Java视频文件上传
最近在学习上传视频的时候发现阿里云有已经提供的一些接口,可以快速的帮助我们实现视频上传功能。但是文件上传的底层原理我们却不太清除,所以小编整理了一下通过分片上传、断点续传的方式实现上传视频的底层原理,帮助大家更好的理解上传视频功能。当我们上传一个非常巨大的视频时,发现总是上传失败,那是因为上传的视频文件大小过大,导致后台接受文件时出现异常,还有一种就是上传视频文件到一半的时候,关闭了上传功能,再次
最近在学习上传视频的时候发现阿里云有已经提供的一些接口,可以快速的帮助我们实现视频上传功能。但是文件上传的底层原理我们却不太清除,所以小编整理了一下通过分片上传、断点续传的方式实现上传视频的底层原理,帮助大家更好的理解上传视频功能。
分片上传+断点续传
当我们上传一个非常巨大的视频时,发现总是上传失败,那是因为上传的视频文件大小过大,导致后台接受文件时出现异常,还有一种就是上传视频文件到一半的时候,关闭了上传功能,再次上传时还要从头开始上传视频文件,那么这样就导致了用户使用不舒服的情况,所以接下来,小编将通过底层代码的方式,让大家更快了解分片上传功能。
文档:WebUploader API文档 - Web Uploader
说用:使用分片上传功能时,最主要的3个传入服务器的参数:单个分片数,总分片数,名称,通过这3样信息,可以实现分片上传,单点续传功能。
如果看完小编的情况还不是太清楚的话,可以去看上面的文档。
@Controller
public class UploadController {
private final static String utf8="utf-8";
@RequestMapping("/upload")
@ResponseBody
public void upload(HttpServletRequest request, HttpServletResponse response) throws UnsupportedEncodingException {
//分片
response.setCharacterEncoding(utf8);
Integer schunk =null;//当前分片数
//总分片数
Integer schunks=null;
//文件的名字
String name =null;
//文件的存储目录
String uploadPath="";
//文件流
BufferedOutputStream os =null;
try {
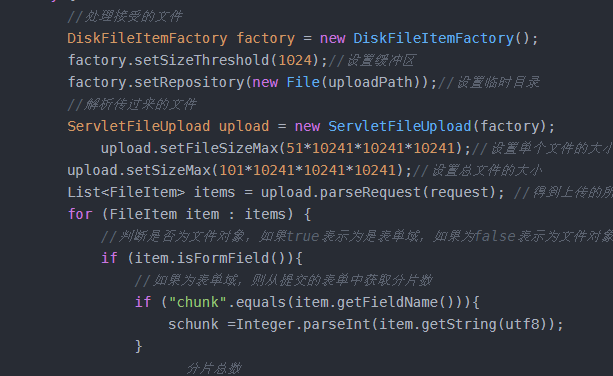
//处理接受的文件
DiskFileItemFactory factory = new DiskFileItemFactory();
factory.setSizeThreshold(1024);//设置缓冲区
factory.setRepository(new File(uploadPath));//设置临时目录
//解析传过来的文件
ServletFileUpload upload = new ServletFileUpload(factory);
upload.setFileSizeMax(51*10241*10241*10241);//设置单个文件的大小
upload.setSizeMax(101*10241*10241*10241);//设置总文件的大小
List<FileItem> items = upload.parseRequest(request); //得到上传的所有文件信息
for (FileItem item : items) {
//判断是否为文件对象,如果true表示为是表单域,如果为false表示为文件对象
if (item.isFormField()){
//如果为表单域,则从提交的表单中获取分片数
if ("chunk".equals(item.getFieldName())){
schunk =Integer.parseInt(item.getString(utf8));
}
// 分片总数
if ("chunks".equals(item.getFieldName())){
schunks =Integer.parseInt(item.getString(utf8));
}
// 名称
if ("name".equals(item.getFieldName())){
name =item.getString(utf8);
}
}
}
for (FileItem item : items) {
//判断是否为文件对象,如果true表示为是表单域,如果为false表示为文件对象
if (!item.isFormField()){
String temFileName=name;
if (name!=null){
if (schunk!=null){
temFileName= schunk+"_"+name;
}
// 传入文件
File temFile = new File(uploadPath, temFileName);
//断点续传
if (!temFile.exists()){
item.write(temFile);
}
}
}
}
//文件合并
//如果分片不等于null并且 总分片与最后一个分片相等,就证明所有分片成功
if (schunk!=null && schunk.intValue() == schunks-1){
File tempFile = new File(uploadPath,name);
os=new BufferedOutputStream(new FileOutputStream(tempFile));
for (int i=0 ;i<schunks;i++){
File file = new File(uploadPath,i+"_"+name);
while (file.exists()){
Thread.sleep(100);
}
//合并
byte[] bytes= FileUtils.readFileToByteArray(file);
os.write(bytes);
os.flush();
//临时文件删除
file.delete();
}
os.flush();
}
response.getWriter().write("上传成功");
} catch (FileUploadException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (os!=null){
//关闭流
os.close();
}
}catch (IOException e){
e.printStackTrace();
}
}
}
}总结:
以上就是代码的演示部分,总的来说就是,通过前端传过来的数据,获取到 单个分片数,总分片数,名称,这三个参数,然后自己创建一个文件解析工厂,设置单个文件的大小和总文件大小(这两个根据自己的需求来设置),然后获取传过来的每一个单个分片数,判断是否已经传过,如果传过那么就略过这个分片,继续执行没传过的分片,最后通过最后一个分片数和总分片数比较,如果他们两个相等那么就证明单个的分片数都传入完成,最后将所有的分片进行合并,在将这个分片删除即可。
最后,如果这篇博客对你有些许的帮助,记得为我点赞哦!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)