推荐系统之协同过滤算法
1、介绍协同过滤算法(Collaborative Filtering) 是比较经典常用的推荐算法,从1992年一直延续至今。所谓协同过滤算法,基本思想是根据用户的历史行为数据的挖掘发现用户的兴趣爱好,基于不同的兴趣爱好对用户进行划分并推荐兴趣相似的商品给用户。协同过滤算法主要分为两类:- 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品- 基于用户的协同过滤算法:给用户推荐与他兴趣相
1、介绍
协同过滤算法(Collaborative Filtering) 是比较经典常用的推荐算法,从1992年一直延续至今。所谓协同过滤算法,基本思想是根据用户的历史行为数据的挖掘发现用户的兴趣爱好,基于不同的兴趣爱好对用户进行划分并推荐兴趣相似的商品给用户。协同过滤算法主要分为两类:
- 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品
- 基于用户的协同过滤算法:给用户推荐与他兴趣相似的用户喜欢的物品
2、基于用户的协同过滤算法(UserCF)
UserCF,思想其实比较简单,当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A没有听说过的物品推荐给A。如图:
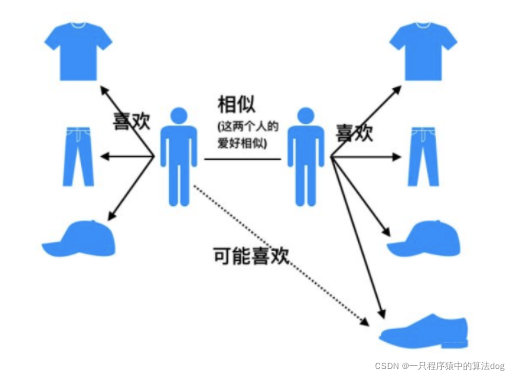
UserCF算法两步骤:
- 找到与当前用户A相似的用户B;
- 将相似用户B喜欢的物品而用户A没有见过的物品推荐给用户A。
那这两步如何做呢?接下来,咱们来个例子具体看一下:
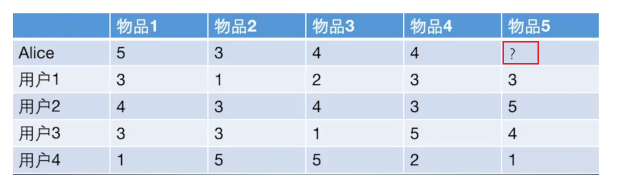
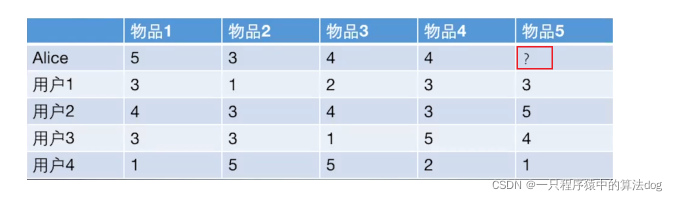
给用户推荐物品的过程可以形象化为给物品打分的过程上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度,分数越高,说明对这个物品越喜欢。
UserCF算法的两个步骤:
- 首先根据前面的这些打分情况(或者说已有的用户向量)计算一下Alice和用户1, 2, 3, 4的相似程度, 找出与Alice最相似的n个用户;
- 根据这n个用户对物品5的评分情况和与Alice的相似程度会猜测出Alice对物品5的评分, 如果评分比较高的话, 就把物品5推荐给用户Alice, 否则不推荐。
2.1计算相似度的几种方式
-
杰卡德(Jaccard)相似系数:
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度),jaccard值越大说明相似度越高。
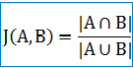
-
余弦相似度:
如图公式所示,余弦相似度衡量了用户向量i和用户向量j之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
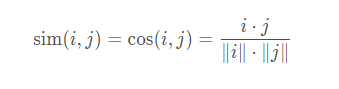
公式中是向量表示,可以换成具体数值,假设用户i和用户j的向量都是n维,那么向量i(x11,x12,x13,…,x1n),j(x21,x22,x23,…,x2n),那么余弦相似度可以表示为
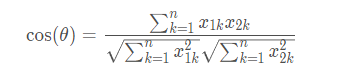
这个在具体实现的时候, 可以使用cosine_similarity进行实现:
from sklearn.metrics.pairwise import cosine_similarity
i = [1, 0, 0, 0]
j = [1, 0.5, 0.5, 0]
consine_similarity([a, b])
- 皮尔逊相关系数:
相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。上公式:
