对比学习(contrastive learning)
什么是自监督学习?举个通俗的例子:即使不记得物体究竟是什么样子,我们也可以在野外识别物体。我们通过记住高阶特征并忽略微观层面的细节来做到这一点。那么,现在的问题是,我们能否构建不关注像素级细节,只编码足以区分不同对象的高阶特征的表示学习算法?通过对比学习,研究人员正试图解决这个问题。什么是对比学习?对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集
什么是自监督学习?
举个通俗的例子:即使不记得物体究竟是什么样子,我们也可以在野外识别物体。
我们通过记住高阶特征并忽略微观层面的细节来做到这一点。那么,现在的问题是,我们能否构建不关注像素级细节,只编码足以区分不同对象的高阶特征的表示学习算法?通过对比学习,研究人员正试图解决这个问题。
什么是对比学习?
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
让我们从一个简单的例子开始。想象一下,你是一个试图理解世界的新生婴儿。在家里,假设你有两只猫和一只狗。
即使没有人告诉你它们是“猫”和“狗”,你仍可能会意识到,与狗相比,这两只猫看起来很相似。

仅仅通过识别它们之间的异同,我们的大脑就可以了解我们的世界中物体的高阶特征。
例如,我们可能意识地认识到,两只猫有尖尖的耳朵,而狗有下垂的耳朵。或者我们可以对比狗突出的鼻子和猫的扁平脸。
本质上,对比学习允许我们的机器学习模型做同样的事情。它会观察哪些数据点对“相似”和“不同”,以便在执行分类或分割等任务之前了解数据更高阶的特征。
为什么这个功能如此强大?
这是因为我们可以在没有任何注释或标签的情况下,训练模型以学习很多关于我们的数据的知识,因此术语,自监督学习。
在大多数实际场景中,我们没有为每张图像设置标签。以医学成像为例,为了创建标签,专业人士必须花费无数个小时查看图像以手动分类、分割等。
