
机器学习算法系列(十八)-随机森林算法(Random Forest Algorithm)
机器学习算法系列(十八)-随机森林算法(Random Forest Algorithm)
阅读本文需要的背景知识点:决策树学习算法、一丢丢编程知识
最近笔者做了一个基于人工智能实现音乐转谱和人声分离功能的在线应用——反谱(Serocs),感兴趣的读者欢迎试用与分享,感谢您的支持!serocs.cn
一、引言
前面一节我们学习了一种简单高效的算法——决策树学习算法(Decision Tree Learning Algorithm),下面来介绍一种基于决策树的集成学习1 算法——随机森林算法2(Random Forest Algorithm)。
二、模型介绍
有一个成语叫集思广益,指的是集中群众的智慧,广泛吸收有益的意见。在机器学习算法中也有类似的思想,被称为集成学习(Ensemble learning)。
集成学习
集成学习通过训练学习出多个估计器,当需要预测时通过结合器将多个估计器的结果整合起来当作最后的结果输出。
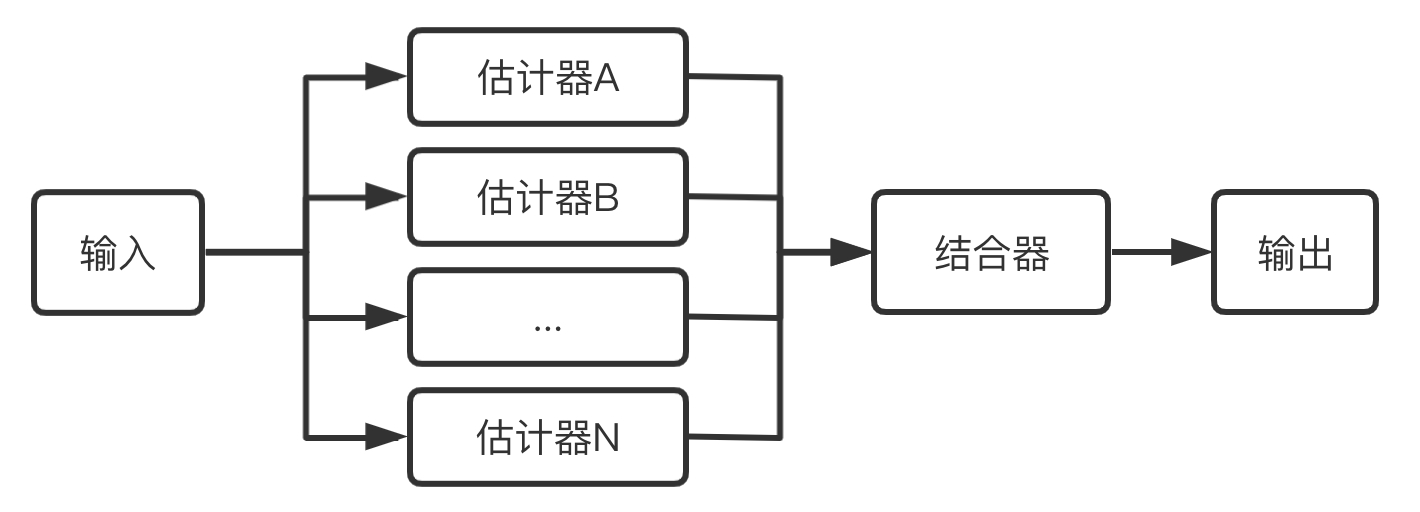
图2-1展示了集成学习的基本流程。
集成学习的优势是提升了单个估计器的通用性与鲁棒性,比单个估计器拥有更好的预测性能。集成学习的另一个特点是能方便的进行并行化操作。
Bagging算法
