TensorBoard的最全使用教程:看这篇就够了
机器学习通常涉及在训练期间可视化和度量模型的性能。有许多工具可用于此任务。在本文中,我们将重点介绍 TensorFlow 的开源工具套件,称为 TensorBoard,虽然他是TensorFlow 的一部分,但是可以独立安装,并且服务于Pytorch等其他的框架。什么是 TensorBoard?TensorBoard 是一组用于数据可视化的工具。它包含在流行的开源机器学习库 Tensorflow
机器学习通常涉及在训练期间可视化和度量模型的性能。有许多工具可用于此任务。在本文中,我们将重点介绍 TensorFlow 的开源工具套件,称为 TensorBoard,虽然他是TensorFlow 的一部分,但是可以独立安装,并且服务于Pytorch等其他的框架。
什么是 TensorBoard?
TensorBoard 是一组用于数据可视化的工具。它包含在流行的开源机器学习库 Tensorflow 中。TensorBoard 的主要功能包括:
- 可视化模型的网络架构
- 跟踪模型指标,如损失和准确性等
- 检查机器学习工作流程中权重、偏差和其他组件的直方图
- 显示非表格数据,包括图像、文本和音频
- 将高维嵌入投影到低维空间
TensorBoard算是包含在 TensorFlow中的一个子服务。TensorFlow 库是一个专门为机器学习应用程序设计的开源库。Google Brain 于 2011 年构建了较早的 DistBelief 系统。随着其用户群的快速增长,它被简化并重构为我们现在称为 Tensorflow 的库。TensorFlow 随后于 2015 年向公众发布。TensorBoard刚出现时只能用于检查TensorFlow的指标和TensorFlow模型的可视化,但是后来经过多方的努力其他深度学习框架也可以使用TensorBoard的功能,例如Pytorch已经抛弃了自家的visdom(听到过这个名字的人应该都不多了吧)而全面支持TensorBoard。
如何安装 TensorBoard
TensorBoard 包含在 TensorFlow 库中,所以如果我们成功安装了 TensorFlow,我们也可以使用 TensorBoard。要单独安装 TensorBoard 可以使用如下命令:
pip install tensorboard
需要注意的是:因为TensorBoard 依赖Tensorflow ,所以会自动安装Tensorflow的最新版
启动 TensorBoard
1、本地启动TensorBoard
要启动 TensorBoard,打开终端或命令提示符并运行:
tensorboard --logdir=<directory_name>
将
directory_name
标记替换为保存数据的目录。默认是“logs”。
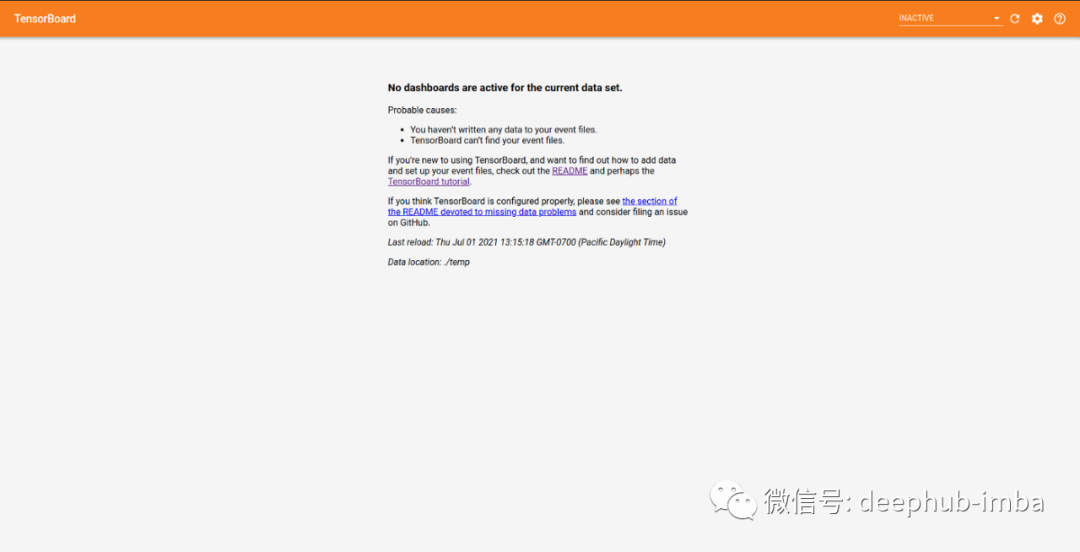
运行此命令后,我们将看到以下提示:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass –bind_allTensorBoard 2.2.0 at http://localhost:6006/ (Press CTRL+C to quit)
这说明 TensorBoard 已经成功上线。我们可以用浏览器打开http://localhost:6006/查看。
当页面第一次打开时,我们将看到如下内容:
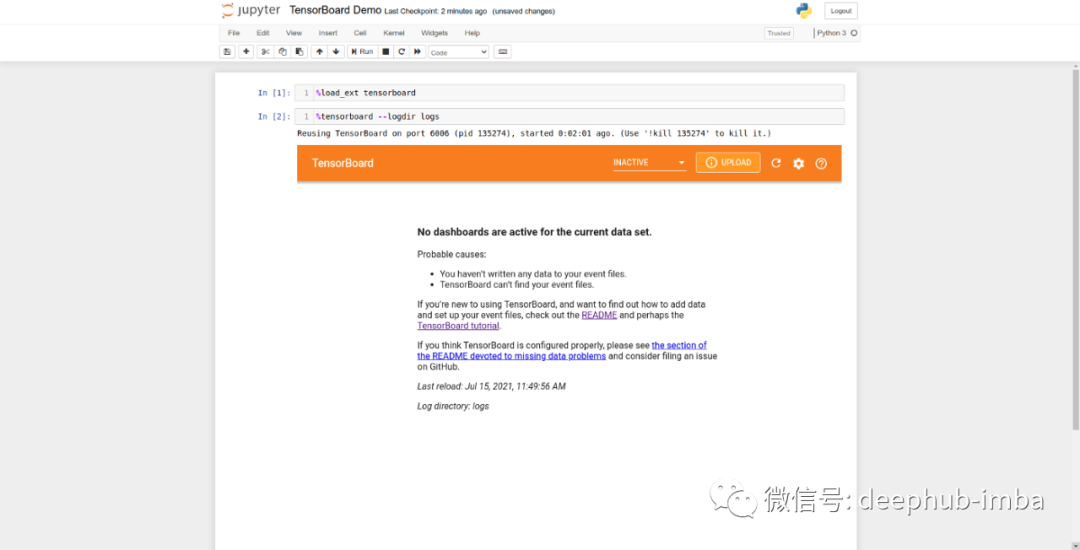
2、在 Jupyter Notebooks 中使用 TensorBoard
如果想在 Jupyter Notebooks 中使用 TensorBoard,可以使用以下命令:
%load_ext tensorboard
运行这行代码将加载 TensorBoard并允许我们将其用于可视化。加载扩展后,我们现在可以启动 TensorBoard:
%tensorboard --logdir logs
3、将 TensorBoard 与 Google Colab 一起使用
使用 Google Colab 时,一旦创建一个新的 notebook,TensorFlow 和 TensorBoard 就已经安装好了。要运行它,我们可以遵循与 Jupyter Notebooks 概述的相同过程。只需在笔记本单元格中输入以下内容:
%load_ext tensorboard
我们会看到 TensorBoard 应用程序。
使用TensorBoard
我们已经启动并运行 TensorBoard,下面以TensorFlow 为例介绍如何使用TensorBoard
1、本地使用 TensorBoard
TensorBoard callback 在 TensorFlow 库提供的回调。它是如何工作的?