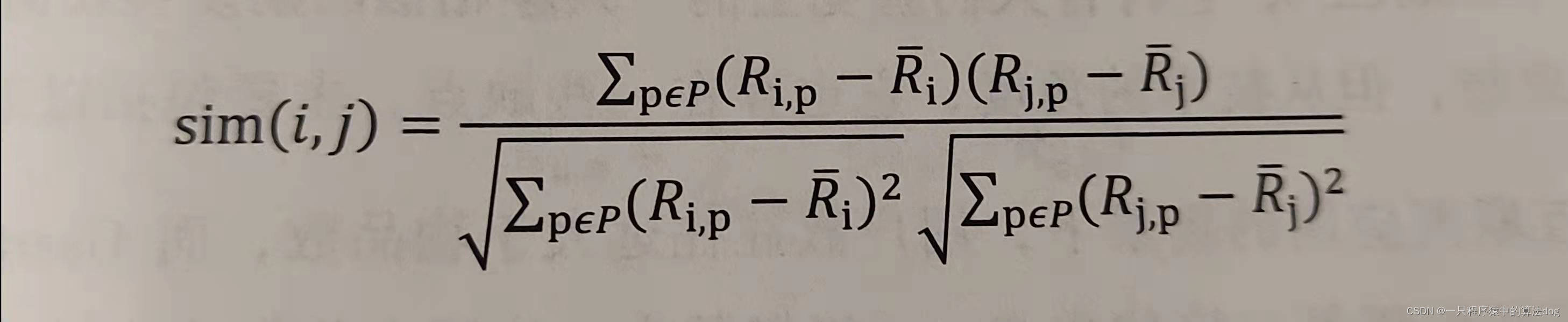
公式中,**Ri,p**代表用户i对物品p的评分。Ri代表用户i对所有物品的平均分,P代表所有物品的集合。
这个在具体实现的时候,可以使用:
from scipy.stats import pearsonr
i = [1, 0, 0, 0]
j = [1, 0.5, 0.5, 0]
pearsonr(i, j)
2.2最终结果的预测
根据上面的几种方法, 我们可以计算出向量之间的相似程度, 也就是可以计算出Alice和其他用户的相近程度, 这时候我们就可以选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值, 那么是怎么计算的呢?
可以根据相似用户的已有评价对目标用户的偏好进行预测。这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。如:

还有一种方式如下, 这种方式考虑的更加全面, 依然是用户相似度作为权值, 但后面不单纯的是其他用户对物品的评分, 而是该物品的评分与此用户的所有评分的差值进行加权平均, 这时候考虑到了有的用户内心的评分标准不一的情况, 即有的用户喜欢打高分, 有的用户喜欢打低分的情况。
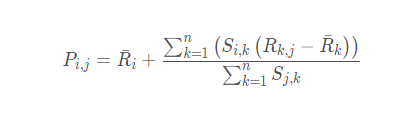
这里的Si,k是用户i和用户k的相似度,Rk,j是用户k对商品j的评分。
2.3根据上边的例子,具体步骤实操一下。
1、计算Alice与其他四个用户的相似度(使用皮尔逊相关系数):

如上,Alice与用户1的相似度为0.85,同样方式可以计算出Alice与用户2、用户3、用户4的相似度为0.7,0,-0.79。如果n=2的话,取最相似的两个用户为用户1和用户2。
2、根据相似度用户计算Alice对物品5的最终得分 用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式:

3、根据用户评分对用户进行推荐 这时候, 我们就得到了Alice对物品5的得分是4.87, 根据Alice的打分对物品排个序从大到小:
物
品
1
>
物
品
5
>
物
品
3
=
物
品
4
>
物
品
2
物品1>物品5>物品3=物品4>物品2
物品1>物品5>物品3=物品4>物品2 这时候,如果要向Alice推荐2款产品的话, 我们就可以推荐物品1和物品5给Alice。
这就是userCF。
3、基于物品的协同过滤(ItemCF)
基于物品的协同过滤(ItemCF)的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c。
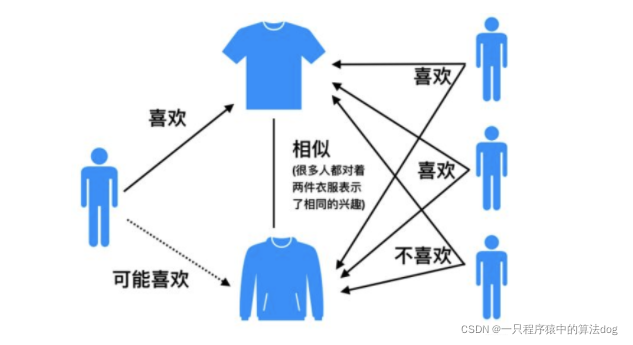
基于物品的协同过滤算法主要分为两步:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表(购买了该商品的用户也经常购买的其他商品)
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面Alice的那个例子来看。
如果想知道Alice对物品5打多少分, 基于物品的协同过滤算法会这么做:
1、首先计算一下物品5和物品1, 2, 3, 4之间的相似性(它们也是向量的形式, 每一列的值就是它们的向量表示, 因为ItemCF认为物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c, 所以就可以基于每个用户对该物品的打分或者说喜欢程度来向量化物品);
2、找出与物品5最相近的n个物品
3、根据Alice对最相近的n个物品的打分去计算对物品5的打分情况
下面我们就可以具体计算一下, 首先是步骤1:

如上,物品5和物品1的相似度为0.9694,同样方式计算出物品5和物品2、物品3、物品4的相似度为:-0.478、-0.4276、0.5816.
