Dubbo基础及原理机制
Dubbo是 阿里巴巴公司开源的一个高性能RPC 分布式服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和Spring框架无缝集成,现已成为 Apache 基金会孵化项目
1. 什么是Dubbo?
- Dubbo是 阿里巴巴公司开源的一个高性能RPC 分布式服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和
Spring框架无缝集成,现已成为 Apache 基金会孵化项目。
2. 为什么要用Dubbo?
- 随着服务化的进一步发展,服务之间的调用和依赖关系也越来越复杂,诞生了面向服务的框架体系(SOA),也因此衍生出了一系列相应的技术,如对服务提供、服务调用、连接处理、通性协议、序列号方式、服务发现、服务路由、日志输出等行为进行封装的服务框架。就这样分布式系统的服务治理的框架就出现了,Dubbo就这样产生了,它实现了面向接口代理的 RPC 调用,服务注册和发现,负载均衡,容错,扩展性等等功能。
3. Dubbo的整体架构设计有哪些分层?
大致分为三层:业务层、RPC层、Remoting层
- 接口服务层(Service):与业务逻辑相关,根据provider和consumer的业务设计对应的接口和实现。
- 配置层(Config):用来初始化配置信息,用来管理Dubbo的配置。
- 服务代理层(Proxy):服务接口透明代理,provider和consumer都会生成Proxy,它用来调用远程接口。生成服务的客户端Stub和服务端的Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
- 服务注册层(Registry):封装服务地址的注册和发现,以URL为中心,扩展接口为RegistryFactory、Resitry、RegistryService。
- 路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,扩展接口为 Cluster、Directory、Router 和 LoadBlancce。
- 监控层(Monitor):PRC调用次数和调用时间监控,以Statistics为中心,扩展接口为 MonitorFactory、Monitor 和 MonitorService。
- 远程调用层(Protocol):封装RPC调用的具体过程,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker 和 Exporter。
- 信息交换层(Exchange):封装请求响应模式,同步转异步,以 Request 和Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer。
- 网络传输层(Transport):将网络传输封装成统一接口,可以在这之上扩展更多的网络传输方式,扩展接口为 Channel、Transporter、Client、Server 和 Codec。
10.数据序列层(Serialize): 负责网络传输的序列化和反序列化,扩展接口为 Serialization、ObjectInput、ObjectOutput 和 ThreadPool。
4. Dubbo里面有哪几种节点角色?
| 节点 | 角色说明 |
|---|---|
| Provider | 暴露服务的服务提供方 |
| Consumer | 调用远程服务的服务消费方 |
| Registry | 服务注册与发现的注册中心 |
| Monitor | 统计服务的调用次数和调用时间的监控中心 |
| Container | 服务运行容器 |
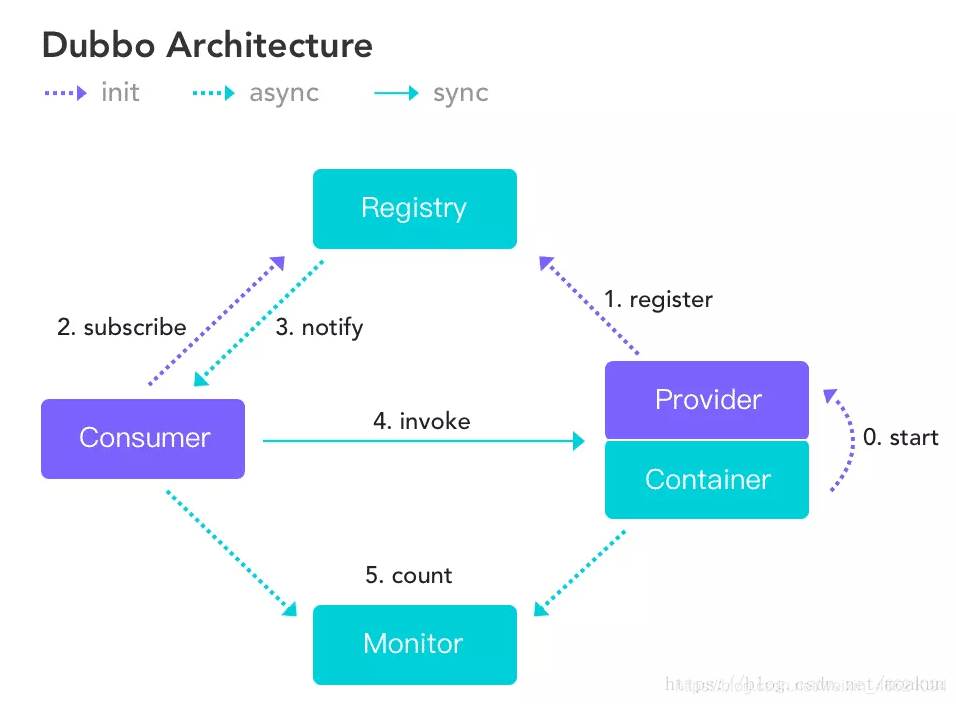
5. 注册与发现的流程图

