云小课|MRS数据分析-通过Spark Streaming作业消费Kafka数据
Spark Streaming是一种构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力。本文介绍如何使用MRS集群运行Spark Streaming作业消费Kafka数据。
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。

摘要:Spark Streaming是一种构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力。本文介绍如何使用MRS集群运行Spark Streaming作业消费Kafka数据。
本文分享自华为云社区《【云小课】EI第48课 MRS数据分析-通过Spark Streaming作业消费Kafka数据》,作者: 阅识风云 。
Spark是分布式批处理框架,提供分析挖掘与迭代式内存计算能力,支持多种语言(Scala/Java/Python)的应用开发。
Spark Streaming是一种构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力。本文介绍如何使用MRS集群运行Spark Streaming作业消费Kafka数据。

在本案例中,假定某个业务Kafka每1秒就会收到1个单词记录。基于业务需要,开发的Spark应用程序实现实时累加计算每个单词的记录总数的功能。
本案例基本操作流程如下所示:
- 创建MRS集群。
- 准备应用程序。
- 上传Jar包及源数据。
- 运行作业并查看结果。
场景描述
Spark提供分析挖掘与迭代式内存计算能力, 适用以下场景:
- 数据处理(Data Processing):可以用来快速处理数据,兼具容错性和可扩展性。
- 迭代计算(Iterative Computation):支持迭代计算,有效应对多步的数据处理逻辑。
- 数据挖掘(Data Mining):在海量数据基础上进行复杂的挖掘分析,可支持各种数据挖掘和机器学习算法。
- 流式处理(Streaming Processing):支持秒级延迟的流式处理,可支持多种外部数据源。
- 查询分析(Query Analysis):支持标准SQL查询分析,同时提供DSL(DataFrame), 并支持多种外部输入。
当前Spark支持两种数据处理方式:Direct Streaming和Receiver方式。
Direct Streaming方式主要通过采用Direct API对数据进行处理。以Kafka Direct接口为例,与启动一个Receiver来连续不断地从Kafka中接收数据并写入到WAL中相比,Direct API简单地给出每个batch区间需要读取的偏移量位置。然后,每个batch的Job被运行,而对应偏移量的数据在Kafka中已准备好。这些偏移量信息也被可靠地存储在checkpoint文件中,应用失败重启时可以直接读取偏移量信息。
Direct Kafka接口数据传输

需要注意的是,Spark Streaming可以在失败后重新从Kafka中读取并处理数据段。然而,由于语义仅被处理一次,重新处理的结果和没有失败处理的结果是一致的。
因此,Direct API消除了需要使用WAL和Receivers的情况,且确保每个Kafka记录仅被接收一次,这种接收更加高效。使得Spark Streaming和Kafka可以很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性、高效性及易用性,因此推荐使用Direct Streaming方式处理数据。
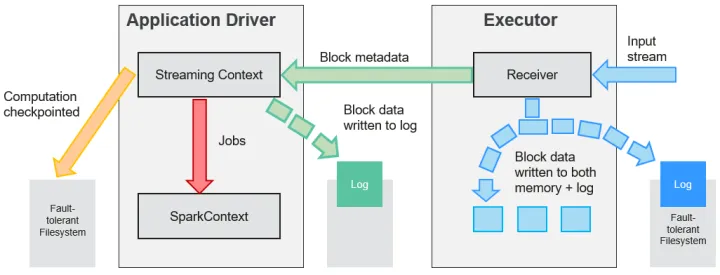
在一个Spark Streaming应用开始时(也就是Driver开始时),相关的StreamingContext(所有流功能的基础)使用SparkContext启动Receiver成为长驻运行任务。这些Receiver接收并保存流数据到Spark内存中以供处理。用户传送数据的生命周期如图1-2所示:
数据传输生命周期

