达摩院细粒度分类SoftTriple Loss ICCV高引论文深入解读
SoftTriple Loss论文是在图像细粒度分类领域提出了新型度量学习方法,该方法可以被广泛应用于各种搜索、识别等领域中,目前谷歌学术引用240+,相对高引。相比原始论文文档,本文将介绍更多研究过程中遇到的问题点以及相应创新方法的演进历史。
团队模型、论文、博文、直播合集,点击此处浏览
一、论文&代码
论文链接:SoftTriple Loss: Deep Metric Learning Without Triplet Sampling

开源代码:GitHub - idstcv/SoftTriple: PyTorch Implementation for SoftTriple Loss
二、背景
度量学习是一种机器学习方法,它主要用于在相似性度量的基础上进行数据挖掘。具体来说,度量学习通过学习一种函数来度量两个数据样本点的相似性。这种函数称为度量函数,它的目的是在尽可能减少度量错误的同时最小化相似数据样本点之间的距离。典型的度量学习方法包括Triplet Loss、ProxyNCA、Npairs等。度量学习可以应用于许多领域,例如:
1.)图像分类:度量学习可以用来帮助计算机识别图像中的物体。例如,通过学习数据集中的图像时,可以计算出两张图像之间的相似度,从而帮助计算机对新图像进行分类。例如,能够将图像分类到“狗”、“猫”或“其他”的类别中。度量学习在图像识别和分类中的应用非常广泛,且取得了很好的效果。
2.)文本分类:在文本领域,度量学习可以用来对文本进行分类,例如将文本分为正面或负面的情感,或者将它们分类到特定的主题中。假设我们有一组文档,每个文档都属于某一个类别,比如技术文章、新闻报道、娱乐新闻或体育新闻。我们可以训练一个模型,该模型能够将一篇新闻报道与一篇技术文章区分开来,并将它们分别分类到新闻报道或技术文章的类别中。
3.)语音识别:例如,我们可以使用度量学习来学习语音中的特征,并根据这些特征来识别说话人的语音内容。也可以训练一个模型,该模型能够识别一段语音是否是某个特定的人的声音。度量学习在语音识别领域的应用也非常广泛,且取得了很好的效果。
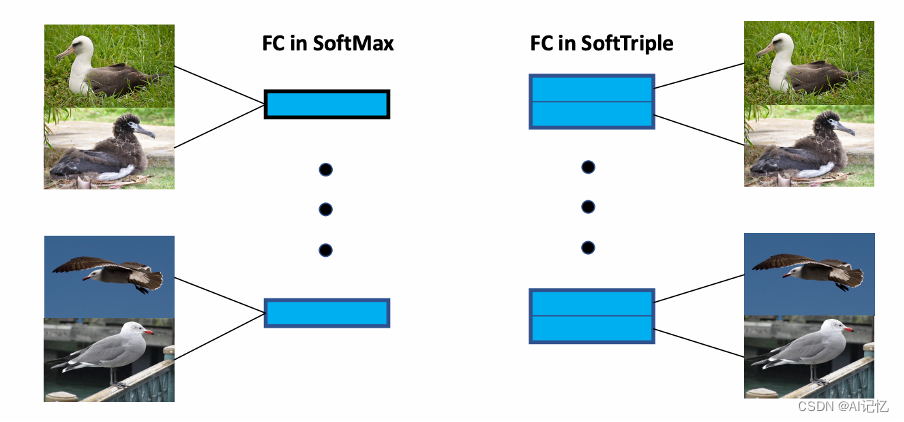
随着深度学习的兴起,度量学习也越来越多的跟深度学习网络得到的特征结合在了一起,本文结合深度学习框架,面向细粒度分类领域,提出了新型的SoftTriple Loss。如下简易示意图所示:

三、方法
该章节面向深度度量学习领域,选取了三类典型的Loss,做了相应的优缺点分析,最后引出本文SoftTriple方法及其创新演进历程解析。
方法1:triplet Loss分析

方法2:SoftMax Loss分析
论文对图像分类以及识别领域大为盛行且简单易用的SoftMax函数做了分析,通过巧妙的简单推导发现SoftMax函数其实就是等价于平滑(体现在每个类都有一个类中心,可理解为每个类共享一个中间proxy节点)的Triplet Loss函数,它的优点就是免triplet采样,一键batch化样本去训练。简易的推导示意如下图:

方法3:Cosine类Loss分析
通过将类中心W与样本特征X进行单位化后,度量学习领域也跟上了一系列引入W*X Cosine距离以及从各个角度加margin的loss论文,可谓风极一时。接下来我们来看下相应Cosine类loss的演进历程以及相应优缺点,如下图:

SoftTriple Loss演进历程解析
类内max相似度
基于上述的优缺点分析,本文的想法是如何通过类似SoftMax免采样的方式,实现可以克服类内样本差异较大的细粒度分类。由于以上的推导已经较为明显,本文的方法就是将SoftMax与Triplet进一步融合,示意图如下:

该初代版本的效果并不好,实现过程中出现了收敛性问题,因为初代版本样本与某个类的相似度是直接粗暴的取与样本特征相似度最大的那个中心来计算的。
类内ave相似度
接着又想到了加权平均的方法,示意图如下:

加权平均的方式是提高了收敛性,但是实验过程中同时发现类中心个数都很大的相应情况。
自适应类中心个数
紧接着通过加入正则的方式,对每个类的类中心个数做了相应的控制,具体过程与效果如下图所示:

四、结果
1. SOTA效果展示

2. SOTA量化对比

五、参考
[1] SoftTriple Loss: Deep Metric Learning Without Triplet Sampling_orangerfun的博客-CSDN博客_softtriple loss
六、应用
接下来给大家介绍下我们研发的各个域上的开源免费模型,欢迎大家体验、下载(大部分手机端即可体验):

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)