YARN原理及工作流程详解
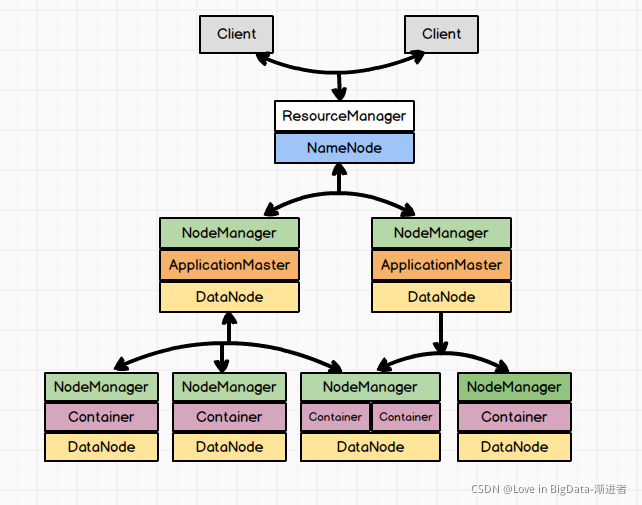
在集群部署方面,Yarn的各个组件是和Hadoop集群中的其他组件进行同一部署的在YARN框架中执行一个MapReduce程序时,从提交到完成需要经历如下8个步骤。①用户编写客户端应用程序, 向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动AlipplicationMaster的命令、用户程序等。②YARN 中的ReourceManager负责接收和处理来自客户端
在集群部署方面,Yarn的各个组件是和Hadoop集群中的其他组件进行同一部署的。如图:YARN的ResourceManager组件和HDFS的名称节点(NameNode)部署在一个节点上,YARN的ApplicationMaster及NameNode是和HDFS的和数据节点(DataNosde)部署在一起的。YARN中的容器(动态资源分配单位)代表了CPU、内存、磁盘、网络等计算资源,可限定每个应用程序使用的资源量。
了解yarn的工作流程,先了解一下yarn的组件吧~
简述哟:
| 组件 | 功能 |
|---|---|
| ResourceManager | 处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度 |
| ApplicationMaster | 为应用程序申请资源,并分配给内部任务、任务的调度,监控与容错 |
| NodeManager | 单个节点上的资源管理、处理ResourceManager的命令、处理来自ApplicationMaster的命令 |
详细解释(了解):
-
ResourceManager(RM):全局资源管理器,负责整个系统的资源管理和分配,两个主要组件:调度器Scheduler(S)和应用程序管理器Application Manager(ASM)
调度器:负责资源管理和分配。调度器接受ApplicationMaster测应用程序资源请求,并根据容量、队列等限制条件,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择。
应用程序管理器:负责所有应用程序的管理工作,包括:应用程序提交、与调度器协商资源以启动ApplicationMaster、负责跟踪和监控应用程序(ApplicationMaster)的运行状态并在失败时重新启动
RM接受用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户启动一个ApplicationMaster。 -