6. Dubbo核心的配置有哪些?
| 配置 | 配置说明 |
|---|---|
| dubbo:service | 服务配置 |
| dubbo:reference | 引用配置 |
| dubbo:protocol | 协议配置 |
| dubbo:application | 应用配置 |
| dubbo:module | 模块配置 |
| dubbo:registry | 注册中心配置 |
| dubbo:monitor | 监控中心配置 |
| dubbo:provider | 提供方配置 |
| dubbo:consumer | 消费方配置 |
| dubbo:method | 方法配置 |
| dubbo:argument | 参数配置 |
7. 在 Provider 上可以配置的 Consumer 端的属性有哪些?
1)timeout:方法调用超时
2)retries:失败重试次数,默认重试 2 次
3)loadbalance:负载均衡算法,默认随机
4)actives 消费者端,最大并发调用限制
8. Dubbo有哪几种集群容错方案,默认是哪种?
| 集群容错方案 | 说明 |
|---|---|
| Failover Cluster | 失败自动切换,自动重试其他服务器(默认) |
| Failfast Cluster | 快速失败,立即报错,只发起一次调用 |
| Failsafe Cluster | 失败安全,出现异常时,直接忽略 |
| Failback Cluster | 失败自动恢复,记录失败请求,定时重发 |
| Forking Cluster | 并行调用多个服务器,只要一个成功即返回 |
| Broadcast Cluster | 广播逐个调用所有提供者,任意一个报错则报错 |
9. Dubbo有哪几种负载均衡策略,默认是哪种?
| 负载均衡策略 | 说明 |
|---|---|
| Random LoadBalance | 随机,按权重设置随机概率(默认) |
| RoundRobin LoadBalance | 轮询,按公约后的权重设置轮询比率 |
| LeastActive LoadBalance | 最少活跃调用数,相同活跃数的随机 |
| ConsistentHash LoadBalaclava | 一致性Hash,相同参数的请求总是发到同一提供者 |
10. Dubbo原理
10.1 Dubbo服务调用流程

工作流涉及到服务提供者(Provider),注册中心(Registration),网络(Network)和服务消费者(Consumer):
- 服务提供者在启动的时候,会通过读取一些配置将服务实例化。
- Proxy 封装服务调用接口,方便调用者调用。客户端获取 Proxy 时,可以像调用本地服务一样,调用远程服务。
- Proxy 在封装时,需要调用 Protocol 定义协议格式,例如:Dubbo Protocol。
- 将 Proxy 封装成 Invoker,它是真实服务调用的实例。
- 将 Invoker 转化成Exporter,Exporter 只是把 Invoker 包装了一层,是为了在注册中心中暴露自己,方便消费者使用。
- 将包装好的Exporter 注册到注册中心。
- 服务消费者建立好实例,会到服务注册中心订阅服务提供者的元数据。元数据包括服务 IP 和端口以及调用方式(Proxy)。
- 消费者会通过获取的 Proxy 进行调用。通过服务提供方包装过程可以知道,Proxy 实际包装了 Invoker 实体,因此需要使用 Invoker 进行调用。
- 在 Invoker 调用之前,通过 Directory 获取服务提供者的Invoker 列表。在分布式的服务中有可能出现同一个服务,分布在不同的节点上。
- 通过路由规则了解,服务需要从哪些节点获取。
- Invoker 调用过程中,通过 Cluster 进行容错,如果遇到失败策略进行重试。
- 调用中,由于多个服务可能会分布到不同的节点,就要通过 LoadBalance 来实现负载均衡。
- Invoker 调用之前还需要经过Filter,它是一个过滤链,用来处理上下文,限流和计数的工作。
- 生成过滤以后的 Invoker。
- 用 Client 进行数据传输。
- Codec 会根据 Protocol 定义的协议,进行协议的构造。
- 构造完成的数据,通过序列化 Serialization 传输给服务提供者。
- Request 已经到达了服务提供者,它会被分配到线程池(ThreadPool)中进行处理。
- Server 拿到请求以后查找对应的 Exporter(包含有 Invoker)。
- 由于 Export 也会被 Filter 层层包裹,通过Filter 后获得 Invoker最后,对服务提供者实体进行调用。