Bagging 算法3是一种集成学习算法,其全称为自助聚集算法(Bootstrap aggregating),顾名思义算法由 Bootstrap 与 Aggregating 两部分组成。
图 2-2 展示了Bagging 算法使用自助取样(Bootstrapping4)生成多个子数据的示例
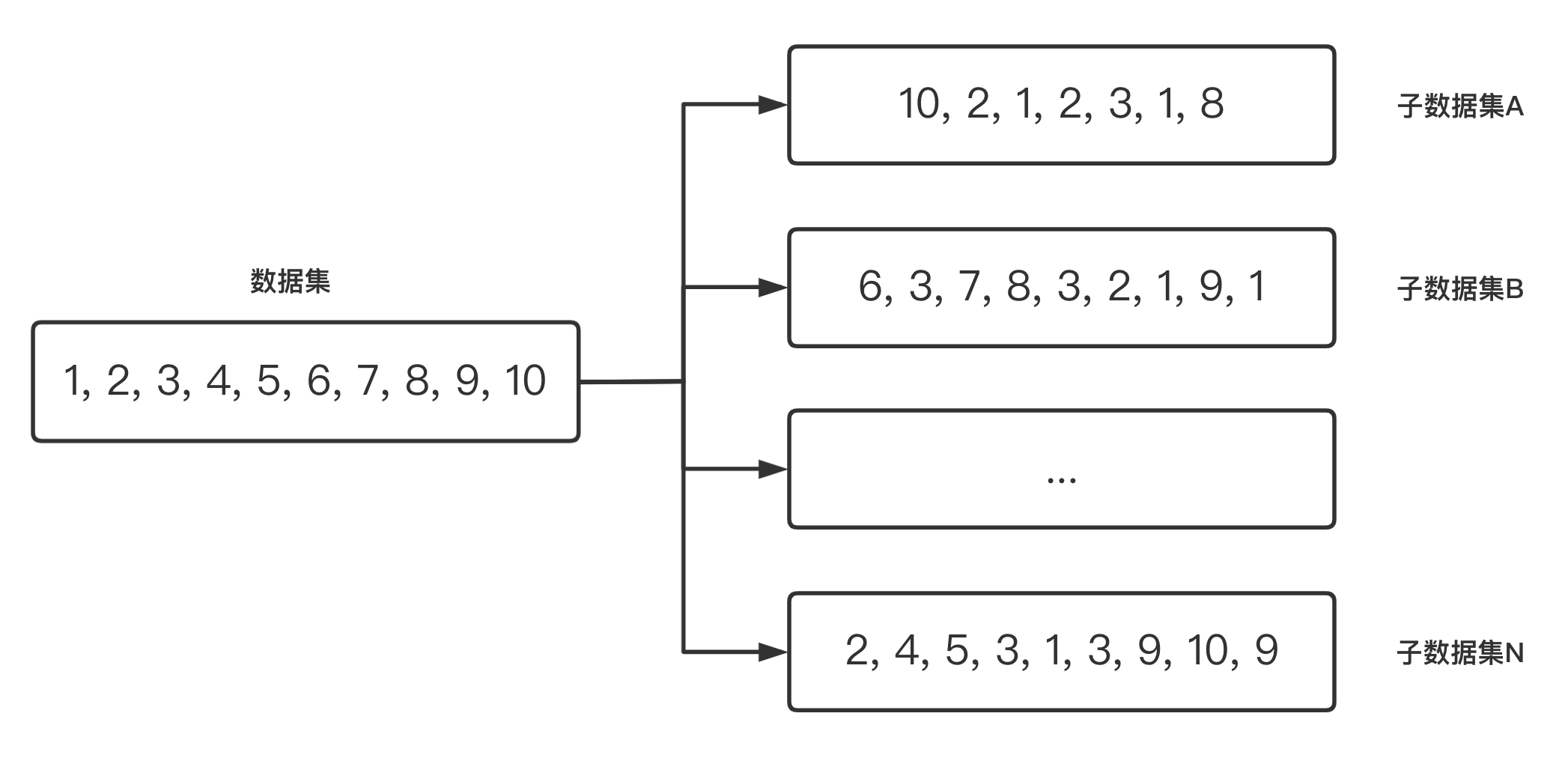
算法的具体步骤为:假设有一个大小为 N 的训练数据集,每次从该数据集中有放回的取选出大小为 M 的子数据集,一共选 K 次,根据这 K 个子数据集,训练学习出 K 个模型。当要预测的时候,使用这 K 个模型进行预测,再通过取平均值或者多数分类的方式,得到最后的预测结果。
随机森林算法
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。
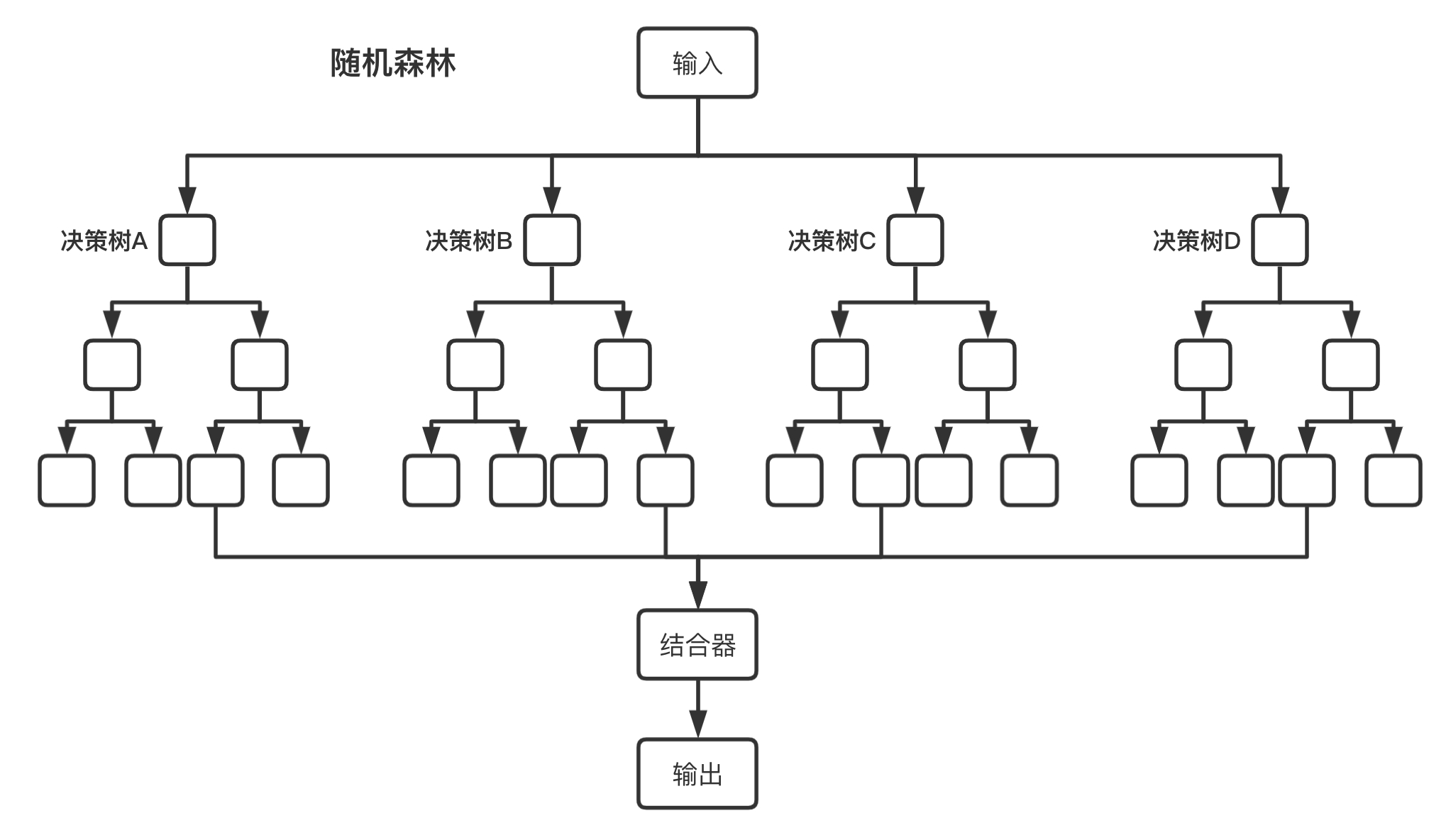
图2-3展示了随机森林算法的具体流程,其中结合器在分类问题中,选择多数分类结果作为最后的结果,在回归问题中,对多个回归结果取平均值作为最后的结果。
使用Bagging算法能降低过拟合的情况,从而带来了更好的性能。单个决策树对训练集的噪声非常敏感,但通过Bagging算法降低了训练出的多颗决策树之间关联性,有效缓解了上述问题。
三、算法步骤