ApplicationMaster:(1)当用户作业提交时,ApplicationMaster与RM协商获取资源,RM会以容器的形式为ApplicationMaster分配资源.(2)把获取的资源进一步分配给内部的各个任务(Map 或Reduce),实现资源你的"二次分配";(3)与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务大声失败时执行失败恢复(重新申请资源重启任务);(4)定时向RM发送"心跳"消息,报告资源的使用情况和应用的进度信息;(5)当作业完成时,ApplicationMaster向RM注销容器,执行周期完成。
-
NodeManager:负责容器生命周期的管理,监控每个容器资源(CPU、内存)使用情况,跟踪节点健康状况,并以“心跳”方式与RM保持通信,向RM汇报作业的资源使用情况,和每个容器的运行状态,同时,他还要接受来自ApplicationMaster的启动/停止的各种请求,
说明:NodeManager主要负责管理抽象的容器,只处理与容器有关的事情,而不是具体负责每个任务(Map或Reduce)自身状态的管理,管理工作是由ApplicationMaster,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的运行状态。
工作流程:
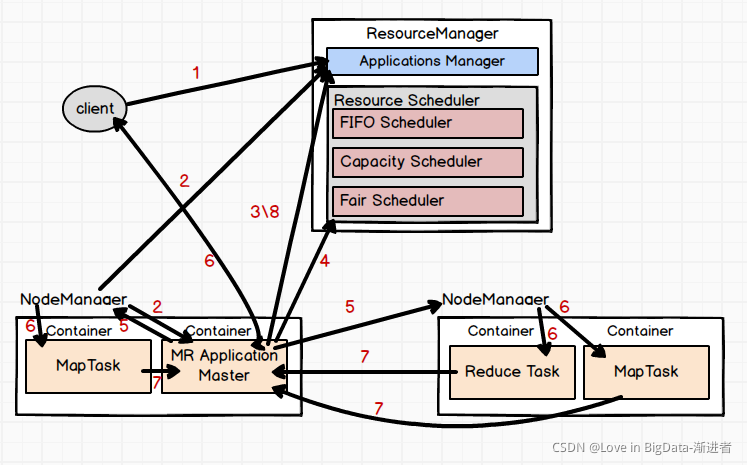
在YARN框架中执行一个MapReduce程序时,从提交到完成需要经历如下8个步骤。
①用户编写客户端应用程序, 向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
②YARN 中的ResourceManager负责接收和处理来自客户端的请求。接到客户端应用程序请求后,ResourceManager里面的调度器会为应用程序分配一个容器。同时, ResourceManager的应用程序管理器会与该容器所在NodeManager 通信,为该应用程序年该容器中启动一个ApplicationMaster。
③ApplicationMaster 被创建后会首先向ResourceManager 注册,从而使得用户可以通过ResourceManager来直接查看应用程序的运行状态。接下来的步骤4~7是具体的应用程序执行步骤。
④ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请资源。
⑤ResourceManager 以“容器”的形式向提出申请的ApplicationMaster 分配资源,一旦ApplicationMaster申请到资源后,就会与该容器所在的NodeManager 进行通信,要求它启动任务。