上面调用步骤经历了这么多过程,其中出现了 Proxy,Invoker,Exporter,Filter。
实际上都是调用实体在不同阶段的不同表现形式,本质是一样的,在不同的使用场景使用不同的实体。
10.2 服务提供者暴露实现原理
上面讲到的服务调用流程中,开始服务提供者会进行初始化,将暴露给其他服务调用。服务消费者也需要初始化,并且在注册中心注册自己。
首先来看看服务提供者暴露服务的整体机制:
在读取配置文件生成服务实体以后,会通过 ProxyFactory 将 Proxy 转换成 Invoker。
此时,Invoker 会被定义 Protocol,之后会被包装成 Exporter。最后,Exporter 会发送到注册中心,作为服务的注册信息。上述流程主要通过 ServiceConfig中的 doExport 完成。
上面截取了服务提供者暴露服务的代码片段,整个暴露过程分为七个步骤:
- 读取其他配置信息到 map 中,用来后面构造 URL。
- 读取全局配置信息。
- 配置不是 remote,也就是暴露本地服务。
- 如果配置了监控地址,则服务调用信息会上报。
- 通过 Proxy 转化成 Invoker,RegistryURL 存放的是注册中心的地址。
- 暴露服务以后,向注册中心注册服务信息。
- 没有注册中心直接暴露服务。
- 一旦服务注册到注册中心以后,注册中心会通过RegistryProtocol 中的 Export 方法将服务暴露出去,并依次做以下操作:
1.委托具体协议进行服务暴露,创建 NettyServer 监听端口,并保持服务实例。
2.创建注册中心对象,创建对应的 TCP 连接。
3.注册元数据到注册中心。
4.订阅 Configurators 节点。
5.如果需要销毁服务,需要关闭端口,注销服务信息。
10.3 服务消费者暴露实现原理

消费者服务在调用服务提供者时,做了以下动作:
- 检查是否是同一个 JVM 内部引用。
- 如果是同一个 JVM 的引用,直接使用 injvm 协议从内存中获取实例。
- 注册中心地址后,添加refer 存储服务消费元数据信息。
- 单注册中心消费。
- 依次获取注册中心的服务,并且添加到 Invokers 列表中。
- 通过Cluster 将多个 Invoker 转换成一个 Invoker。
- 把 Invoker 转换成接口代理。
10.3 服务注册中心暴露实现原理
10.3.1 其主要作用如下:
- 动态载入服务:服务提供者通过注册中心,把自己暴露给消费者,无须消费者逐个更新配置文件。
- 动态发现服务:消费者动态感知新的配置,路由规则和新的服务提供者。
- 参数动态调整:支持参数的动态调整,新参数自动更新到所有服务节点。
- 服务统一配置:统一连接到注册中心的服务配置。
10.3.2 工作原理:
Dubbo 有四种注册中心的实现,分别是 ZooKeeper,Redis,Simple 和 Multicast。
这里着重介绍一下 ZooKeeper 的实现。ZooKeeper 是负责协调服务式应用的。
它通过树形文件存储的 ZNode 在 /dubbo/Service 目录下面建立了四个目录,分别是:
- Providers 目录下面,存放服务提供者 URL 和元数据。
- Consumers 目录下面,存放消费者的 URL 和元数据。
- Routers 目录下面,存放消费者的路由策略。
- Configurators 目录下面,存放多个用于服务提供者动态配置 URL 元数据信息。
客户端第一次连接注册中心的时候,会获取全量的服务元数据,包括服务提供者和服务消费者以及路由和配置的信息。
根据 ZooKeeper 客户端的特性,会在对应 ZNode 的目录上注册一个 Watcher,同时让客户端和注册中心保持 TCP 长连接。
如果服务的元数据信息发生变化,客户端会接受到变更通知,然后去注册中心更新元数据信息。变更时根据 ZNode 节点中版本变化进行。
11. Dubbo集群容错

分布式服务多以集群形式出现,Dubbo 也不例外。在消费服务发起调用的时候,会涉及到 Cluster,Directory,Router,LoadBalance 几个核心组件。
先看看他们是如何工作的:
①生成 Invoker 对象。根据 Cluster 实现的不同,生成不同类型的 ClusterInvoker 对象。通过 ClusertInvoker 中的 Invoker 方法启动调用流程。
②获取可调用的服务列表,可以通过 Directory 的 List 方法获取。这里有两类服务列表的获取方式。
分别是 RegistryDirectory 和 StaticDirectory:
- RegistryDirectory:属于动态 Directory 实现,会自动从注册中心更新 Invoker 列表,配置信息,路由列表。