假设训练集 T 的大小为 N ,特征数目为 M ,随机森林的大小为 K ,随机森林算法的具体步骤如下:
遍历随机森林的大小 K 次:
从训练集 T 中有放回抽样的方式,取样N 次形成一个新子训练集 D
随机选择 m 个特征,其中 m < M
使用新的训练集 D 和 m 个特征,学习出一个完整的决策树
得到随机森林
上面算法中 m 的选择:对于分类问题,可以在每次划分时使用 M \sqrt{M} M 个特征,对于回归问题, 选择 M 3 \frac{M}{3} 3M 但不少于 5 个特征。
四、优缺点
随机森林算法的优点:
- 对于很多种资料,可以产生高准确度的分类器
- 可以处理大量的输入变量
- 可以在决定类别时,评估变量的重要性
- 在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计
- 包含一个好方法可以估计丢失的资料,并且如果有很大一部分的资料丢失,仍可以维持准确度
- 对于不平衡的分类资料集来说,可以平衡误差
- 可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类,也可侦测偏离者和观看资料
- 学习过程很快速
随机森林算法的缺点:
- 牺牲了决策树的可解释性
- 在某些噪音较大的分类或回归问题上会过拟合
- 在多个分类变量的问题中,随机森林可能无法提高基学习器的准确性