⑥当ApplicationMaster要求容器启动任务时,它会为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)然后将任务启动命令写到一个脚本中, 最后通过在容器中运行该脚本来启动任务。
⑦各个任各通过某个RPC 协议向Ap plicationMaster汇报自己的状态和进度,让ApplicationMaster可以随时掌握各 个任务的运行状态,从而可以在任务失败时重新启动任务。
⑧应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己,若ApplicationMaster因故失败,ResourceManager中的应用程序管理器会监测到失败的情形,然后将其重新启动,直到所有的任务执行完毕。
三种调度算法:
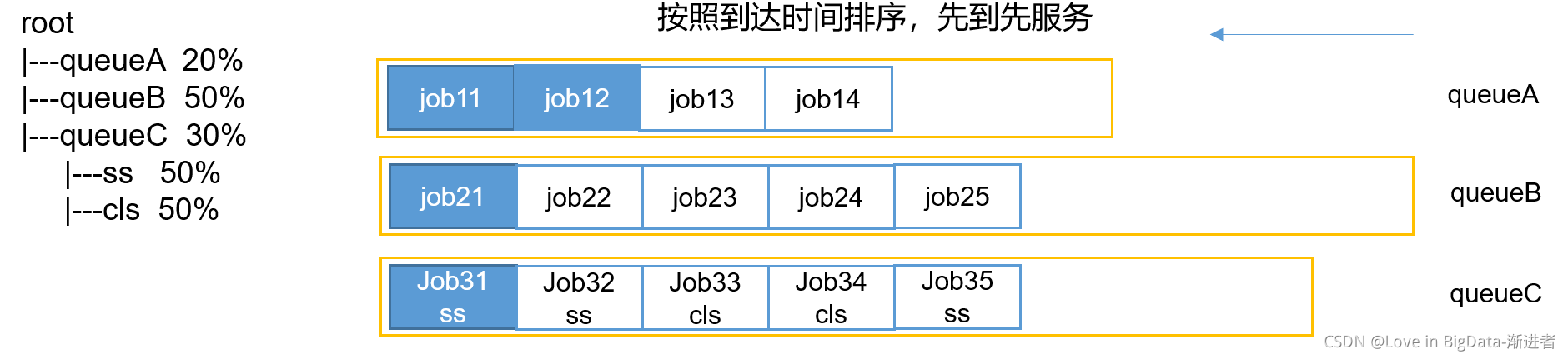
1、先进先出(FIFO Scheduler)
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
2、容量调度器(Capacity Scheduler)面试重点
Capacity Scheduler是Yahoo开发的多用户调度器。
特点:
(1)多队列:每个队列配置一定资源量,每个队列采用FIFO调度策略
(2)容量保证:管理员可为队列设置资源最低保证和资源使用上限
(3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
(4)多租户:支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
分配算法:
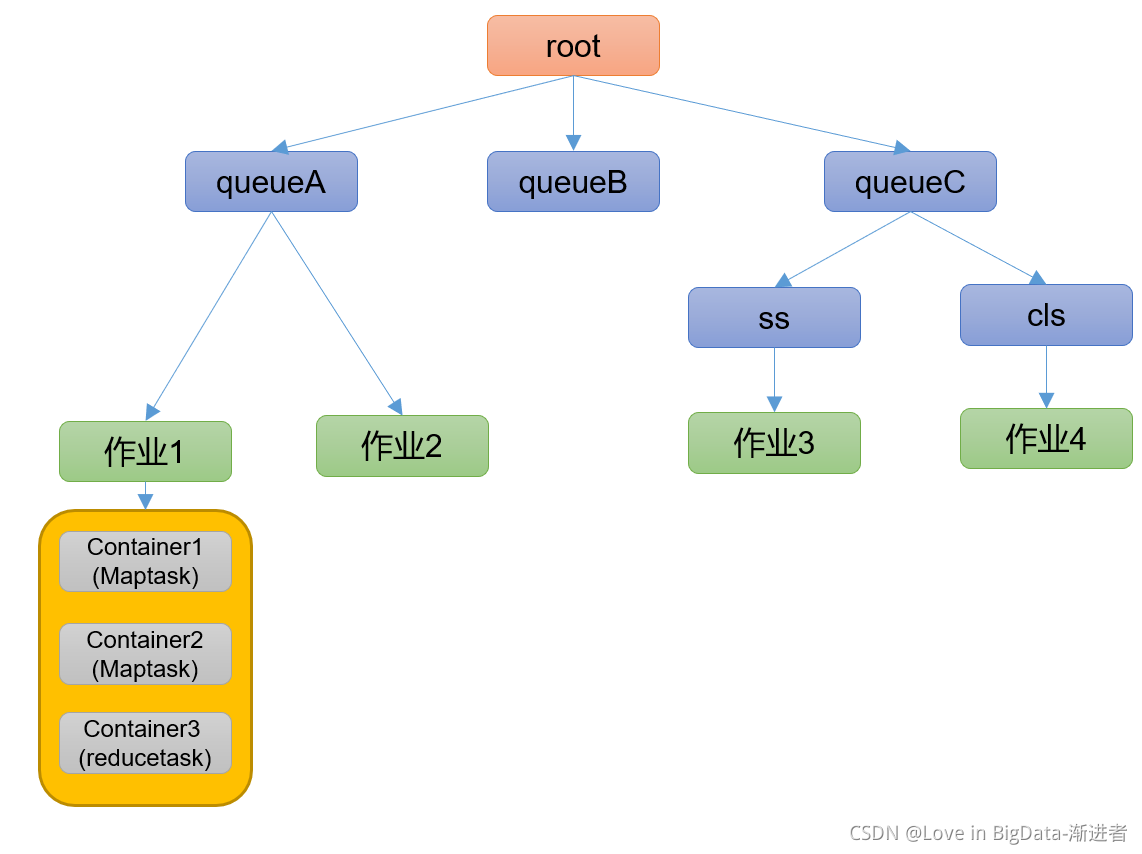
(1)队列资源分配
从root开始,使用深度优先算法,有限选择资源占用率最低的队列分配资源。
(2)作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源。
(3)容器资源分配
按照容器的优先级分配资源;
如果优先级相同,按照数据的本地性原则:
(1)任务和数据在同一节点
(2)任务和数据在同一机架
(3)任务和数据不在同一节点也不在同一机架
3、公平调度器(Fair Scheduler)
Fair Schedulere是Facebook开发的多用户调度器。
与容量调度器相同点:
(1)多队列:支持
(2)容量保证:管理员可为队列设置资源最低保证和资源使用上限
(3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
