
SDK封装:算法sdk封装的思路及细节总结
因为开发过程中,往往没有真实的部署环境,或者真实部署环境资源紧张,大家迫不得已要在自己的设备上开发。下面记录下,这种情况下算法开发和SDK方式封装的总体思路。
记录下,自己在算法开发和SDK方式封装的总体思路、注意细节。
一、总体思路
因为开发过程中,往往没有真实的部署环境,或者真实部署环境资源紧张,大家迫不得已要在自己的设备上开发。因此,该情况下,我总结的开发和封装思路。
1、自己平台上算法开发
输入:训练、测试数据等。
输出:包含算法源码、原始网络权重的工程。
步骤:在各自的平台/设备上完成算法逻辑开发、及网络模型迭代训练。
2、真实环境下算法库编译与SDK打包
输入:包含算法逻辑源码、和原始网络权重的工程。
输出:包含算法动态库libxxx.so、转换后网络权重的SDK。
步骤:
1)将上步骤的完整工程拷贝至具有真实部署环境的服务器上(下面直接称之为服务器)。
2)在该服务器上,完成算法动态库的编译;
其中,重点是把自己算法所依赖的最终平台环境的第三方依赖库,都拷贝至工程目录下、同时对应编辑好makefile文件。
3)在该服务器上,完成网络权重的转换。
如果工程里用到了tensorrt加速的权重,则需要在该服务器上对网络权重进行转换,否则不需要本步骤。(因为tensorrt模型权重对显卡设备、tensorrt版本都敏感)
具体地,把模型转换程序(通常为源码)拷贝至该服务器,重新编译模型转换程序;然后转换权重拷贝进自己工程。
4)删除工程里所有的源码等内容,剩余部分即为SDK。
源码删除前vs源码删除后:(目录结构可以自行调整,但是需要清晰简单,方便下游人员调用)
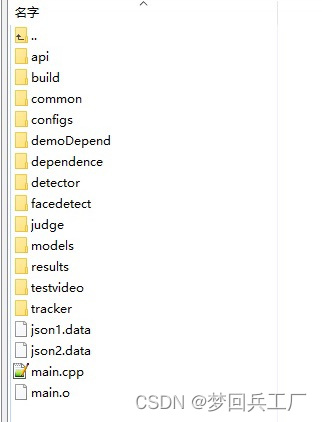
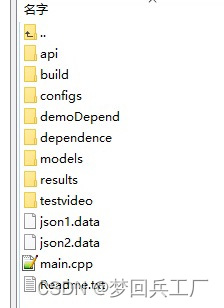
5)编写readme ,方便下游人员调用。
sdk中Readme.txt:(形式、内容不定,也可以写上其他注意事项)
1、、SDK目录
-api
--include 算法头文件目录
--src 算法源文件目录
-build 算法动态库、demo编译Makefile目录
-configs 内置算法(yolo、fastreid等)配置文件目录
-dependence 算法动态库依赖的第三方库(cuda、cudnn、tensorrt、opencv等)目录
-models 模型权重文件目录
-demoDepend
--include demo编译需要的头文件目录
--libs demo编译需要的依赖库文件目录
-testvideo demo的输入视频/文件路径
-results 检测结果目录(考虑到帧率问题,暂时不输出结果的视频文件,因此该文件为空)
2、、算法动态库调用
请参考./build/Makefile和./main.cpp文件。
6)在服务器上编写demo,调用自己的动态库,测试算法动态库是否好用。
二、注意细节
1、代码隔离
因为自己封装的SDK,最终是一个模块集成进整个系统里。因此,假如一些函数、全局变量和整个系统中有重名的,则可能造成错误(编译阶段命名冲突错误、甚至运行阶段悄无声息地进错函数错误),为了避免这些问题,需要进行代码隔离。
解决方法:自己的源码、头文件中添加namespace 。具体怎样加,帖子很多。。。
2、接口头文件尽量少包含额外头文件
为了方便下游人员集成自己SDK、调用接口,在自己最外围的接口头文件里,应该尽量少得再去引用其他头文件,否则需要在SDK里附带这些额外的头文件,并且调用方编译时也需要引用这些头文件,比较麻烦、且调用方也容易混乱、不知道到底哪个是接口头文件。
解决方法:部分需要的头文件可以放在源文件里、一些头文件里自定义的数据类型可以先用非自定义类型变量代替
3、目录结构简单易懂
尽量固定下来sdk目录结构,且要让调用方一眼就知道该目录下放的是什么。
解决方法:目录上面有截图,当然要根据自己情况调整。
4、开箱即用
调用方肯定希望sdk拿过来,放到自己工程里编译下就能用,因此,把sdk依赖的库尽可能地放进sdk工程目录里,这样大大减少后期调用方再去配环境、安插件的麻烦。
解决方法:依赖的第三方库,例如opencv等随附进sdk里。注意第三方依赖库在编译自己动态库时的路径和最终SDK中的路径要一致,否则可能链接不到。
4、固定封装模式、简化封装流程,尽量避免在软件封装上浪费时间,应该把更多时间放在算法和软件优化上。
解决方法:例如简化封装流程(开发阶段头文件、库都放在本地,这样大大减少后续更换设备时重新配置makefile的时间)、利用远程工具直接远程编辑和编译工程(vscode的remote-ssh等)
先以上。。。。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)