【数据结构】八种常见数据结构介绍
数据结构是计算机存储、组织数据的方式。一种好的数据结构可以带来更高的运行或者存储效率。数据在内存中是呈线性排列的,但是我们可以使用指针等道具,构造出类似“树形”的复杂结构。下面介绍八个常见的数据结构。
相似文章推荐:
零. 总览
数据结构是计算机存储、组织数据的方式。一种好的数据结构可以带来更高的运行或者存储效率。数据在内存中是呈线性排列的,但是我们可以使用指针等道具,构造出类似“树形”的复杂结构。下面介绍八个常见的数据结构。
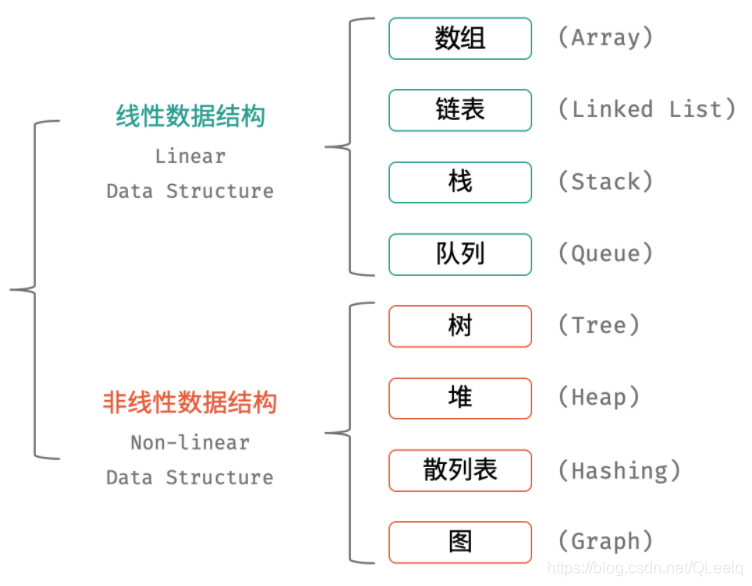
一. 数组
数组是一种线性结构,而且在物理内存中也占据着一块连续空间。
- 优点:访问数据简单。
- 缺点:添加和删除数据比较耗时间。
- 使用场景:频繁查询,对存储空间要求不大,很少增加和删除的情况。
数据访问:由于数据是存储在连续空间内,所以每个数据的内存地址都是通过数据小标算出,所以可以直接访问目标数据。(这叫做“随机访问”)。比如下方,可以直接使用a[2]访问Red。

数据添加:数据添加需要移动其他数据。首先增加足够的空间,然后把已有的数据一个个移开。
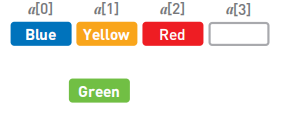

数据删除:反过来,如果想要输出数据Green,也是一样挨个把数据往反方向移动。
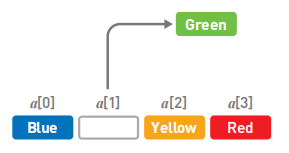
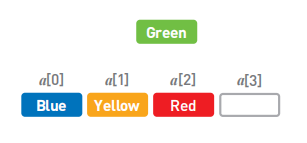
二. 链表
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。
- 优点:数据添加和删除方便
- 缺点:访问比较耗费时间
- 适用场景:数据量较小,需要频繁增加,删除操作的场景
数组和链表数据结构对比列表如下:
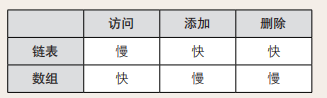
数据访问:因为数据都是分散存储的,所以想要访问数据,只能从第一个数据开始,顺着指针的指向逐一往下访问。