(4)多租户:支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点
(1)核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比较大的
(2)每个队列可以单独设置资源分配方式
容量调度器:FIFO、DRF
公平调度器:FIFO、FAIR、DRF
分配方式:
(1) FIFO策略:公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
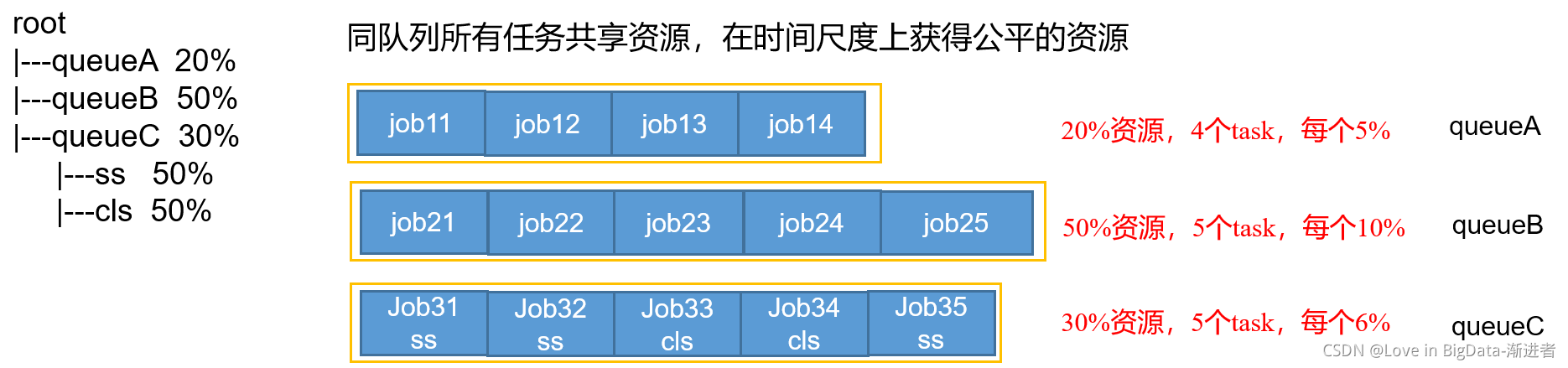
(2)Fair策略:公平的策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致;(1)选择队列 (2)选择作业 (3)选择容器。此三步,每一步都是按照公平策略分配资源
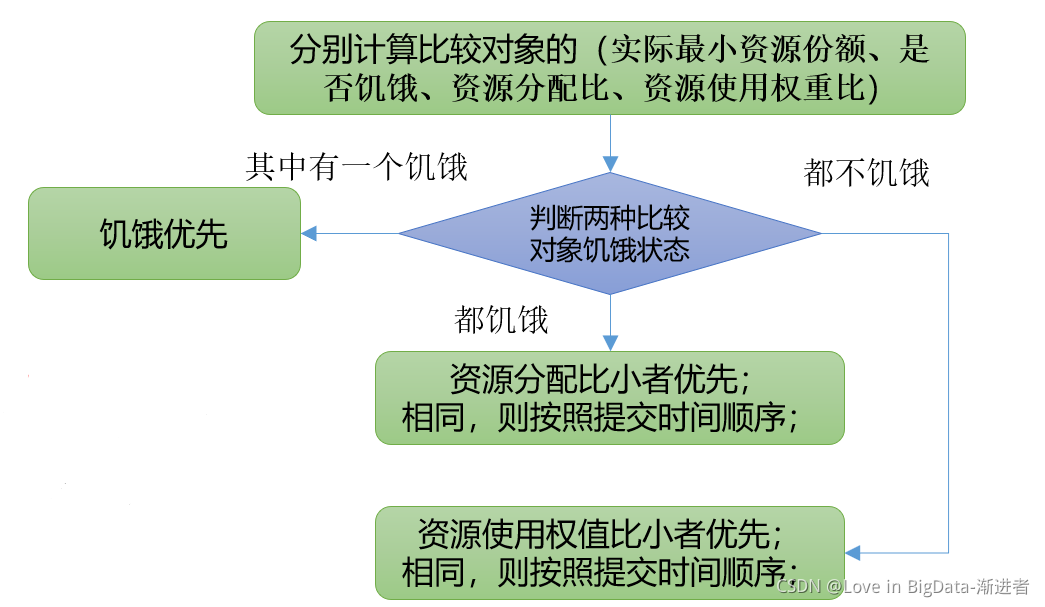
实际最小资源份额: mindshare = Min(资源需求量,配置的最小资源)
是否饥饿: isNeedy = 资源使用量 < mindshare(实际最小资源份额)
资源分配比: minShareRatio = 资源使用量 / Max (minshare,1)
资源使用权重比: useToWeightRatio = 资源使用量 / 权重
分配算法
(1)队列资源分配
总资源100,有三个队列,需求 队列A 20、队列B 50、队列C 30:
第一次算:100/3 = 33.33
队列A:分33.33 —>多13.33
队列B:分33.33 —>少16.67
队列C:分33.33 —>多3.33
第二次算:(13.33+3.33)/1 =16.66
队列A:分20
队列B:分33.33+16.66 = 50
队列C :分30
(2)作业资源分配
(a)不加权(重点是Job个数)
(b)加权(关注点是Job的权重)
和队列分配的分配方式一样,以此类推,不断计算只不过一个除以Job个数、一个除以Job的权重
DRF策略
DRF(Doninant Resouree Fairmess),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
DRF调度: 假设集群一共有100 CPU和10T内存,而应用A需要(2CPU,300GB),应用B需要(6 CPU,100GB )。则两个应用分别需要A(2%CPU,3%内存)和B(6%CPU,1%内存)的资源,这就意味着A是内存主导的,B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)