如果n=2的话,取最相似的两个物品为物品1和物品4。
接下来,基于上面的公式计算最终得分:

这时候依然可以向Alice推荐物品5。
两大算法介绍结束。
3、UserCF和ItemCF的编程实现
UserCF代码实现
1、先把数据表给建立起
# 定义数据集, 也就是那个表格, 注意这里我们采用字典存放数据, 因为实际情况中数据是非常稀疏的, 很少有情况是现在这样
def loadData():
items={'A': {1: 5, 2: 3, 3: 4, 4: 3, 5: 1},
'B': {1: 3, 2: 1, 3: 3, 4: 3, 5: 5},
'C': {1: 4, 2: 2, 3: 4, 4: 1, 5: 5},
'D': {1: 4, 2: 3, 3: 3, 4: 5, 5: 2},
'E': {2: 3, 3: 5, 4: 4, 5: 1}
}
users={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
}
return items,users
items, users = loadData()
item_df = pd.DataFrame(items).T
user_df = pd.DataFrame(users).T
2、计算用户相似性矩阵
"""计算用户相似性矩阵"""
similarity_matrix = pd.DataFrame(np.zeros((len(users), len(users))), index=[1, 2, 3, 4, 5], columns=[1, 2, 3, 4, 5])
# 遍历每条用户-物品评分数据
for userID in users:
for otheruserId in users:
vec_user = []
vec_otheruser = []
if userID != otheruserId:
for itemId in items: # 遍历物品-用户评分数据
itemRatings = items[itemId] # 这也是个字典 每条数据为所有用户对当前物品的评分
if userID in itemRatings and otheruserId in itemRatings: # 说明两个用户都对该物品评过分
vec_user.append(itemRatings[userID])
vec_otheruser.append(itemRatings[otheruserId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[userID][otheruserId] = np.corrcoef(np.array(vec_user), np.array(vec_otheruser))[0][1]
#similarity_matrix[userID][otheruserId] = cosine_similarity(np.array(vec_user), np.array(vec_otheruser))[0][1]
这里的similarity_matrix就是我们的用户相似性矩阵, 长下面这样:
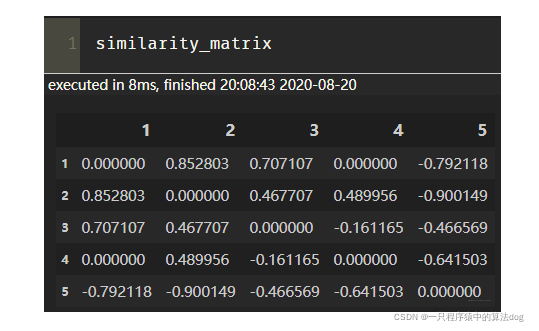
3、计算前n个相似的用户
"""计算前n个相似的用户"""
n = 2
similarity_users = similarity_matrix[1].sort_values(ascending=False)[:n].index.tolist() # [2, 3] 也就是用户1和用户2
4、计算最终得分
"""计算最终得分"""
base_score = np.mean(np.array([value for value in users[1].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for user in similarity_users: # [2, 3]
corr_value = similarity_matrix[1][user] # 两个用户之间的相似性
mean_user_score = np.mean(np.array([value for value in users[user].values()])) # 每个用户的打分平均值
weighted_scores += corr_value * (users[user]['E']-mean_user_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
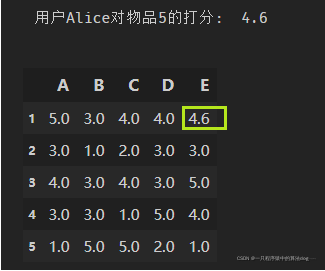
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:
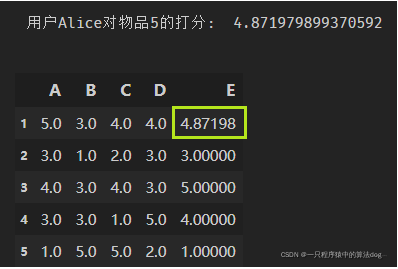
ItemCF代码实现
计算物品的相似矩阵:
"""计算物品的相似矩阵"""
similarity_matrix = pd.DataFrame(np.ones((len(items), len(items))), index=['A', 'B', 'C', 'D', 'E'], columns=['A', 'B', 'C', 'D', 'E'])
# 遍历每条物品-用户评分数据
for itemId in items:
for otheritemId in items:
vec_item = [] # 定义列表, 保存当前两个物品的向量值
vec_otheritem = []
#userRagingPairCount = 0 # 两件物品均评过分的用户数
if itemId != otheritemId: # 物品不同
for userId in users: # 遍历用户-物品评分数据