通过对比学习,即使只有一小部分数据集被标记,也可以显著提高模型性能。
现在我们了解了对比学习是什么,以及它为什么有用,让我们看看对比学习是如何工作。
对比学习如何工作?
在本文中,我将重点介绍SimCLRv2,这是 Google Brain 团队最近提出的最先进的对比学习方法之一。
整个过程可以简明地描述为三个基本步骤:
(1)对于数据集中的每个图像,我们可以执行两种增强组合(即裁剪 + 调整大小 + 重新着色、调整大小 + 重新着色、裁剪 + 重新着色等)。我们希望模型知道这两个图像是“相似的”,因为它们本质上是同一图像的不同版本。
(2)为此,我们可以将这两个图像输入到我们的深度学习模型(Big-CNN,例如 ResNet)中,为每个图像创建向量表示。目标是训练模型输出相似图像的相似表示。
(3)最后,我们尝试通过最小化对比损失函数来最大化两个向量表示的相似性。
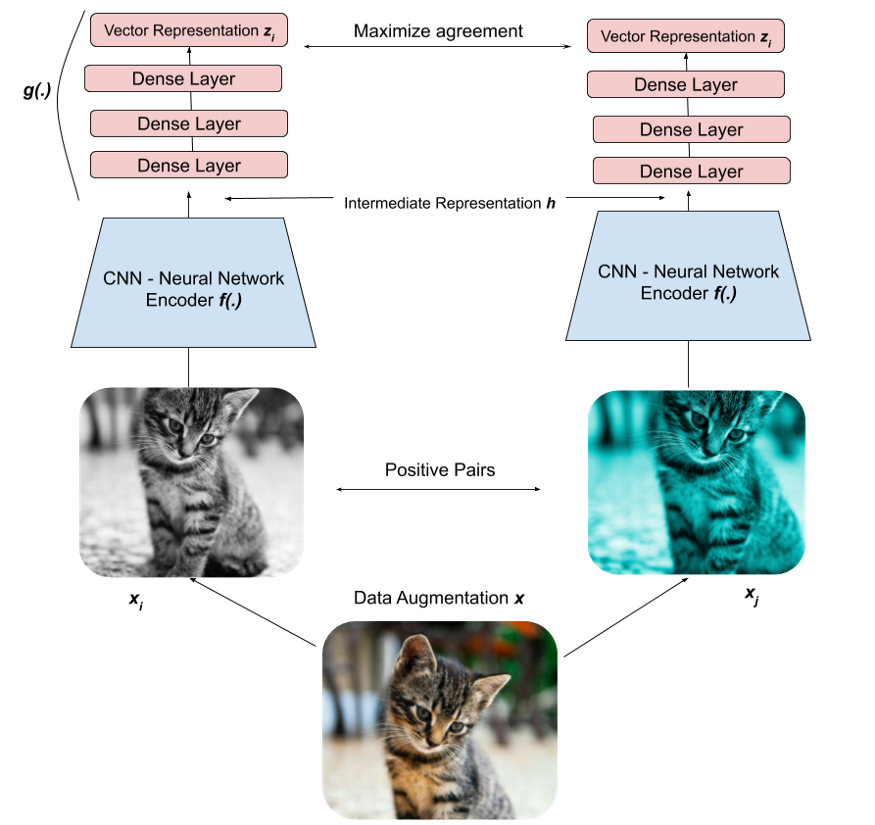 随着时间的推移,模型将了解到猫的两个图像应该具有相似的表示,而猫的表示应该与狗的表示不同。
随着时间的推移,模型将了解到猫的两个图像应该具有相似的表示,而猫的表示应该与狗的表示不同。
这意味着模型能够在不知道图像是什么的情况下区分不同类型的图像!
我们可以通过将其分解为三个主要步骤来进一步剖析这种对比学习方法:数据增强、编码和损失最小化。
1)数据增强

我们随机执行以下增强的任意组合:裁剪、调整大小、颜色失真、灰度。我们对批次中的每张图像执行两次此操作,以创建包含两个增强图像的一对正对(a positive pair)。
2)编码
然后,我们使用我们的Big-CNN神经网络,我们可以认为它是一个简单的函数,
h
=
f
(
x
)
h=f(x)
h=f(x),其中“x”是我们的增强图像之一,以此将我们的两个图像编码为矢量表示。
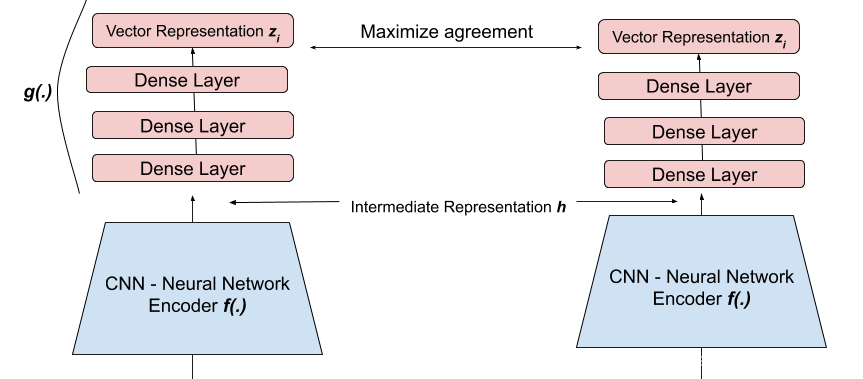