数据添加:将Blue的指针指向的位置变成Green,然后再把Green的指针指向Yellow。
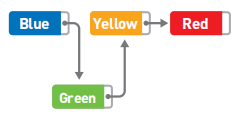
数据删除:只要改变指针的指向就可以了,比如删除Yellow,只需把Green指针指向的位置从Yellow编程Red即可。
虽然Yellow本身还存储在内存中,但是不管从哪里都无法访问这个数据,所以也就没有特意去删除它的必要了。今后需要用到Yellow所在的存储空间时,只要用新数据覆盖掉就可以了。
三. 栈
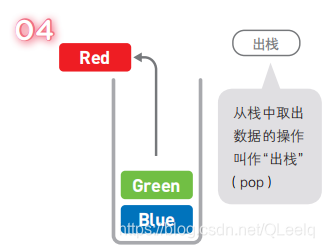
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数
据。从栈顶放入元素的操作叫入栈,取出元素叫出栈。
特点:后进先出(Last In First Out,简称LIFO)

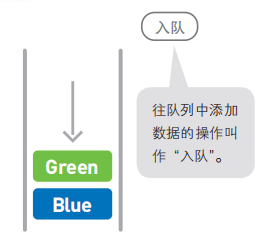
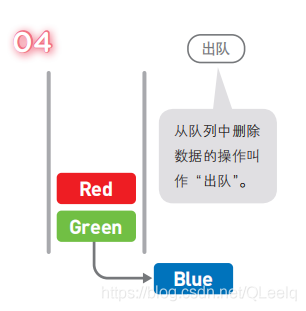
四. 队列
队列中的添加和删除数据的操作分别是在两端进行的。队列可以在一端添加元素,在另一端取出元素,也就是:先进先出(First In First Out,简称FIFO)
五. 哈希表
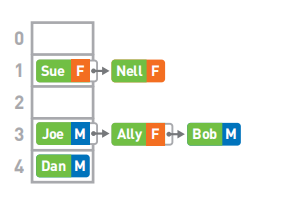
哈希表,也叫散列表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。例如,下列键(key)为人名,value为性别。
一般来说,我们可以把键当作数据的标识符,把值当作数据的内容。