根据 Keras 文档,回调是可以在训练的各个阶段执行操作的对象。当我们想在训练过程中的特定时间节点(例如,在每次epoch/batch之后)自动执行任务时,我们都可以使用回调。
如何使用 TensorBoard callback 的快速示例。
首先,使用 TensorFlow 创建一个简单的模型,并在 MNIST 数据集上对其进行训练。
import tensorflow as tf
# Load and normalize MNIST data
mnist_data = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist_data.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
# Define the model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
编译模型后,我们需要创建一个回调并在调用
fit
方法时使用。
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")
现在可以在模型上调用
fit
方法时将回调作为参数传入。在工作目录中创建了
logs
文件夹,并将其作为参数传递给
log_dir
。下面调用 fit 并将其作为回调传入。
model.fit(X_train, y_train, epochs=5, callbacks=[tf_callback])
调用fit方法后,进入localhost:6006查看结果。
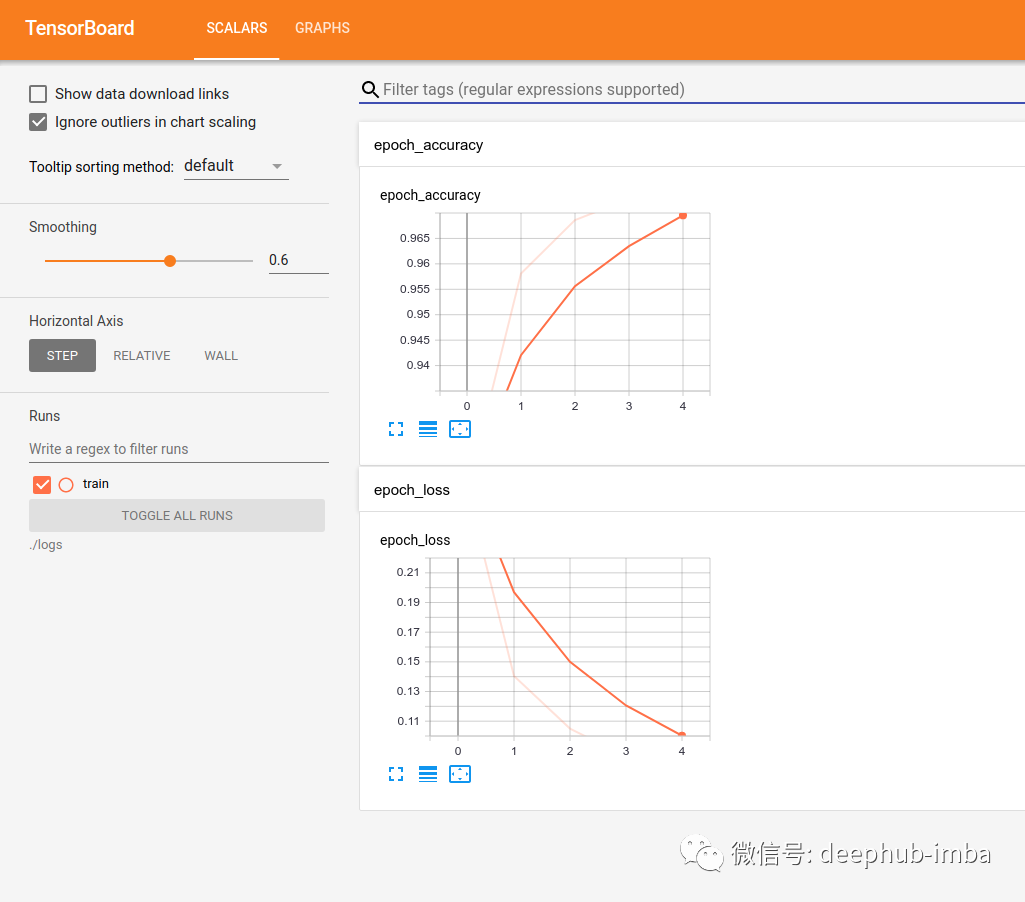
我们看到了一个两个不同的图表。第一个显示了模型在每个epoch的准确性。第二个显示的损失。
2、远程运行 TensorBoard
除了在本地运行之外,还可以远程运行 TensorBoard。如果我们在具有更强大 GPU 的不同服务器之间进行并行训练,也可以本地检查结果。
首先, 使用SSH 并将远程服务器的端口映射到本地的计算机。
ssh -L 6006:127.0.0.1:6006 username@server_ip
然后只需要在远程服务器上启动 TensorBoard。在远程服务器上运行:
tensorboard --logdir=’logs’ --port=6006
我们可以访问 localhost:6006 来查看远程的TensorBoard。