然后,将CNN的输出输入到一组称为projection head的Dense Layers中,
z
=
g
(
h
)
z=g(h)
z=g(h)将数据转换到另一个空间。经验表明,这个额外的步骤可以提高性能。
通过将我们的图像压缩为潜在空间表示,该模型能够学习图像的高阶特征。
事实上,随着我们继续训练模型以最大化相似图像之间的向量相似度,我们可以想象模型正在学习潜在空间中相似数据点的clusters。
例如,猫表示将更接近,但与狗表示更远,因为这是我们训练模型学习的内容。
3)损失最小化
现在我们有两个向量
z
z
z,我们需要一种方法来量化它们之间的相似性。

由于我们正在比较两个向量,因此自然选择余弦相似度,它基于空间中两个向量之间的角度。
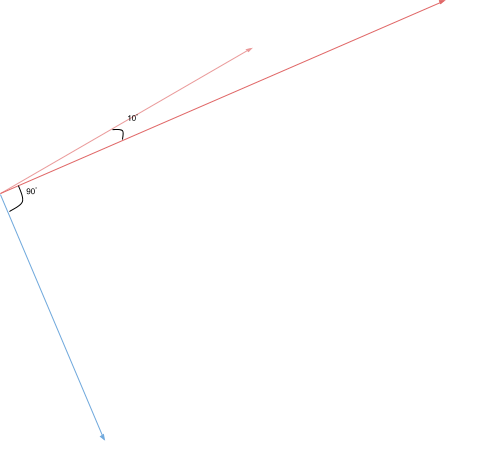
合乎逻辑的是,当向量在空间中靠得越近(它们之间的夹角越小),它们就越相似。因此,如果我们将余弦(两个向量之间的角度) 作为度量,当角度接近 0 时,我们将获得高相似度,否则将获得低相似度,这正是我们想要的。
我们还需要一个可以最小化的损失函数。一种选择是 NT-Xent(标准化温度标度交叉熵损失 Normalized Temperature-Scaled Cross-Entropy Loss)。
我们首先计算两个增强图像相似的概率。
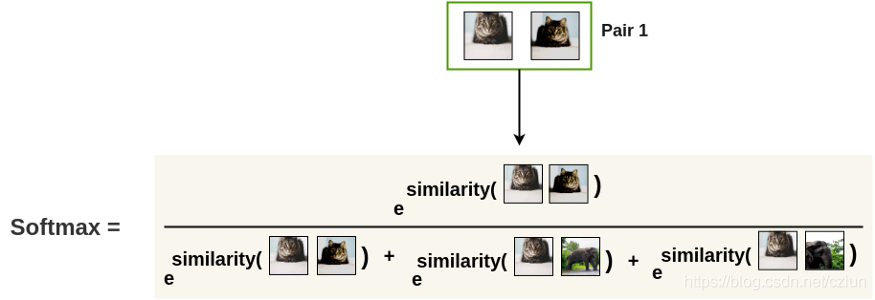
请注意, 分母是
e
s
i
m
i
l
a
r
i
t
y
e^{similarity}
esimilarity(所有对,包含负对)。通过在我们的增强图像和我们批次中的所有其他图像之间创建对来获得负对。
最后,我们将该值包装在
−
l
o
g
(
)
-log()
−log()中,这样最小化这个损失函数对应于最大化两个增强图像相似的概率。

对比学习的应用
半监督学习
当我们的标签很少,或者很难获得特定任务(即临床注释)的标签时,我们希望能够同时使用标记数据和未标记数据来优化模型的性能和学习能力。这就是半监督学习的定义。