- StaticDirectory:它是 Directory 的静态列表实现,将传入的 Invoker 列表封装成静态的 Directory 对象。
③在 Directory 获取所有 Invoker 列表之后,会调用路由接口(Router)。其会根据用户配置的不同策略对 Invoker 列表进行过滤,只返回符合规则的 Invoker。
假设用户配置接口 A 的调用,都使用了 IP 为 192.168.1.1 的节点,则 Router 会自动过滤掉其他的 Invoker,只返回 192.168.1.1 的 Invoker。
12. Dubbo远程调用
服务消费者经过容错,Invoker 列表,路由和负载均衡以后,会对 Invoker 进行过滤,之后通过 Client 编码,序列化发给服务提供者。
从上图可以看出在服务消费者调用服务提供者的前后,都会调用 Filter(过滤器)。
可以针对消费者和提供者配置对应的过滤器,由于过滤器在 RPC 执行过程中都会被调用,所以为了提高性能需要根据具体情况配置。
Dubbo 系统有自带的系统过滤器,服务提供者有 11 个,服务消费者有 5 个。过滤器的使用可以通过 @Activate 的注释,或者配置文件实现。
过滤器的使用遵循以下几个规则:
- 过滤器顺序,过滤器执行是有顺序的。例如,用户定义的过滤器的过滤顺序默认会在系统过滤器之后。
- 又例如,上图中 filter=“filter01, filter02”,filter01 过滤器执行就在 filter02 之前。
- 过滤器失效,如果针对某些服务或者方法不希望使用某些过滤器,可以通过“-”(减号)的方式使该过滤器失效。例如,filter=“-filter01”。过滤器叠加,如果服务提供者和服务消费者都配置了过滤器,那么两个过滤器会被叠加生效。
13. Zookeeper中的集群说明
13.1 为什么集群一般都是奇数个?
公式: 当前剩余节点数量 > N/2 集群可以正常的使用!!!
分析1:
1台主机能否搭建集群 1-1 > 0.5??? 1台服务器不能搭建集群的
2台服务器 2-1>1??? 2台服务器也不能搭建集群.
3台服务器 3-1>1.5??? 3台服务器是搭建集群的最小单位.
4台服务器 4-1>2 ??? 4台服务器也能搭建集群
分析2: 为什么集群是奇数台,不是偶数台
3台服务器允许宕机的最大的数量是几台? 3个节点最多允许宕机1台服务器.
4台服务器允许宕机的最大的数量是几台? 4个节点最多允许宕机1台服务器.
结论: 搭建偶数台的容灾效果与奇数台相同,所以从成本的角度考虑,搭建奇数台.
13.2 Zookeeper的集群选举原理
问题1:如果是3台zookeeper 将主机宕机之后,集群内部有高可用机制.谁当主机 B
A: 2181 100万 B:2183 对
问题2: 如果再次将现有的主机宕机,问谁是主机? C
A: 2181 B. 剩余其他服务器 C.没有主机!!!(当前集群奔溃)
问题3: 如果依次初始化1-5台服务器. C 1-7
问1.谁是主机?
问2:哪几台服务器不能当主机?
A: 主机是随机的
都可以当主机,看宕机集群是否正常工作.
B: 由启动顺序决定
1-2的服务器不能当主机
C: t第三台当主机.
1-2的服务器不能当主机.
集群选举的原理: zk集群选举时由启动顺序决定.一般采用最大值(myid)优先策略. 投票数超过半数当选主机.
13.3 Zookeeper(注册中心)的工作原理
步骤:
1.当服务提供者启动时,将自己的IP地址/端口号/服务数据一起注册到注册中心中.
2.当注册中心接收提供者的数据信息之后,会维护服务列表数据.
3.当消费者启动时,会连接注册中心.
4.获取服务列表数据.之后在本地保存记录.
5.当用户需要业务操作时,消费者会根据服务列表数据,之后找到正确的IP:PORT直接利用RPC机制进行远程访问.
6.注册中心都有心跳检测机制.当发现服务器宕机/或者新增服务时.则会在第一时间更新自己的服务列表数据,并且全网广播通知所有的消费者.
</div><div data-report-view="{"mod":"1585297308_001","dest":"https://blog.csdn.net/weixin_46621094/article/details/107568045","extend1":"pc","ab":"new"}"><div></div></div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-60ecaf1f42.css" rel="stylesheet">
</div>
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 34
34 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)