java的Map集合 详解Map集合
java 集合 Map, HashMap,LinkedHashMap,Hashtable, 详解Map集合
一、Map集合的特点:
Map集合的特点:
1.Map是一个双列集合,一个元素包含两个值(一个key,一个value)
2.Map集合中的元素,key和value的数据类型可以相同,也可以不同
3.Map中的元素,key不允许重复,value可以重复
4.Map里的key和value是一一对应的。
二、Map中的方法:
1.public V put (K key,V value) 把指定的键和值添加到Map集合中,返回值是V
如果要存储的键值对,key不重复返回值V是null
如果要存储的键值对,key重复返回值V是被替换的value值

2. public V remove(Object key)把指定键所对应的键值对元素,在Map集合中删除,返回被删除的元素的值。 返回值:V 。如果key存在,返回被删除的值,如果key不存在,返回null

3.public V remove (Object key):根据指定的键 在Map集合中获取对应的值
如果key存在,返回对应的value值,如果key不存在,返回null

4.boolean containsKey( Object key)判判断集合中是否包含指定的键
包含返回true,不包含返回false
三、遍历Map集合的方式
1.通过键找值的方法;
使用了setKey方法,将Map集合中的key值,存储到Set集合,用迭代器或foreach循环遍历Set集合来获取Map集合的每一个key,并使用get(key)方法来获取value值


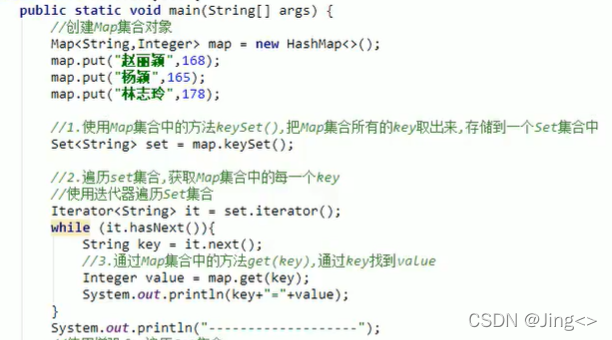

2.使用Entry对象遍历
Map.Entry<K,V>,在Map接口中有一个内部接口Entry(内部类)
作用:当集合一创建,就会在Map集合中创建一个Entry对象,用来记录键与值(键值对对象,键值的映射关系)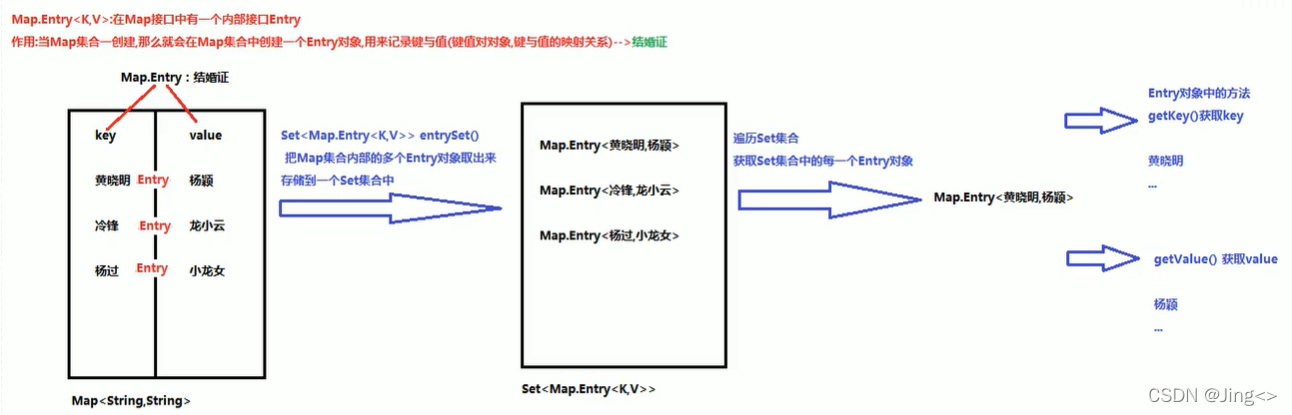
有了Entry对象就可以使用Map中的entrySet方法,把Map集合中的多个Entry对象存入一个Set集合来遍历Set集合,获取Set集合中每一个Entry对象,然后可以使用Entry中的两个方法getKey和getValue来分别获取键和值。
代码步骤:



四、Map的常用实现类
(一)、HashMap
【1】.特点:1.HashMap底是哈希表,查询速度非常快(jdk1.8之前是数组+单向链表,1.8之后是数组+单向链表/红黑树 ,链表长度超过8时,换成红黑树)
2. HashMap是无序的集合,存储元素和取出元素的顺序有可能不一致
3.集合是不同步的,也就是说是多线程的,速度快
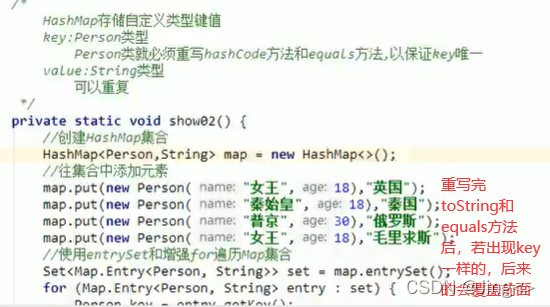
【2】.HashMap存储自定义类型键值
HashMap存储自定义类型键值,Map集合保证key是唯一的:作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一

(二)LinkedHashMap
HashMap有子类LinkedHashMap:LinkedHashMap <K,V> extends HashMap <K,V>
是Map接口的哈希表和链表的实现,具有可预知的迭代顺序(有序)
底层原理:哈希表+链表(记录元素顺序)
特点:1.LinkedHashMap底层是哈希表+链表(保证迭代的顺序)
2.LinkedHashMap是一个有序的集合,存储元素和取出元素的顺序一致
改进之处就是:元素存储有序了
(三)Hashtable
Hashtable<K,V> implements Map<K,V>
Hashtable:底层也是哈希表,是同步的,是一个单线程结合,是线程安全的集合,速度慢
HashMap:底层也是哈希表,但是线程不安全的集合,是多线程集合,速度快
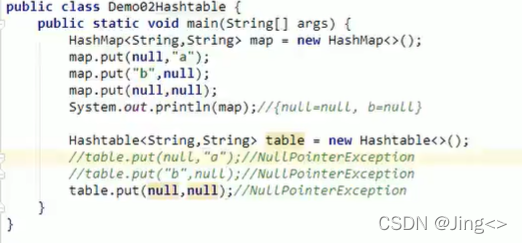
HashMap(还有之前学的所有集合):都可以存储null键,null值
Hashtable:不能存储null键,null值

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 108
108 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)