五、代码实现
使用 Python 实现随机森林分类:
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class rfc:
"""
随机森林分类器
"""
def __init__(self, n_estimators = 100, random_state = 0):
# 随机森林的大小
self.n_estimators = n_estimators
# 随机森林的随机种子
self.random_state = random_state
def fit(self, X, y):
"""
随机森林分类器拟合
"""
self.y_classes = np.unique(y)
# 决策树数组
dts = []
n = X.shape[0]
rs = np.random.RandomState(self.random_state)
for i in range(self.n_estimators):
# 创建决策树分类器
dt = DecisionTreeClassifier(random_state=rs.randint(np.iinfo(np.int32).max), max_features = "auto")
# 根据随机生成的权重,拟合数据集
dt.fit(X, y, sample_weight=np.bincount(rs.randint(0, n, n), minlength = n))
dts.append(dt)
self.trees = dts
def predict(self, X):
"""
随机森林分类器预测
"""
# 预测结果数组
probas = np.zeros((X.shape[0], len(self.y_classes)))
for i in range(self.n_estimators):
# 决策树分类器
dt = self.trees[i]
# 依次预测结果可能性
probas += dt.predict_proba(X)
# 预测结果可能性取平均
probas /= self.n_estimators
# 返回预测结果
return self.y_classes.take(np.argmax(probas, axis = 1), axis = 0)
使用 Python 实现随机森林回归:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
class rfr:
"""
随机森林回归器
"""
def __init__(self, n_estimators = 100, random_state = 0):
