广度优先遍历(Breath First Search)
前言深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath First Search)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等,也频繁出现在 leetcode,高频面试题中。本文将会从以下几个方面来讲述深度优先遍历相信大家看了肯定会有收获。深度优先遍历深度优先遍历简介习题演练DFS在搜索引擎中的应用深度优先遍历
前言
深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath First Search)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等,也频繁出现在 leetcode,高频面试题中。
本文将会从以下几个方面来讲述深度优先遍历相信大家看了肯定会有收获。
广度优先遍历
- 广度优先遍历简介
- 习题演练
- BFS在搜索引擎中的应用
广度优先遍历简介
广度优先遍历
广度优先遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
上文所述树的广度优先遍历动图如下,每个节点的值即为它们的遍历顺序。所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。

深度优先遍历用的是栈,而广度优先遍历要用队列来实现,我们以下图二叉树为例来看看如何用队列来实现广度优先遍历。
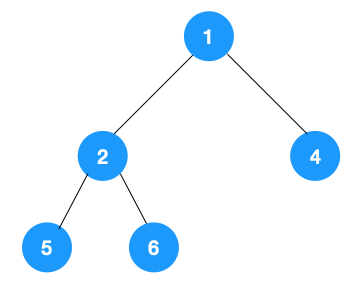
动图如下:

相信看了以上动图,不难写出如下代码:
/**
* 使用队列实现 bfs
* @param root
*/
private static void bfs(Node root) {
if (root == null) {
return;
}
Queue<Node> stack = new LinkedList<>();
stack.add(root);
while (!stack.isEmpty()) {
Node node = stack.poll();
System.out.println("value = " + node.value);
Node left = node.left;
if (left != null) {
stack.add(left);
}
Node right = node.right;
if (right != null) {
stack.add(right);
}
}
}
结束语
广度优先遍历是不是明显要比深度优先遍历简单得多,相信大家一定对广度优先遍历的理解更深了.若有不对的地方,欢迎指出.谢谢大家.

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)