TensorBoard 仪表板
TensorBoard 仪表板由用于可视化数据的不同组件组成。我们将深入研究每一个组件。
1、TensorBoard Scalars
机器学习过程需要跟踪与模型性能相关的不同指标。这对于快速发现问题并确定模型是否过度拟合等非常重要。
使用 TensorBoard 的 Scalars Dashboard,可以可视化这些指标并更轻松地调试模型。第一个示例,在 MNIST 数据集上绘制模型的损失和准确性,使用的就是Scalars。
创建回调、指定一个目录来记录数据、在调用 fit 方法时传递回调。这种方式适用于大多数情况,但是如果我们想要记录一个不容易获得的自定义Scalars怎么办?可以使用 TensorFlow 的 Summary API。这个特殊的 API 用于收集摘要数据,以便以后的可视化和分析。
让我们看一个例子来更好地理解这一点。使用一个简单的正弦波作为想要在 TensorBoard 上显示的Scalars。
# Specify a directory for logging data
logdir = "./logs"
# Create a file writer to write data to our logdir
file_writer = tf.summary.create_file_writer(logdir)
# Loop from 0 to 199 and get the sine value of each number
for i in range(200):
with file_writer.as_default():
tf.summary.scalar('sine wave', np.math.sin(i), step=i)
tf.summary 中的 scalar 方法,可以记录几乎任何我们想要的标量数据。使用 TensorBoard 时,不仅限于损失和指标。运行上述命令后仪表板的输出如下:
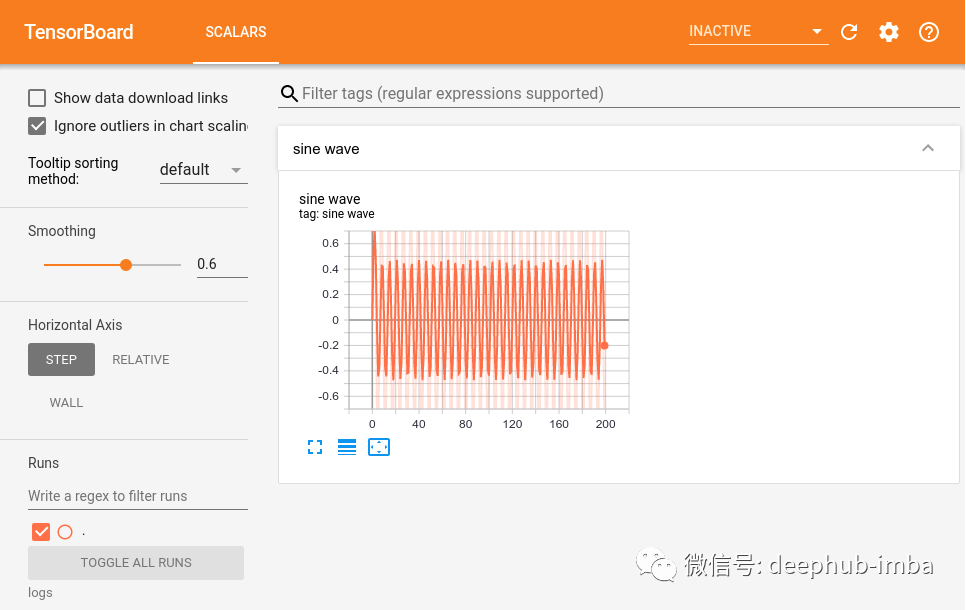
2、TensorBoard Images
在处理图像数据时,如果希望查看数据查找问题,或者查看样本以确保数据质量,则可以使用 TensorBoard 的 Image Summary API。
继续回到 MNIST 数据集,看看图像在 TensorBoard 中是如何显示的:
# Load and normalize MNIST data
mnist_data = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist_data.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
将数据的第一张图像并将其可视化。
# Reshape the first image
img = np.reshape(X_train[0], (-1, 28, 28, 1))
# Specify a directory for logging data
logdir = "./logs"# Create a file writer to write data to our logdir
file_writer = tf.summary.create_file_writer(logdir)
# With the file writer, log the image data
with file_writer.as_default():
tf.summary.image("Training data", img, step=0)
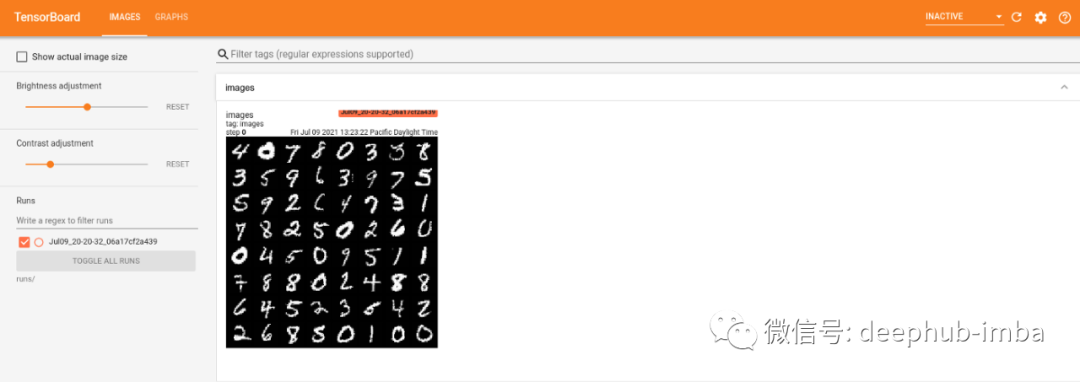
查看图像需要选择IMAGES选项:
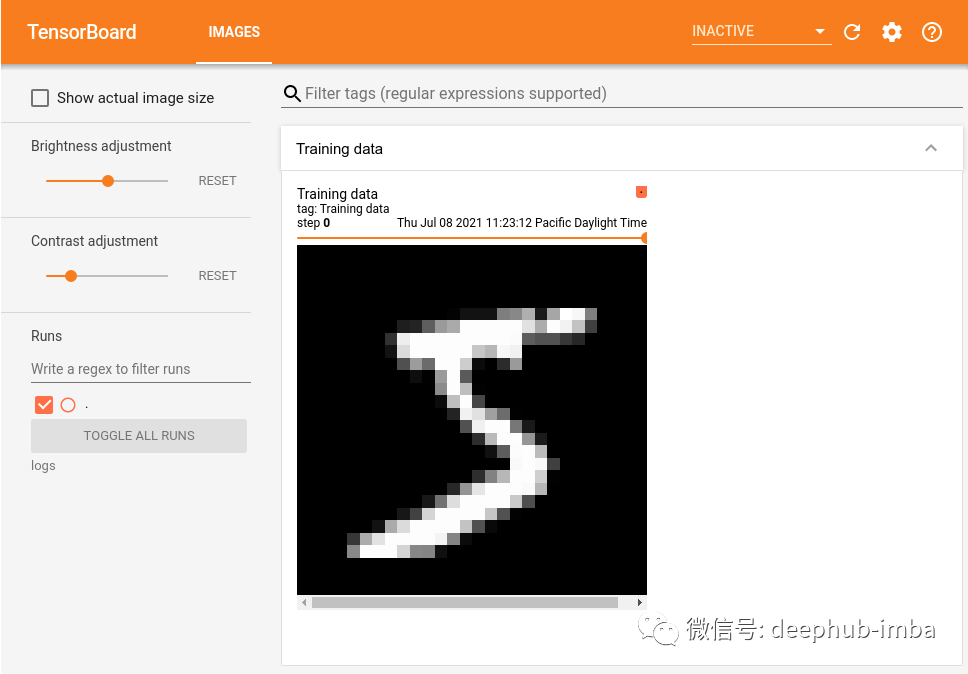
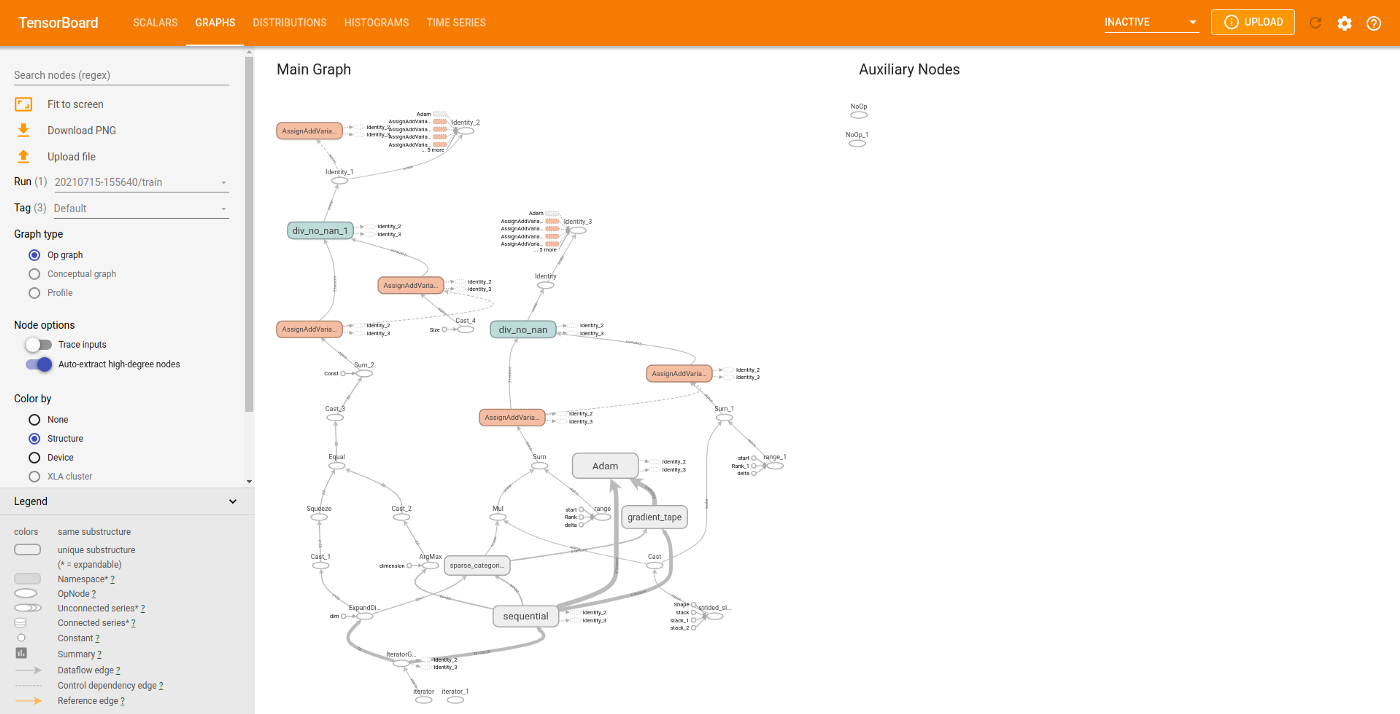
3、TensorBoard Graphs
所有模型都可以看作是一个计算图。有时很难通过单独查看代码来了解模型的体系结构。对其进行可视化可以很容易看到模型的结构, 也能够确保使用的架构是我们想要或设计的。
下面可视化之前用于 MNIST 数据集的模型。下面是模型定义。
# Define the model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
还需要创建一个 TensorBoard 回调并在训练模型时使用它。
# Create a callback
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")
# Pass in the callback when fitting the model
model.fit(X_train, y_train, epochs=5, callbacks=[tf_callback])
训练后,查看Graphs 选项:
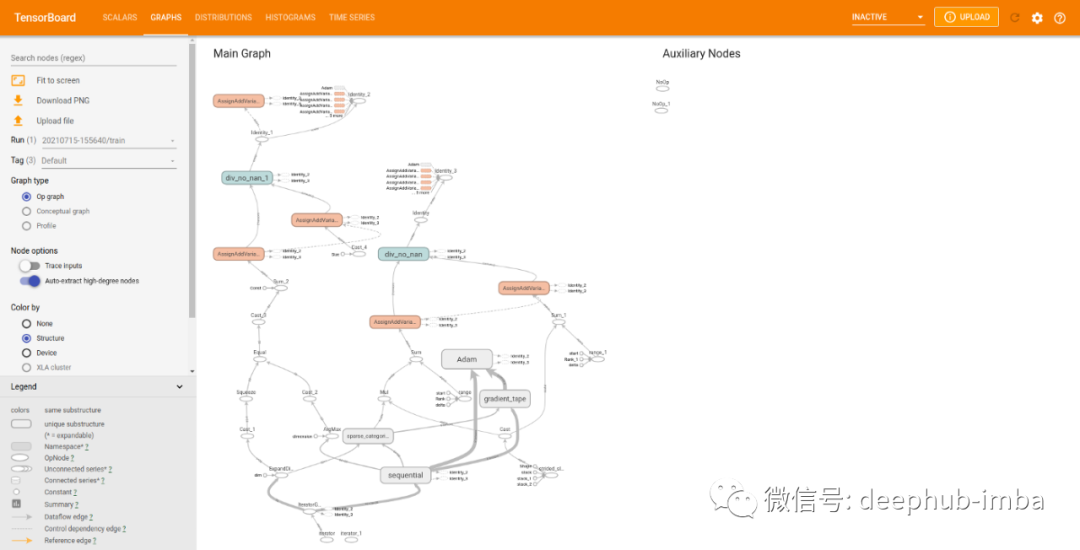
这里显示的是模型的操作级图(逐层显示模型架构)。这对于查看我们的模型是否正确以及每一层是否符合我们的预期非常重要。该图的数据从底部流向顶部。
如果需要,还可以查看概念图。在侧边栏中找到 Tag 标题并将其更改为 Keras:
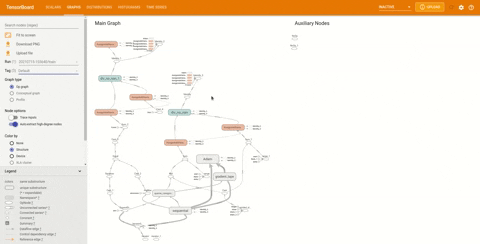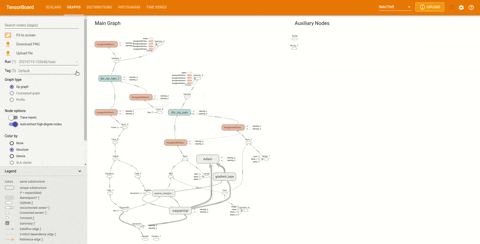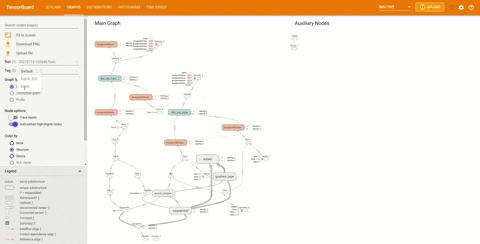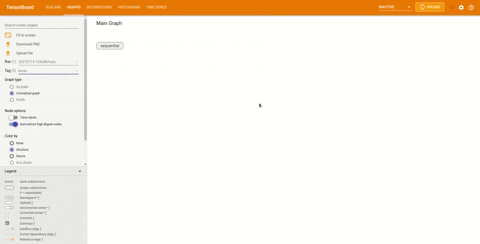
可以查看模型的结构是否正确。图中的节点表明模型是一个顺序模型。
4、TensorBoard Distributions and Histograms 分布和直方图
TensorBoard 分布和直方图是跟踪模型另一种好方法。使用官方提供的回调,在训练后TensorBoard 上会显示几个选项。如果我们转到Distributions 选项卡,将看到如下图:
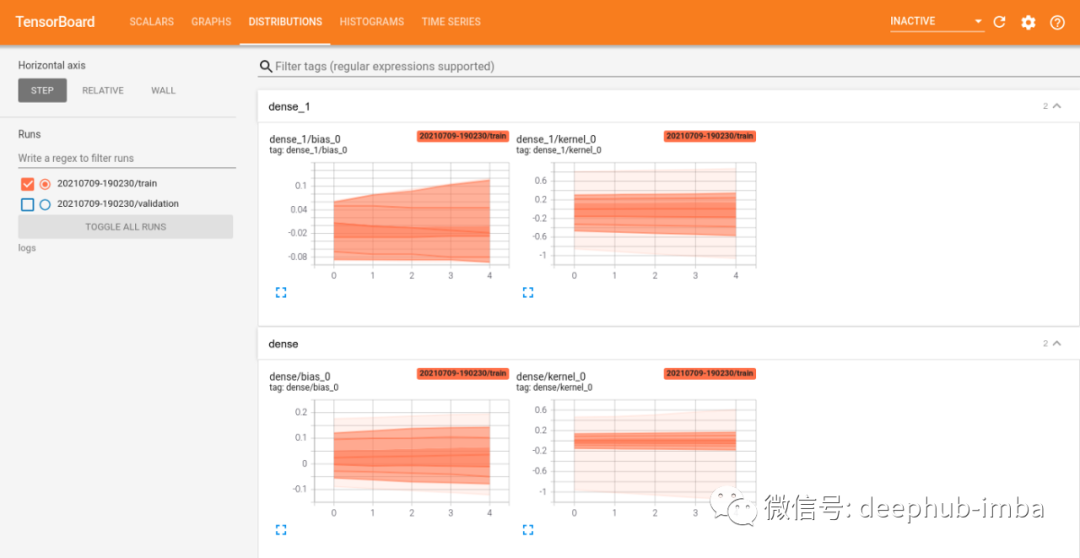
这组图表显示了构成模型的张量。在每个图的水平轴上显示 epoch 数,在垂直轴上显示了每个张量的值。这些图表基本上显示了这些张量如何随着训练的进行而随时间变化。较暗的区域显示值在某个区域停留了更长的时间(没更新)。如果担心模型权重在每个epoch 都没有正确更新,可以使用此选项发现这些问题。
我们在Histograms选项上看到了一组不同的图表,它们表示模型的张量。
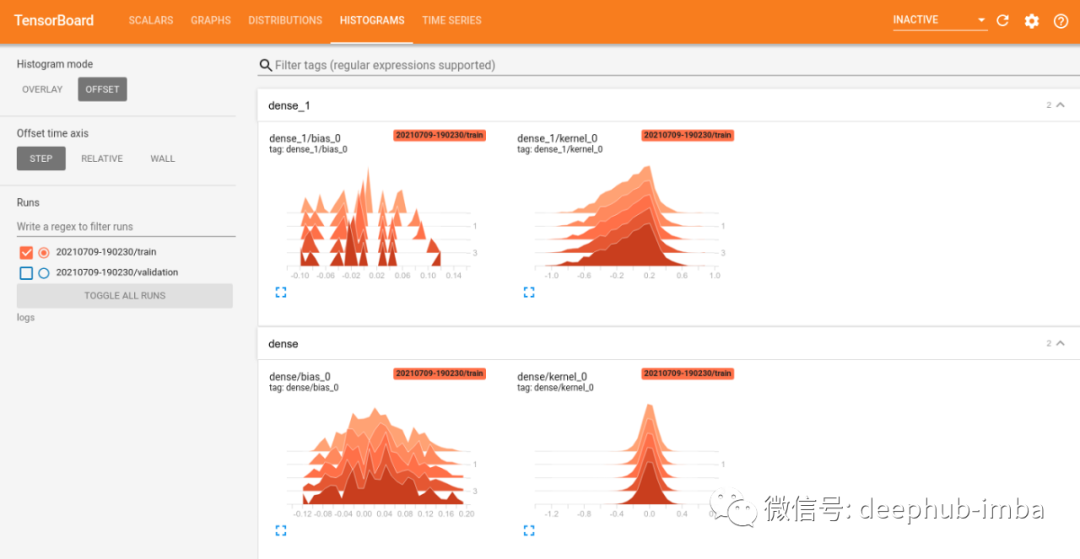
这些图显示了模型中张量的不同视图。每个图都有五个相互堆叠的直方图,代表训练过的五个epoch中的每一个。它们显示了张量权重倾向于集中在哪个区域的信息。这对于调试模型的行为,发现异常非常有用。
5、TEXT
文本是创建机器学习模型时常用的数据类型。很多时候,很难将文本数据可视化。TensorBoard可以使用 Text Summary API 轻松地可视化文本数据。让我们看看它是如何工作的。
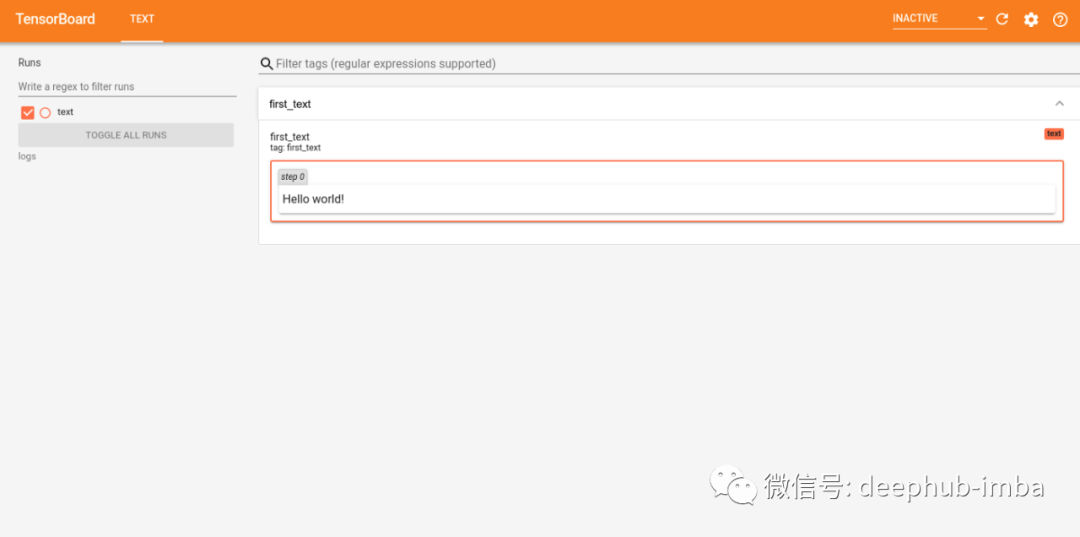
使用文本 Hello World 作为一个简单的示例。
# Our sample text
sample_text = "Hello world!"