userRatings = users[userId] # 每条数据为该用户对所有物品的评分, 这也是个字典
if itemId in userRatings and otheritemId in userRatings: # 用户对这两个物品都评过分
#userRagingPairCount += 1
vec_item.append(userRatings[itemId])
vec_otheritem.append(userRatings[otheritemId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[itemId][otheritemId] = np.corrcoef(np.array(vec_item), np.array(vec_otheritem))[0][1]
#similarity_matrix[itemId][otheritemId] = cosine_similarity(np.array(vec_item), np.array(vec_otheritem))[0][1]
物品的相似矩阵,如下:
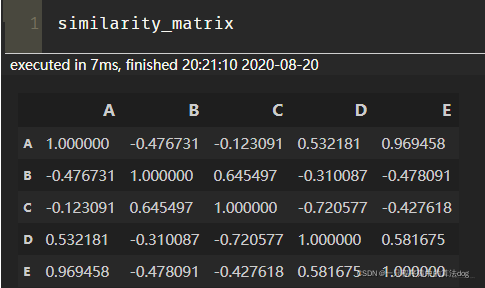
然后也是得到与物品5相似的前n个物品, 计算出最终得分来
"""得到与物品5相似的前n个物品"""
n = 2
similarity_items = similarity_matrix['E'].sort_values(ascending=False)[:n].index.tolist() # ['A', 'D']
"""计算最终得分"""
base_score = np.mean(np.array([value for value in items['E'].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for item in similarity_items: # ['A', 'D']
corr_value = similarity_matrix['E'][item] # 两个物品之间的相似性
mean_item_score = np.mean(np.array([value for value in items[item].values()])) # 每个物品的打分平均值
weighted_scores += corr_value * (users[1][item]-mean_item_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:
4、问题总结
- 什么时候使用UserCF,什么时候使用ItemCF?为什么? 1、UserCF 由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于用户少, 物品多, 时效性较强的场合, 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。对于用户较少, 要求时效性较强的场合, 就可以考虑UserCF。 2、ItemCF 这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合 物品少,用户多 ,用户兴趣固定持久, 物品更新速度不是太快的场合, 比如推荐艺术品, 音乐, 电影。
- 协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?较差的稀疏向量处理能力第一个问题就是泛化能力弱, 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。 比如下面这个例子:
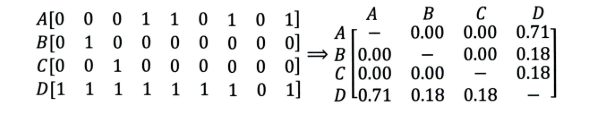
A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。 但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。 所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。
为了解决这个问题, 同时增加模型的泛化能力,2006年,矩阵分解技术(Matrix Factorization,MF)被提出, 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。 具体细节等后面整理, 这里先铺垫一下。 - 上面介绍的相似度计算方法有什么优劣之处? cosine相似度还是比较常用的, 一般效果也不会太差, 但是对于评分数据不规范的时候, 也就是说, 存在有的用户喜欢打高分, 有的用户喜欢打低分情况的时候,有的用户喜欢乱打分的情况, 这时候cosine相似度算出来的结果可能就不是那么准确了。可以考虑使用下皮尔逊相关系数。
- 协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?
协同过滤的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,比较简单高效, 但这也是它的一个短板所在, 由于无法有效的引入用户年龄, 性别,商品描述,商品分类,当前时间,地点等一系列用户特征、物品特征和上下文特征, 这就造成了有效信息的遗漏,不能充分利用其它特征数据。
为了解决这个问题,在推荐模型中引用更多的特征,推荐系统慢慢的从以协同过滤为核心到了以逻辑回归模型为核心, 提出了能够综合不同类型特征的机器学习模型。
参考:
协同过滤算法
AI-RecommenderSystem
王喆 - 深度学习推荐系统

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 168
168 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)