- 接收数据(蓝色箭头)
Receiver将数据流分成一系列小块,存储到Executor内存中。另外,在启用预写日志(Write-ahead Log,简称WAL)以后,数据同时还写入到容错文件系统的预写日志中。 - 通知Driver(绿色箭头)
接收块中的元数据(Metadata)被发送到Driver的StreamingContext。这个元数据包括:
定位其在Executor内存中数据位置的块Reference ID。
若启用了WAL,还包括块数据在日志中的偏移信息。 - 处理数据(红色箭头)
对每个批次的数据,StreamingContext使用Block信息产生RDD及其Job。StreamingContext通过运行任务处理Executor内存中的Block来执行Job。 - 周期性地设置检查点(橙色箭头)
- 为了容错的需要,StreamingContext会周期性地设置检查点,并保存到外部文件系统中。
华为云MapReduce服务提供了Spark服务多种场景下的样例工程,本案例对应示例场景的开发思路:
- 接收Kafka中数据,生成相应DStream。
- 对单词记录进行分类统计。
- 计算结果,并进行打印。
步骤1:创建MRS集群
1、创建并购买一个包含有Spark2x、Kafka组件的MRS集群,详情请参见MRS用户指南的“购买自定义集群”。
说明:本文以购买的MRS 3.1.0版本的集群为例,集群未开启Kerberos认证。
2、集群购买成功后,在MRS集群的任一节点内,安装集群客户端,具体操作可参考MRS快速入门的“安装并使用集群客户端”。
例如客户端安装目录为“/opt/client”。
步骤2:准备应用程序
1、通过开源镜像站获取样例工程。
下载样例工程的Maven工程源码和配置文件,并在本地配置好相关开发工具,可参考MRS开发指南(普通版_3.x)的“通过开源镜像站获取样例工程”。
根据集群版本选择对应的分支,下载并获取MRS相关样例工程。
例如本章节场景对应示例为“SparkStreamingKafka010JavaExample”样例。
2、本地使用IDEA工具导入样例工程,等待Maven工程下载相关依赖包,具体操作可参考考MRS开发指南(普通版_3.x)的Spark开发指南(普通模式)的“配置并导入样例工程”。

在本示例工程中,通过使用Streaming调用Kafka接口来获取单词记录,然后把单词记录分类统计,得到每个单词记录数,关键代码片段如下:
public class StreamingExampleProducer {
public static void main(String[] args) throws IOException {
if (args.length < 2) {
printUsage();
}
String brokerList = args[0];
String topic = args[1];
String filePath = "/home/data/"; //源数据获取路径
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int m = 0; m < Integer.MAX_VALUE / 2; m++) {
File dir = new File(filePath);
File[] files = dir.listFiles();
if (files != null) {
for (File file : files) {
if (file.isDirectory()) {
System.out.println(file.getName() + "This is a directory!");
} else {
BufferedReader reader = null;
reader = new BufferedReader(new FileReader(filePath + file.getName()));
String tempString = null;
while ((tempString = reader.readLine()) != null) {
// Blank line judgment
if (!tempString.isEmpty()) {
producer.send(new ProducerRecord<String, String>(topic, tempString));
}
}
// make sure the streams are closed finally.
reader.close();
}
}
}
try {
Thread.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static void printUsage() {
System.out.println("Usage: {brokerList} {topic}");
}
}3、本地配置好Maven及SDK相关参数后,样例工程会自动加载相关依赖包。加载完毕后,执行package打包,获取打包后的Jar文件。