# Specify a directory for logging data
logdir = "./logs/text/"
# Create a file writer to write data to our logdir
file_writer = tf.summary.create_file_writer(logdir)
# With the file writer, log the text data
with file_writer.as_default():
tf.summary.text("sample_text", sample_text, step=0)
TensorBoar的Text 选项卡中输入的文本。
6、TensorBoard projector 投影
深度学习模型通常适用于具有大量维度的数据。可视化这些维度可以让我们深入了解提高模型的性能。TensorBoard 提供一个嵌入的投影,可以轻松的可视化高维数据。
首先,需要从 TensorBoard 导入投影插件。
from tensorboard.plugins import projector
我们将使用 IMDB 电影评论数据集来可视化嵌入。
import os
import tensorflow as tf
import tensorflow_datasets as tfds
# Load the data
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,)encoder = info.features["text"].encoder
# Create training batches
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
# Create testing batches
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
# Get the first batch
train_batch, train_labels = next(iter(train_batches))
在上面的代码中,加载并预处理数据,下面代码将创建一个简单的模型来为文本生成嵌入,训练模型 epoch=1 并可视化结果。
# Create an embedding layer
embedding_dim = 16
embedding = tf.keras.layers.Embedding(
encoder.vocab_size,
embedding_dim)
# Configure the embedding layer as part of a Keras model
model = tf.keras.Sequential([
embedding,
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),])
# Compile the model
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train the model for a single epoch
history = model.fit(
train_batches, epochs=1, validation_data=test_batches
)
拟合模型时需要将数据写入
logdir
,类似于我们在前面部分中所做的。
# Set up a log dir, just like in previous sections
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save labels separately in a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown"
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by
# `/.ATTRIBUTES/VARIABLE_VALUE`
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
在TensorBoard 右上角的下拉菜单中的projector选项可以查看可视化的嵌入:
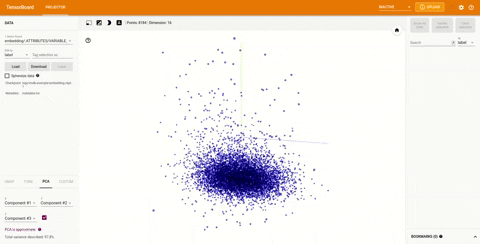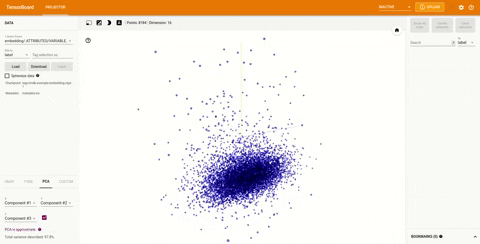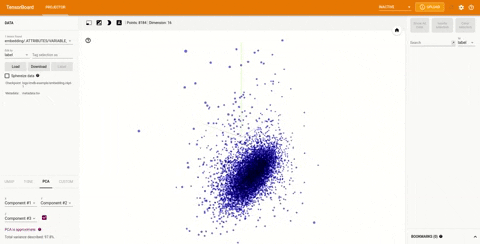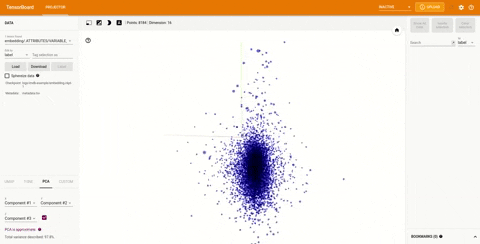
TensorBoard 插件
TensorBoard 还提供了很多不同的插件可以帮助我们完成各种不同的需求,下面介绍一些非常有用的插件
1、TensorFlow Profiler
TensorFlow Profiler 用于分析 TensorFlow 代码的执行情况。这很重要,因为我们想知道正在运行的模型是否得到了适当的优化。这里需要安装了Profiler插件。
pip install tensorboard_plugin_profile
创建一个模型,然后在拟合时使用 TensorBoard 回调。
# Create a callback
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")
# Pass in the callback when fitting the model
model.fit(X_train, y_train, epochs=5, callbacks=[tf_callback])
当进入 TensorBoard 页面时,我们将看到一个名为 Profile 的新选项。切换到此选项,将看到类似于下图的内容。
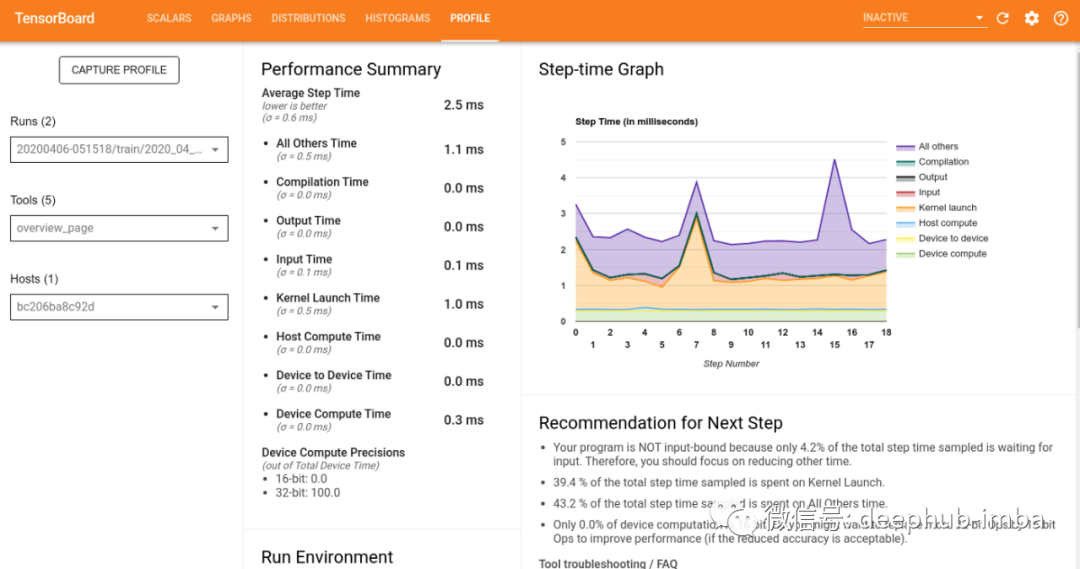
这是有很多信息的概览页面,所以让我们分解一下:
- 页面右上角有一个 Step-time 图,显示训练过程的哪些部分花费的时间最多。可以看到模型不是输入绑定的,很多时间都花在了启动内核上。
- 还看到了一些优化模型性能的建议
- 在我们的例子中,计算都没有使用 16 位操作,可以通过转换提高性能。
在左侧,有一个名为“Tools”的下拉菜单。可以选择 Trace Viewer 来查看模型性能的瓶颈出现在哪里。Trace Viewer 显示分析期间发生的 GPU 和 CPU 事件的时间线。
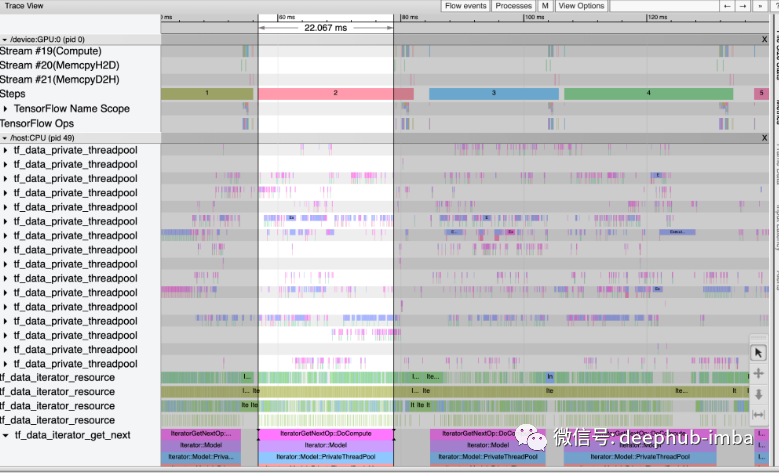
垂直轴显示具有不同跟踪事件的事件组。从 CPU 和 GPU 收集跟踪事件。每个矩形都是一个单独的跟踪事件。可以单击其中任何一个来关注跟踪事件并对其进行分析。还可以拖动光标一次选择多个事件。
在“Tools”下拉列表中,还可以使用“input_pipeline_analyzer”,可以根据收集的数据查看模型的输入管道性能。
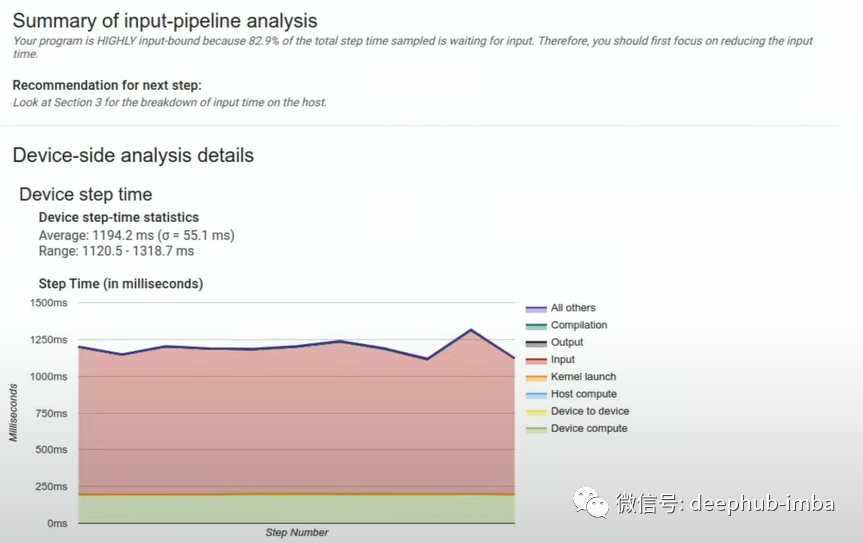
这里可以告诉我们模型是否是输入绑定的。例如上图意味着模型花费大量时间等待输入而不是运行推理。它还可以告诉我们管道中的哪个阶段最慢。
为了更深入地了解不同的 TensorFlow 操作,还有另一个名为 TensorFlow stats 选项,可以显示模型正在执行的不同操作的细分。
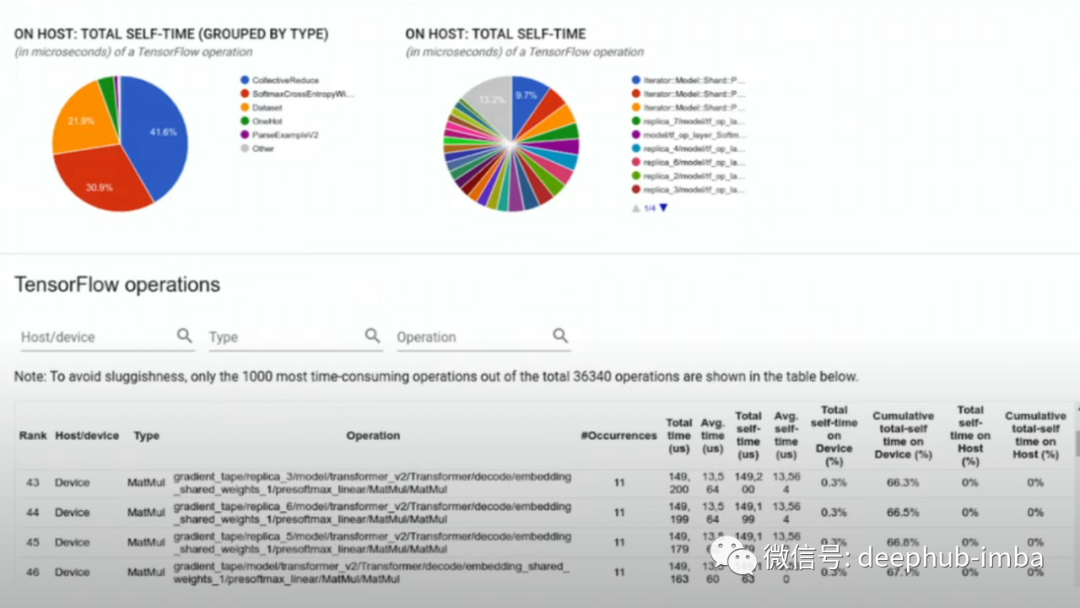
运行模型时,饼图显示了正在计算的不同操作。包括编码、矩阵乘法等计算,以及需要执行的许多其他推理操作。在优化模型时,可以关注其中哪些花费最多的时间的操作。
2、Fairness Indicators Dashboard
Fairness Indicators Dashboard 帮助我们计算二进制和多类分类器的不同公平指标。可以评估模型在不同运行中的公平性,并比较它们在不同组之间的性能。
要开始在我们的数据上使用 Fairness Indicators Dashboard,需要安装一些依赖:
pip install fairness_indicators
pip install tensorboard-plugin-fairness-indicators
导入插件:
from tensorboard_plugin_fairness_indicators import summary_v2
summary_v2
的使用方法与在前面章节中将数据记录到
logdir
时使用
tf.summary
一样。
# Create a file writer to write data to our logdir
file_writer = tf.summary.create_file_writer(logdir)
# Write data to our result directory
with file_writer.as_default():
summary_v2.FairnessIndicators(result_dir, step=1)
结果如下:
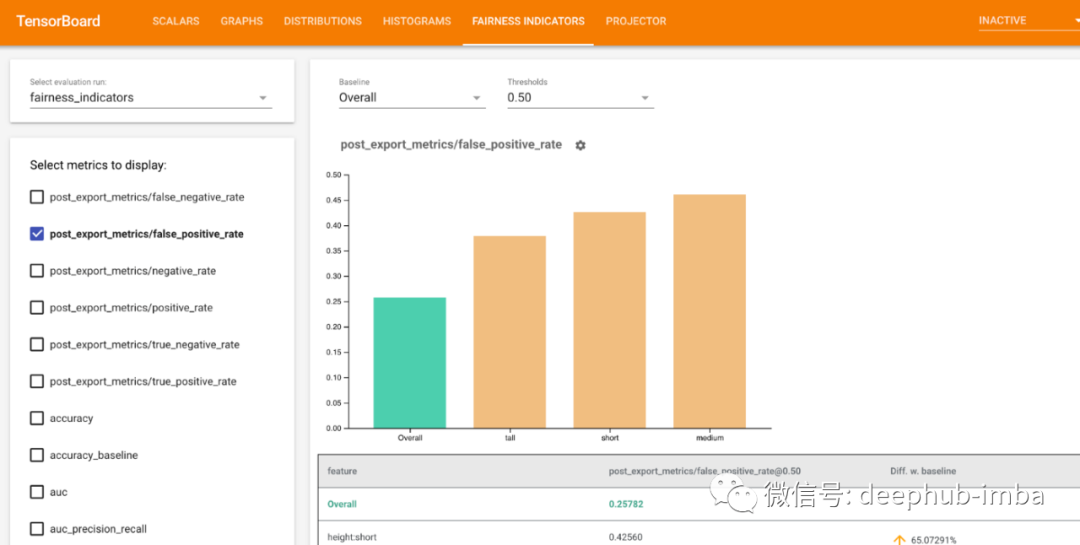
在 TensorBoard 中会有一个新的Fairness Indicators 选项卡。在这里,可以查看模型预测的不同类别值的细分以及它们与基线的百分比差异,以确定模型是否公平。
使用 What-If 工具了解模型
TensorBoard 附带一个假设分析工具 (WIT),可以帮助我们理解黑盒分类和回归模型。使用这个工具,可以对一组数据进行预测,并以不同的方式可视化结果。
也可以手动或以编程方式编辑示例,查看更改它们如何影响模型的预测。
要使用 WIT需要提供模型和数据,如果想要更深入的探索模型必须带有分类、回归或预测 API 的 TensorFlow Serving 进行部署。
另外要进行预测的数据集应该以 TFRecord 格式存储,并且可以由我们运行 TensorBoard 的服务器访问。
设置完成后,转到 TensorBoard Dashboard 并从页面右上角的下拉菜单中选择 What-If Tool 选项。应该看到一个如下所示的页面:
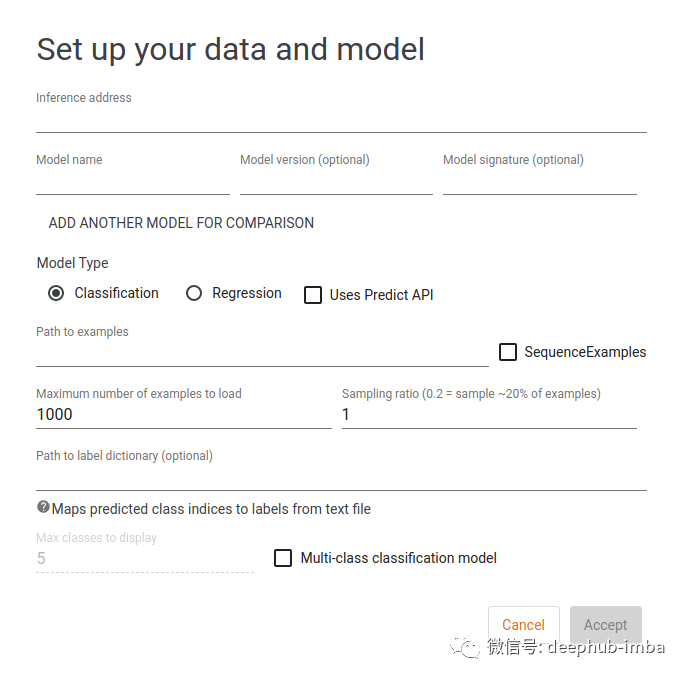
第一个字段是提供模型的推理地址。如果在本地提供TensorFlow Serving ,这将等于
localhost:port
。还需要输入模型名称、可选的模型版本和模型的签名。
输入数据所在的路径。上面提到的
TFRecord
文件。
最后单击Accept按钮,我们就会跳转到结果页面。
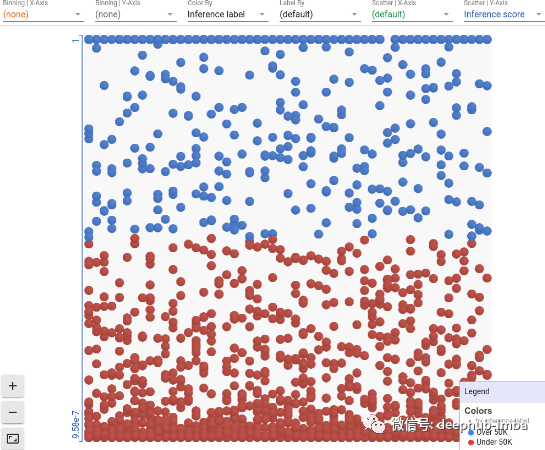
数据集中的每个点现在都根据它们的类进行着色。可以对数据进行分箱、分桶、创建散点图和对数据点进行不同着色等操作。
将 TensorBoard 数据作为 DataFrame进行访问
TensorBoard 主要是一个用于可视化数据的 GUI 工具。但是一些用户可能希望以编程方式与 TensorBoard 数据进行交互,例如自定义可视化和临时的分析。所以可以将 TensorBoard 数据作为 DataFrame 访问,这样可以在单独的程序中使用。
这个API 仍处于试验阶段,因此可能后续版本还会有重大的更改。
我们只需将“logdir”上传到 TensorBoard.dev 才能使用此功能,这部分我们需要一些依赖项。首先需要确认已经安装了 Pandas。还需要一种可视化数据的方法。常用的库是 Matplotlib 和 Seaborn。
TensorBoard.dev 上的 TensorBoard
logdir
被称为experiment。每个experiment都有一个唯一的 ID,我们可以使用它以编程方式访问数据。
# Change the experiment id to our own
experiment_id = "insert experiment ID here"
