/models下新建一个VGGNet的目录,并把下载好的文件放进去。

2.更改数据文件的权限,如不更改可能在训练过程中报错。
cd caffe/data/VOCdevkit/
sudo chmod -R 777 VOC2007
二、修改ssd_pascal.py脚本
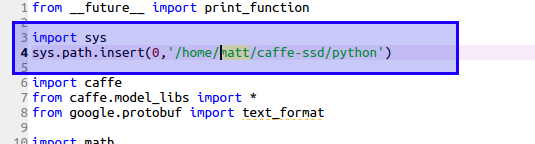
1.打开/home/matt/caffe-ssd/examples/ssd目录下ssd_pascal.py的脚本,在第import caffe前面加上python的环境路径,如果不加,运行中可能会报找不到caffe的错误,(路径换成自己的路径,下面有关路径的都要注意这点)。
import sys
sys.path.insert(0,'/home/matt/caffe-ssd/python')
2.把训练和测试的数据路径改成前面生成的lmdb路径。
train_data = "/home/matt/caffe-ssd/data/VOCdevkit/VOC2007/lmdb/VOC2007_trainval_lmdb"
test_data = "/home/matt/caffe-ssd/data/VOCdevkit/VOC2007/lmdb/VOC2007_test_lmdb"

3.更改测试的txt路径,预训练模型路径,标签路径。
name_size_file = "/home/matt/caffe-ssd/data/VOCdevkit/VOC2007/test_name_size.txt"
pretrain_model = "/home/matt/caffe-ssd/models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel"
label_map_file = "/home/matt/caffe-ssd/data/VOCdevkit/VOC2007/labelmap_voc.prototxt"

4.因为是CPU版本,去掉去GPU相关的设置。

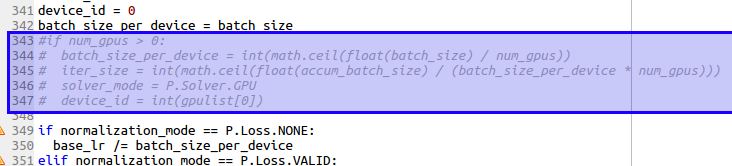
5.更改迭代次数,如果不更改,原本的参数是10000多代,光CPU要跑好多天,这里只是把训练流程介绍清楚而已,我改成200代。

三、开始训练
把ssd_pascal.py更改好,保存退出。把目录切到caffe-ssd/,运行ssd_pascal.py。
cd caffe-ssd/
python ./examples/ssd/ssd_pascal.py
如果不报错,会一直在训练,直到训练完成,会在相关的路径生成训练好的模型。

四、测试模型

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)