例如打包后的Jar文件为“SparkStreamingKafka010JavaExample-1.0.jar”。
步骤3:上传Jar包及源数据
1、准备向Kafka发送的源数据,例如如下的“input_data.txt”文件,将该文件上传到客户端节点的“/home/data”目录下。
ZhangSan
LiSi
WangwWU
Tom
Jemmmy
LinDa2、将编译后的Jar包上传到客户端节点,例如上传到“/opt”目录。
说明:如果本地网络无法直接连接客户端节点上传文件,可先将jar文件或者源数据上传至OBS文件系统中,然后通过MRS管理控制台集群内的“文件管理”页面导入HDFS中,再通过HDFS客户端使用hdfs dfs -get命令下载到客户端节点本地。
步骤4:运行作业并查看结果
1、使用root用户登录安装了集群客户端的节点。
cd /opt/client
source bigdata_env2、创建用于接收数据的Kafka Topic。
kafka-topics.sh --create --zookeeper quorumpeer实例IP地址:ZooKeeper客户端连接端口/kafka --replication-factor 2 --partitions 3 --topic topic名称quorumpeer实例IP地址可登录集群的FusionInsight Manager界面,在“集群 > 服务 > ZooKeeper > 实例”界面中查询,多个地址可用“,”分隔。ZooKeeper客户端连接端口可通过ZooKeeper服务配置参数“clientPort”查询,默认为2181。
例如执行以下命令:
kafka-topics.sh --create --zookeeper 192.168.0.17:2181/kafka --replication-factor 2 --partitions 2 --topic sparkkafka返回结果如下:
Created topic sparkkafka.3、Topic创建成功后,运行程序向Kafka发送数据。
java -cp /opt/SparkStreamingKafka010JavaExample-1.0.jar:/opt/client/Spark2x/spark/jars/*:/opt/client/Spark2x/spark/jars/streamingClient010/* com.huawei.bigdata.spark.examples.StreamingExampleProducer Broker实例IP地址:Kafka连接端口 topic名称Kafka Broker实例IP地址可登录集群的FusionInsight Manager界面,在“集群 > 服务 > Kafka > 实例”界面中查询,多个地址可用“,”分隔。Broker端口号可通过Kafka服务配置参数“port”查询,默认为9092。
例如执行以下命令:
java -cp /opt/SparkStreamingKafka010JavaExample-1.0.jar:/opt/client/Spark2x/spark/jars/*:/opt/client/Spark2x/spark/jars/streamingClient010/* com.huawei.bigdata.spark.examples.StreamingExampleProducer 192.168.0.131:9092 sparkkafka返回结果如下:
...
transactional.id = null
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
2022-06-08 15:43:42 INFO AppInfoParser:117 - Kafka version: xxx
2022-06-08 15:43:42 INFO AppInfoParser:118 - Kafka commitId: xxx
2022-06-08 15:43:42 INFO AppInfoParser:119 - Kafka startTimeMs: xxx
2022-06-08 15:43:42 INFO Metadata:259 - [Producer clientId=DemoProducer] Cluster ID: d54RYHthSUishVb6nTHP0A4、重新打开一个客户端连接窗口,执行以下命令,读取Kafka Topic中的数据。
cd /opt/client/Spark2x/spark
source bigdata_env
bin/spark-submit --master yarn --deploy-mode client --jars $(files=($SPARK_HOME/jars/streamingClient010/*.jar); IFS=,; echo "${files[*]}") --class com.huawei.bigdata.spark.examples.KafkaWordCount /opt/SparkStreamingKafka010JavaExample-1.0.jar <checkpointDir> <brokers> <topic> <batchTime><checkPointDir>指应用程序结果备份到HDFS的路径,自行指定即可,例如“/tmp”。
<brokers>指获取元数据的Kafka地址,格式为“Broker实例IP地址:Kafka连接端口”。
<topic>指读取Kafka上的topic名称。
<batchTime>指Streaming分批的处理间隔,例如设置为“5”。
例如执行以下命令:
cd /opt/client/Spark2x/spark
source bigdata_env
bin/spark-submit --master yarn --deploy-mode client --jars $(files=($SPARK_HOME/jars/streamingClient010/*.jar); IFS=,; echo "${files[*]}") --class com.huawei.bigdata.spark.examples.KafkaWordCount /opt/SparkStreamingKafka010JavaExample-1.0.jar /tmp 192.168.0.131:9092 sparkkafka 5程序运行后,可查看到Kafka中数据的统计结果:
....
-------------------------------------------
Time: 1654674380000 ms
-------------------------------------------
(ZhangSan,6)
(Tom,6)
(LinDa,6)
(WangwWU,6)
(LiSi,6)
(Jemmmy,6)
-------------------------------------------
Time: 1654674385000 ms
-------------------------------------------
(ZhangSan,717)
(Tom,717)
(LinDa,717)
(WangwWU,717)
(LiSi,717)
(Jemmmy,717)
-------------------------------------------
Time: 1654674390000 ms
-------------------------------------------
(ZhangSan,2326)
(Tom,2326)
(LinDa,2326)
(WangwWU,2326)
(LiSi,2326)
(Jemmmy,2326)
...5、登录FusionInsight Manager界面,单击“集群 > 服务 > Spark2x”。
6、在服务概览页面点击Spark WebUI后的链接地址,可进入History Server页面。
单击待查看的App ID,您可以查看Spark Streaming作业的状态。

----结束
好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献5820条内容
已为社区贡献5820条内容

所有评论(0)