一种在文献中得到广泛关注的方法是无监督的预训练、有监督的微调、知识蒸馏范式(knowledge distillation paradigm)。
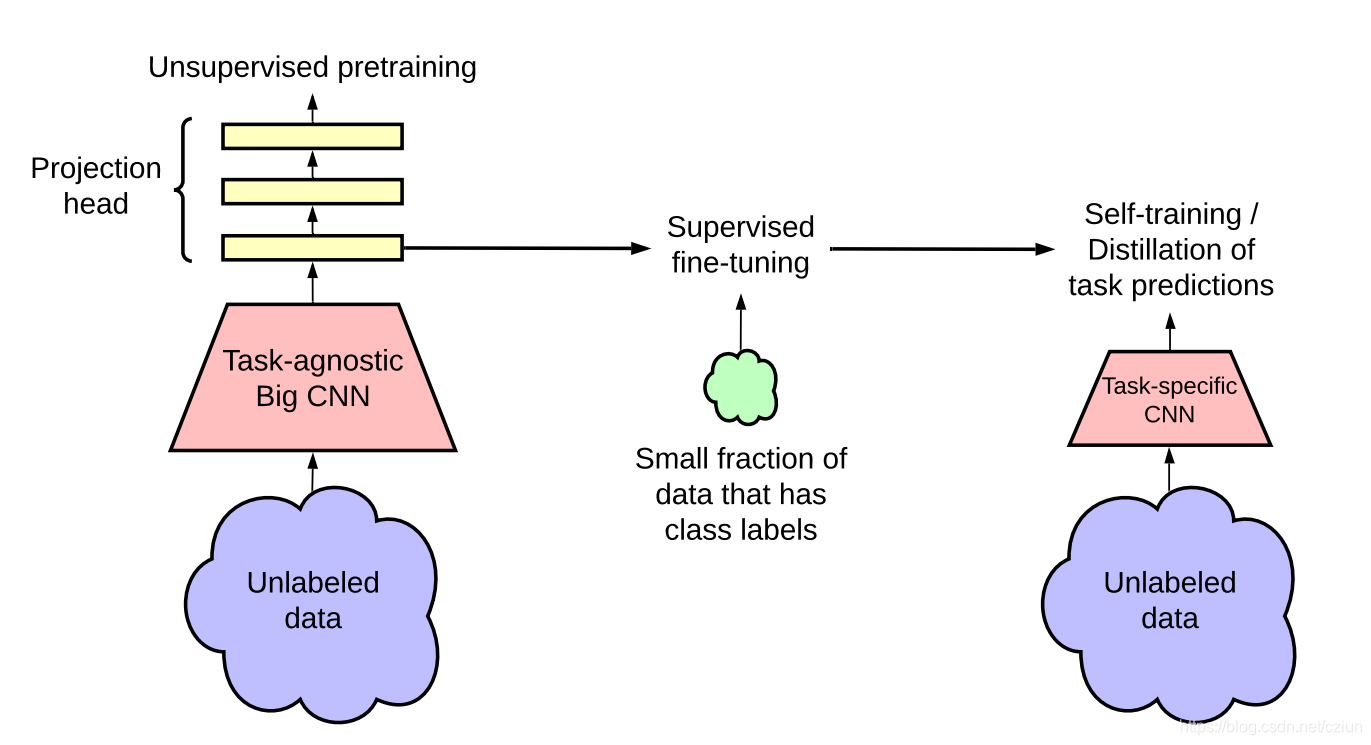
在这个范式中,自监督对比学习方法是一个关键的“预处理”步骤,它允许 Big CNN 模型(即 ResNet-152)在尝试使用有限的标记的图像对图像进行分类之前首先从未标记的数据中学习一般特征数据。
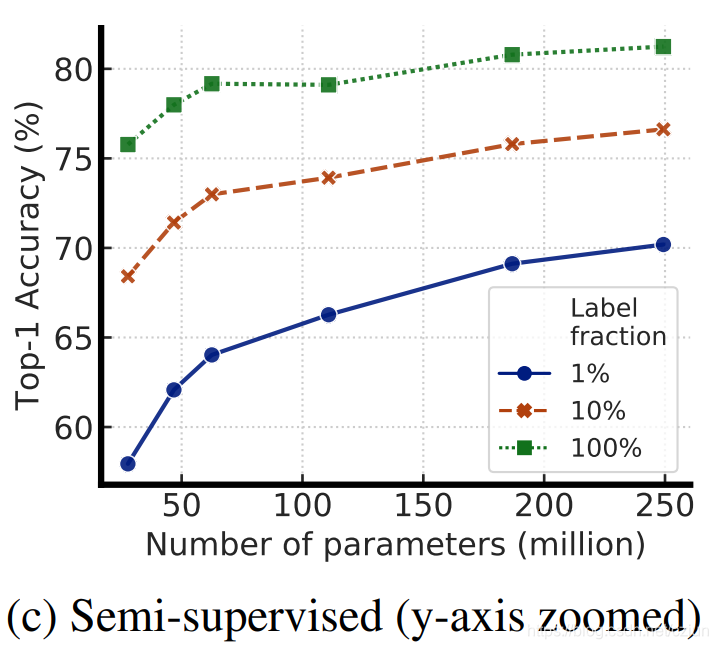
Google Brain 团队证明,这种半监督学习方法的label-efficient非常高,并且更大的模型可以带来更大的改进,尤其是对于低标签分数。
总结
- 对比学习是一种自监督的、与任务无关的深度学习技术,它允许模型学习数据,即使没有标签。
- 该模型通过学习哪些类型的图像相似,哪些不同,来学习数据集的一般特征。
- SimCLRv2是对比学习方法的一个例子,它学习如何表示图像,使得相似的图像具有相似的表示,从而允许模型学习如何区分图像。
- 当标签稀缺时,对数据有一般理解的预训练模型可以针对特定任务进行微调,例如图像分类,以显着提高标签效率,并有可能超越监督方法。
参考:
[1] https://towardsdatascience.com/understanding-contrastive-learning-d5b19fd96607
[2] https://analyticsindiamag.com/contrastive-learning-self-supervised-ml/

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 268
268 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)