# 随机森林的大小
self.n_estimators = n_estimators
# 随机森林的随机种子
self.random_state = random_state
def fit(self, X, y):
"""
随机森林回归器拟合
"""
# 决策树数组
dts = []
n = X.shape[0]
rs = np.random.RandomState(self.random_state)
for i in range(self.n_estimators):
# 创建决策树回归器
dt = DecisionTreeRegressor(random_state=rs.randint(np.iinfo(np.int32).max), max_features = "auto")
# 根据随机生成的权重,拟合数据集
dt.fit(X, y, sample_weight=np.bincount(rs.randint(0, n, n), minlength = n))
dts.append(dt)
self.trees = dts
def predict(self, X):
"""
随机森林回归器预测
"""
# 预测结果
ys = np.zeros(X.shape[0])
for i in range(self.n_estimators):
# 决策树回归器
dt = self.trees[i]
# 依次预测结果
ys += dt.predict(X)
# 预测结果取平均
ys /= self.n_estimators
return ys
六、第三方库实现
scikit-learn5 实现随机森林分类:
from sklearn.ensemble import RandomForestClassifier
# 随机森林分类器
clf = RandomForestClassifier(n_estimators = 100, random_state = 0)
# 拟合数据集
clf = clf.fit(X, y)
scikit-learn6 实现随机森林回归:
from sklearn.ensemble import RandomForestRegressor
# 随机森林回归器
clf = RandomForestRegressor(n_estimators = 100, random_state = 0)
# 拟合数据集
clf = clf.fit(X, y)
七、示例演示
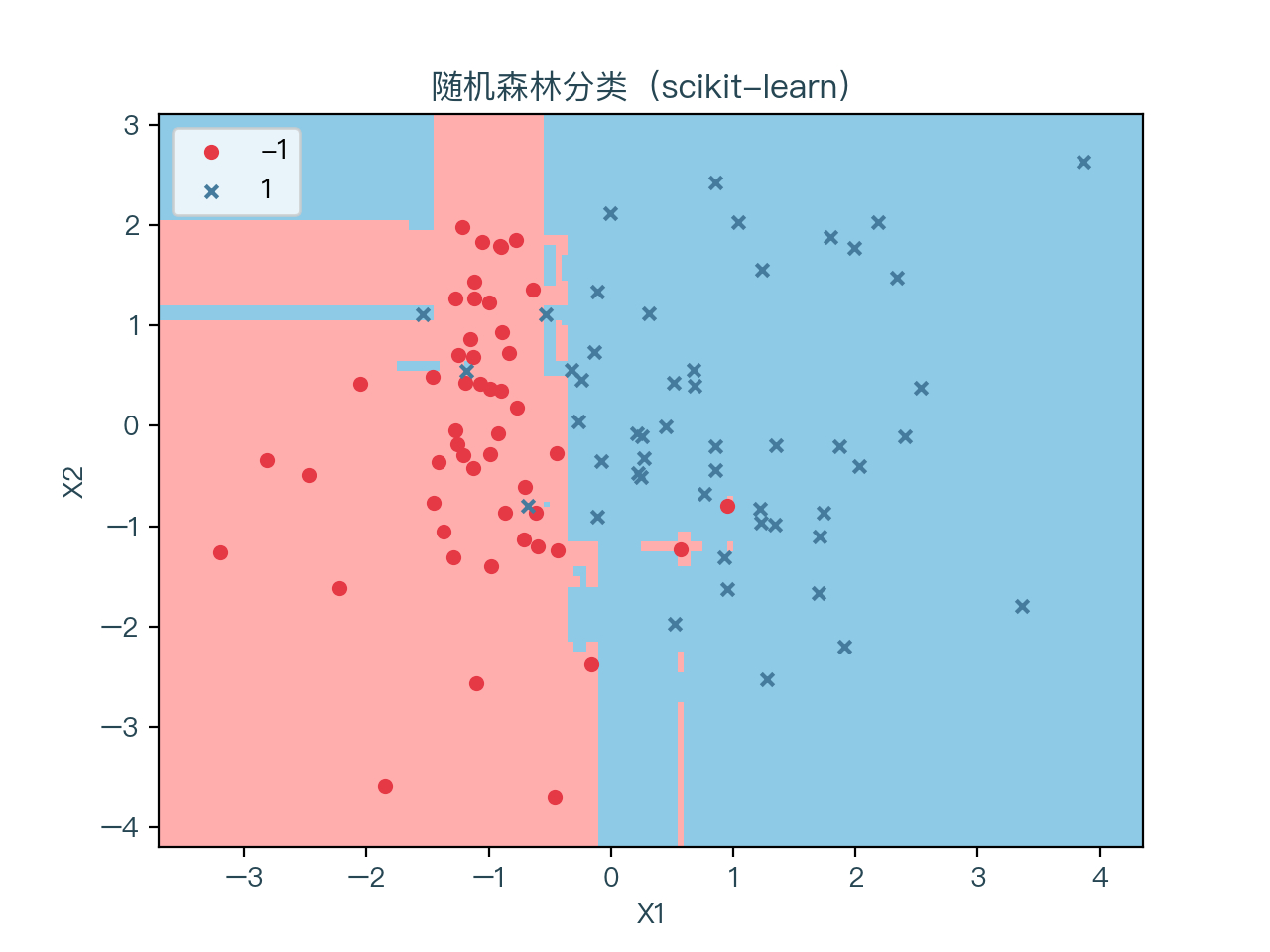
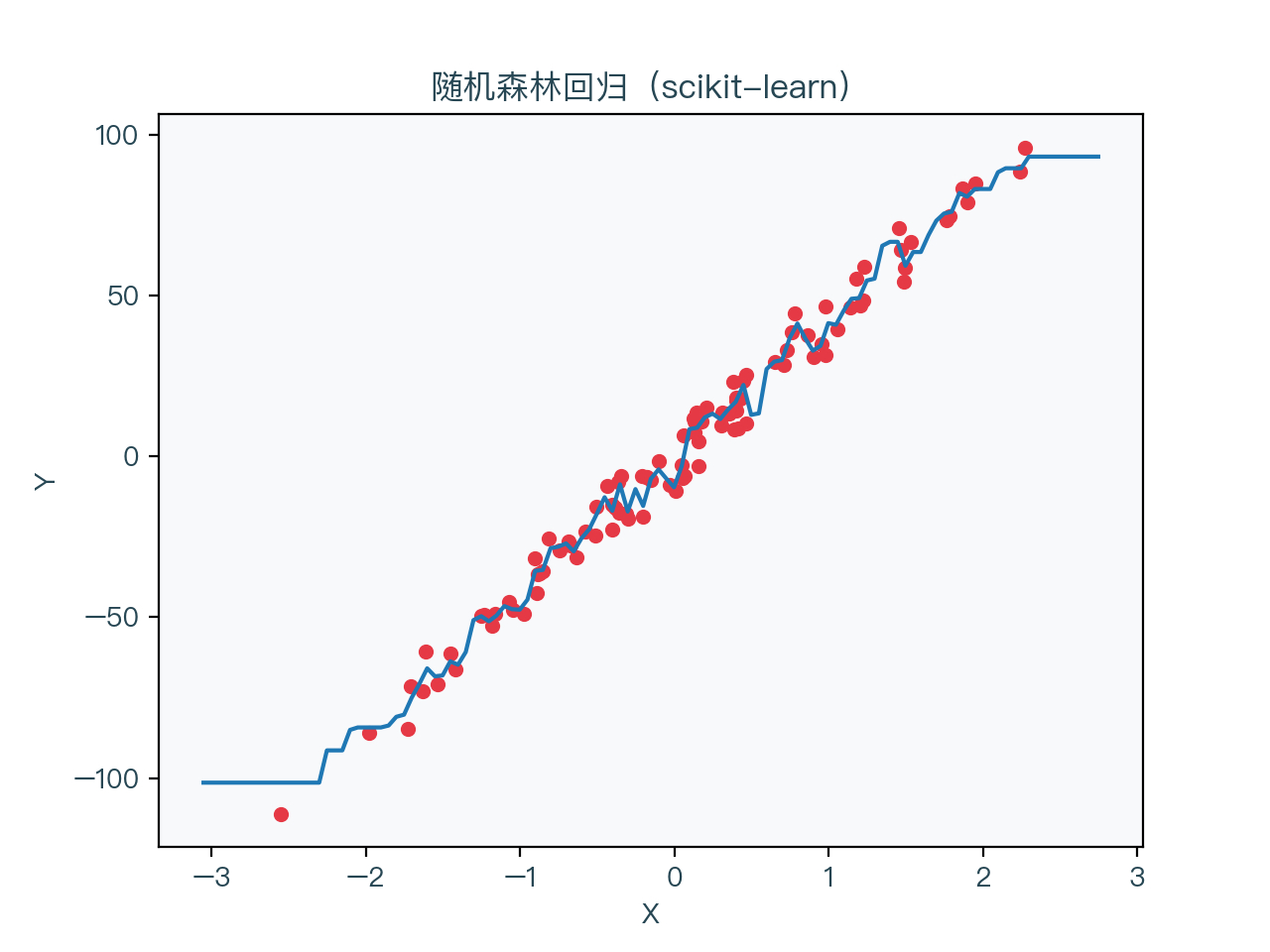
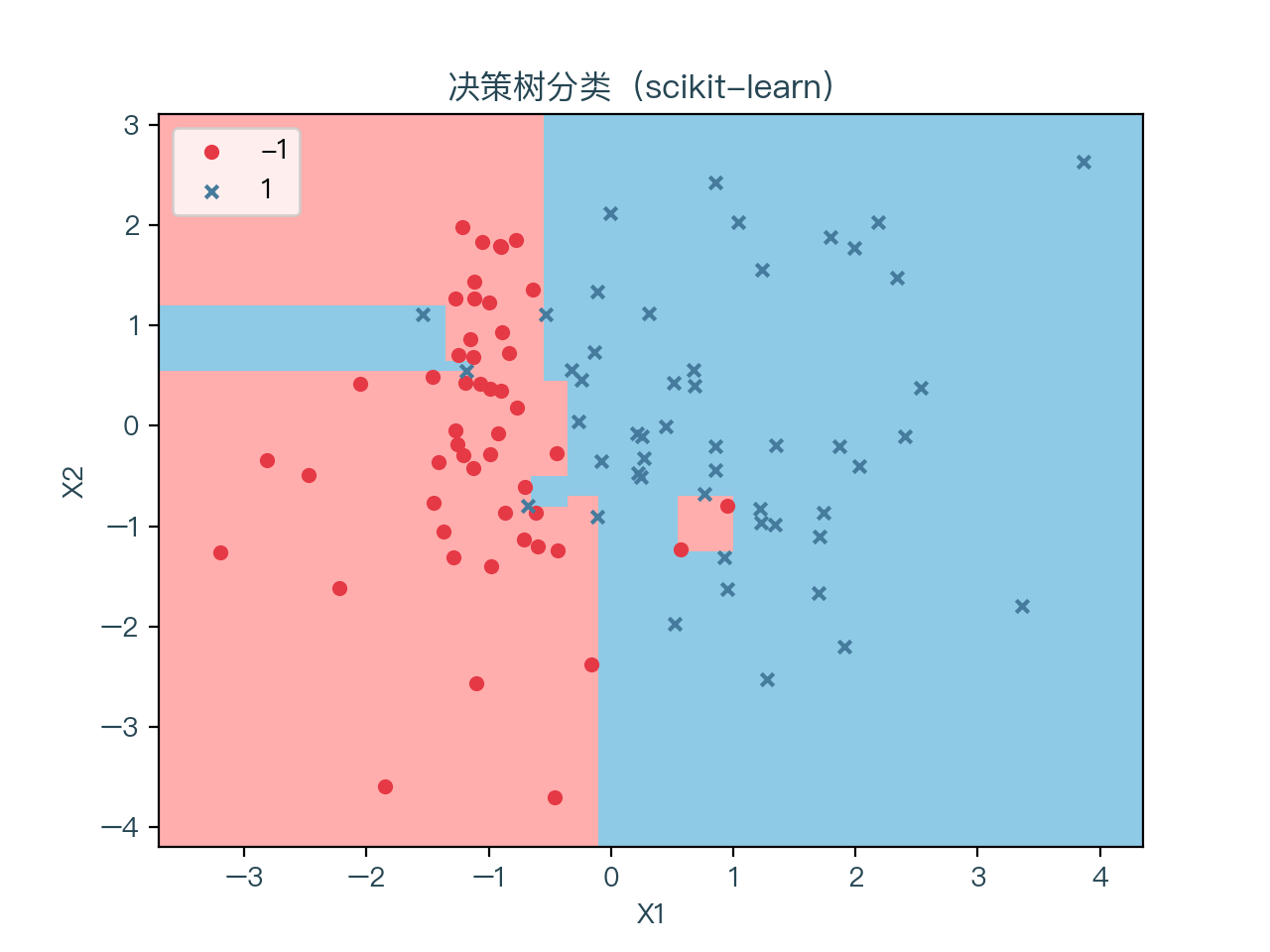
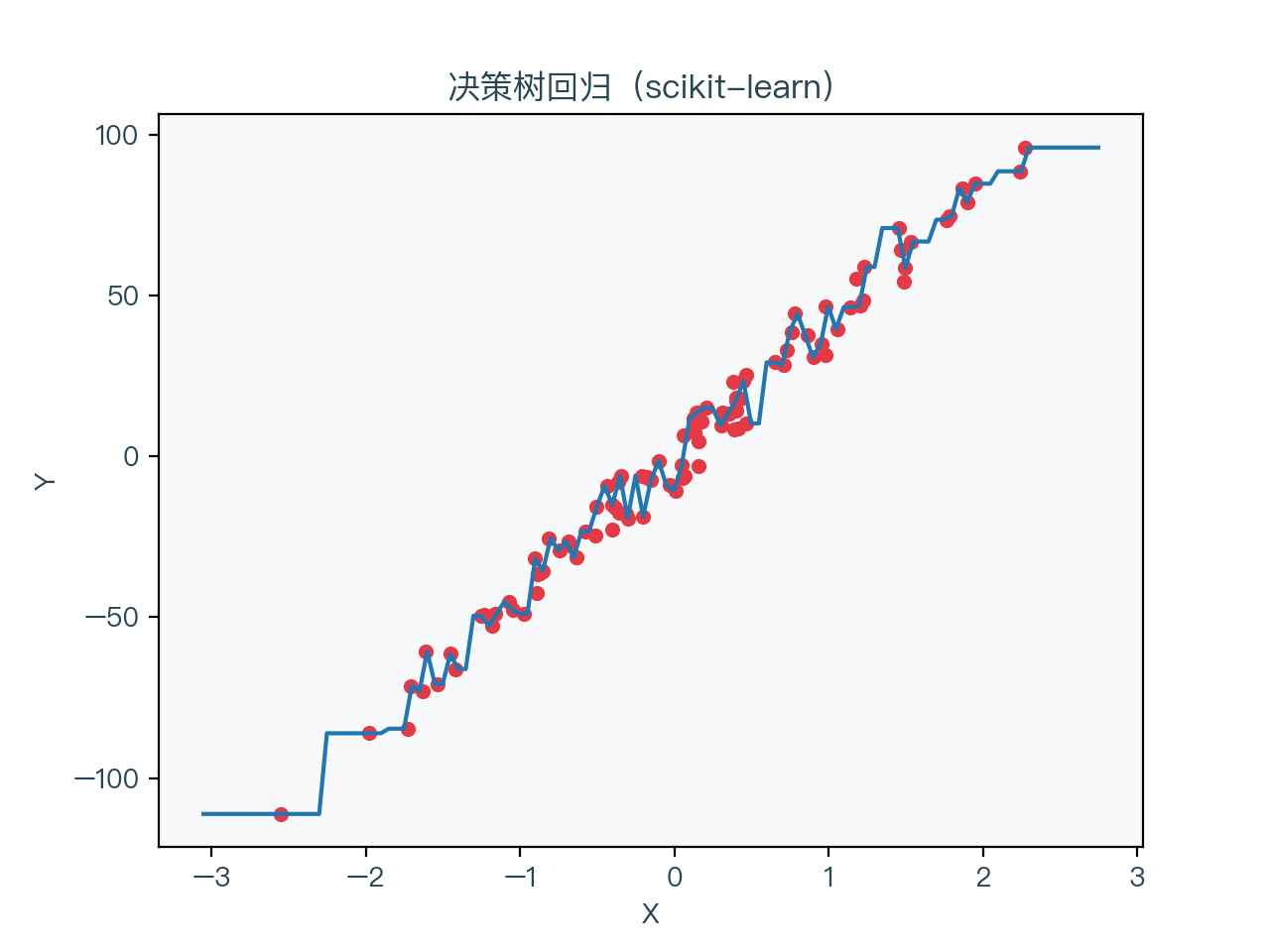
图7-1、图7-2 分别展示了使用随机森林算法进行分类与回归的结果,图7-3、图7-4 分别展示了上一节中使用决策学习算法进行分类与回归的结果。可以看到对比上一节中单独未正则化的决策树,其预测的结果相对更加平稳一些。
八、思维导图

九、参考文献
- https://en.wikipedia.org/wiki/Ensemble_learning
- https://en.wikipedia.org/wiki/Random_forest
- https://en.wikipedia.org/wiki/Bootstrap_aggregating
- https://en.wikipedia.org/wiki/Bootstrapping_(statistics)
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
最近笔者做了一个基于人工智能实现音乐转谱和人声分离功能的在线应用——反谱(Serocs),感兴趣的读者欢迎试用与分享,感谢您的支持!serocs.cn
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 293
293 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)