- 数据存储
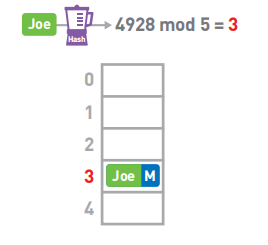
假设我们需要存储5个元素,首先使用哈希函数(Hash)计算Joe的键,也就是字符串"Joe"的哈希值,得到4928,然后将哈希值除以数组长度5(mod运算),求得其余数。因此,我们将Joe的数据存进数组的3号箱子中。
- 冲突
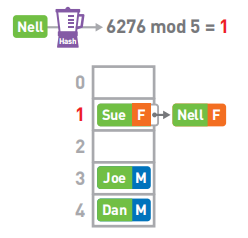
如果两个哈希值取余的结果相同,我们称这种情况为“冲突”。假设Nell键的哈希值为6276,mod 5的结果为1。但此时1号箱已经存储了Sue的数据,可使用链表在已有的数据的后面继续存储新的数据。
- 查询
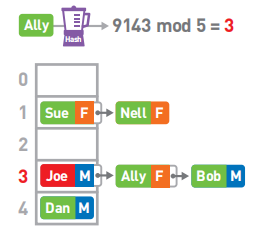
假设最终的哈希表为:
如果要查找Ally的性别,首先算出Alley键的哈希值,然后对它进行mod运算。最终结果为3。
然而3号箱中数据的键是Joe而不是Ally。此时便需要对Joe所在的链表进行线性查找。找到了键为Ally的数据。取出其对应的值,便知道了Ally的性别为女(F)。
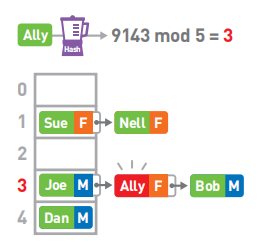
- 特点
可以利用哈希函数快速访问到数组的目标数据。如果发生哈希冲突,就使用链表进行存储。
如果数组的空间太小,使用哈希表的时候就容易发生冲突,线性查找的使用频率也会更高;反过来,如果数组的空间太大,就会出现很多空箱子,造成内存的浪费。因此,给数组设定合适的空间非常重要。
在存储数据的过程中,如果发生冲突,可以利用链表在已有数据的后面插入新数据来解决冲突。这种方法被称为“链地址法”。除了链地址法以外,还有几种解决冲突的方法。其中,应用较为广泛的是“开放地址法”。
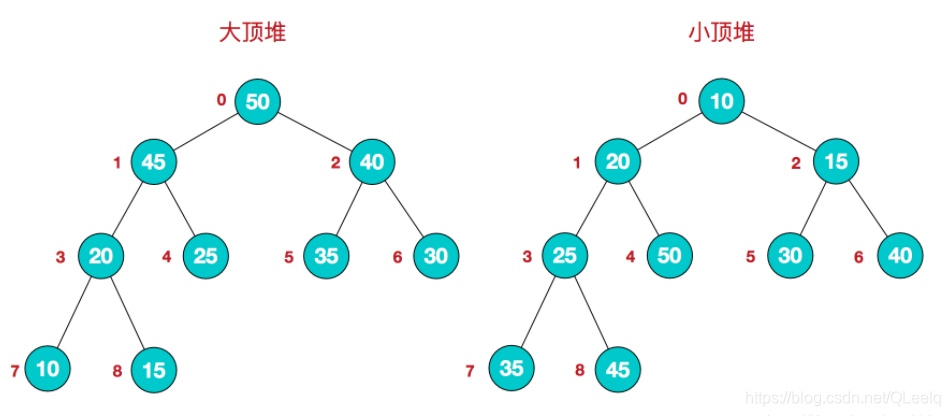
六. 堆
堆是一种图的树形结构,被用于实现“优先队列”(priority queues)。优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。堆有下列特点:
- 每个节点最多有两个子节点
- 排列顺序必须从上到下,同一行从左到右
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 存放数据时,一般会把新数据放在最下面一行靠左的位置。如果最下面一行没有多余空间时,就再往下另起一行,并把数据添加到这一行的最左端。
堆的性质:
- 堆是一个完全二叉树
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
- 一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
- 一棵深度为 k k k且有 2 k − 1 2^k - 1 2k−1个结点的二叉树称为满二叉树。也就是说除了叶子节点都有2个子节点,且所有的叶子节点都在同一层。
七. 树
它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
在日常的应用中,我们讨论和用的更多的是树的其中一种结构,就是二叉树。二叉树是树的特殊一种,具有如下特点:
- 每个结点最多有两颗子结点。
- 左子树和右子树是有顺序的,次序不能颠倒。
- 即使某结点只有一个子树,也要区分左右子树。
二叉树是一种比较有用的折中方案,它添加,删除元素都很快,并且在查找方面也有很多的算法优化,所以,二叉树既有链表的好处,也有数组的好处,是两者的优化方案,在处理大批量的动态数据方面非常有用。
二叉树有很多扩展的数据结构,包括平衡二叉树、红黑树、B+树等,这些数据结构在二叉树的基础上衍生了很多的功能,在实际应用中广泛用到,例如mysql的数据库索引结构用的就是B+树,还有HashMap的底层源码中用到了红黑树。这些二叉树的功能强大,但算法上比较复杂,想学习的话还是需要花时间去深入的。
八. 图
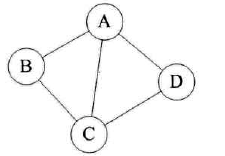
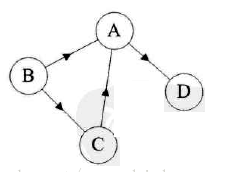
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。按照顶点指向的方向可分为无向图和有向图:
无向图:
有向图:
参考:《我的第一本算法书》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 72
72 1
1- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)