# Get the experiment using the id
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
# Save the scalars to a dataframe
df = experiment.get_scalars()
现在df 中拥有所有可用的 logdir 数据。
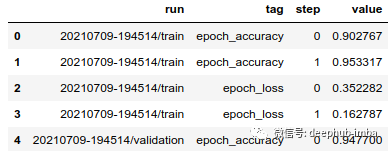
现在可以像操作任何其他 DataFrame 一样操作它来进一步分析。
将 TensorBoard 与 PyTorch 结合使用
PyTorch 是另一个深受研究人员欢迎的深度学习框架。PyTorch 现在也已经支持 TensorBoard了。
在使用 TensorFlow 时,使用 Summary API 创建了将数据记录到
logdir
文件夹的对象。在使用 PyTorch 时,官方也提供了类似的API。
# Import the summary writer
from torch.utils.tensorboard import SummaryWriter# Create an instance of the object
writer = SummaryWriter()
这样就可以使用与 TensorFlow 相同的方式处理的相同 MNIST 数据集。
import torch
import torchvision
from torchvision import datasets, transforms
# Compose a set of transforms to use later on
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# Load in the MNIST dataset
trainset = datasets.MNIST(
'mnist_train',
train=True,
download=True,
transform=transform
)
# Create a data loader
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=64,
shuffle=True
)
# Get a pre-trained ResNet18 model
model = torchvision.models.resnet18(False)
# Change the first layer to accept grayscale images
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
# Get the first batch from the data loader
images, labels = next(iter(trainloader))
# Write the data to TensorBoard
grid = torchvision.utils.make_grid(images)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
运行此程序后,转到 TensorBoard 并查看保存的输出。
得到了与使用 TensorFlow 时相似的输出。
使用 TensorBoard.dev 上传和共享结果
TensorBoard.dev 是 TensorBoard 的一个组件,它允许我们在网络上托管机器学习结果。 对于那些渴望展示他们的成果的人来说这是适合的工具。
可以使用以下命令从终端或命令提示符将其上传到 TensorBoard.dev:
tensorboard dev upload --logdir {logs}
请确保不要上传任何敏感数据!
使用 Google 帐户授权上传后,会获得一个代码。输入代码后,返回一个指向上传的 TensorBoard 日志的链接。
现在可以与任何人分享这个链接,让他们看到我们所做的工作。
使用 TensorBoard 的限制
尽管 TensorBoard 附带了许多用于可视化我们的数据和模型的工具,但它也有其局限性。
1、缺乏用户管理
TensorBoard 没有用户的概念,因为它在单一环境中工作。也不能在同一台机器上运行多个 TensorBoard 实例,因此如果我们同时处理多个项目,使用起来可能会很有挑战性。
2、难以在团队环境中使用
与上述限制类似,TensorBoard 实例不能在其他用户之间共享。如果有几个人在同一个项目上工作,需要一个集中的dashboard和每个人的单独工作区。TensorBoard 不支持此功能。
3、不支持数据和模型版本控制
在调整模型或设置超参数值时,我们需要保存不同的模型和训练数据版本。尤其是在进行实验时,希望同时查看不同版本的模型和数据。TensorBoard不能将某个运行或一组数据标记为特别重要。
4、执行大量运行时会出现问题
TensorBoard 并没有考虑到大量连续运行。如果继续运行模型并重复记录数据,将遇到 UI 问题,使界面难以使用。
5、不支持可视化视频文件和非结构化数据格式
某些数据类型无法在 TensorBoard 中可视化。特别是常用的视频数据。如果工作涉及对此类数据进行建模,则很难使用 TensorBoard。
总结
本文已经详细介绍了 TensorBoard,它是用于可视化机器学习模型的数据可视化工具包。本文介绍了TensorBoard所有基本组件以及新的实验性功能,例如假设工具和公平指标组件。借助这些功能,可以能够轻松查看和调试我们训练的模型的内部工作,并最终提高它们的性能。
https://www.overfit.cn/post/68f56127b3094cae88010203beba76d8
作者:Zito Relova

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 96
96 1
1- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)