prometheus+grafana监控linux主机(快速入门)
普罗米修斯+grafana快速入门,搭建企业级监控平台。涉及promQL聚合查询、企业服务器重要监控指标。安全、运维、devops、自动化
目录
1. 安装node_export并制作systemd服务并启动
2. 登陆grafana后台http://192.168.6.109:3000添加datasource
前言:
普罗米修斯负责数据采集(可以同时采集一堆服务器的数据,且本身也自带数据展示功能)
grafana负责数据可视化(比普罗米修斯的更加美观且提供了很多很丰富的json模版,开箱即用)
本文章大体数据采集-->数据可视化 步骤:
1.部署node_export-->2.普罗米修斯本地采集数据-->3.数据grafana可视化
-
在第2步,需要学一下promQL聚合去获取指定的一些指标(比如linux的cpu、磁盘、内存、负载情况)还有一个阈值告警
-
正式环境上把普罗米修斯和grafana加入到本地k8s集群上
-
在本文章中,主要快速入门普罗米修斯和grafana的操作方法和promQL的简单查询
-
本文章中,普罗米修斯和grafana都用docker起
-
被监控主机:192.168.6.109 prometheus容器(192.168.6.109上运行): docker run -itd --name prometheus -p 9090:9090 prom/prometheus:v2.25.0 grafana容器(192.168.6.109上运行): docker run -itd --name grafana -p 3000:30000 grafana/grafana:7.3.7
操作步骤:
1. 安装node_export并制作systemd服务并启动
-
操作说明:普罗米修斯官方推荐使用这个作为节点指标采集的一个插件,node_export把数据丢给普罗米修斯的服务端
-
操作命令:
wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0-rc.0/node_exporter-1.4.0-rc.0.linux-amd64.tar.gz tar -xvf node_exporter-1.4.0-rc.0.linux-amd64.tar.gz -C /usr/local mv /usr/local/node_exporter-1.4.0-rc.0.linux-amd64/node_exporter /usr/local/bin/ # 编写systemd服务 cat > /etc/systemd/system/node_exporter.service <<EOF [Unit] Description=node_exporeter After=network.target [Service] Type=simple ExecStart=/usr/local/bin/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target EOF # 更新内核并启动,自启动 systemctl daemon-reload && systemctl start node_exporter && systemctl enable node_exporter && systemctl status node_exporter
2. 将node_export加入到普罗米修斯的配置文件中
-
操作说明:因为node_export的数据采集格式是和普罗米修斯一样的,所以普罗米修斯是可以读取到的,最后只需要将普罗米修斯和grafana绑定在一起即可
-
操作过程:
vi prometheus.yml - job_name: "linux" scrape_interval: 5s static_configs: - targets: ["192.168.6.109:9100"] # 重启容器 docker restart docker-apisix_prometheus_1
3. 监控本地重要指标
linux主要需要探测的指标有:cpu、disk磁盘、memory内存、upstream负载,需要通过promQL聚合查询
先登陆普罗米修斯web页面:
http://192.168.6.109:9090
1. cpu使用率
公式:cpu使用率=除空闲idle状态外的所有cpu状态总和除以总的cpu时间
promql语句:
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) ) * 100
2. 磁盘监控
主要关注根目录(ext4或xfs文件系统)的磁盘利用率
promql语句:
(1 - node_filesystem_avail_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} ) * 100
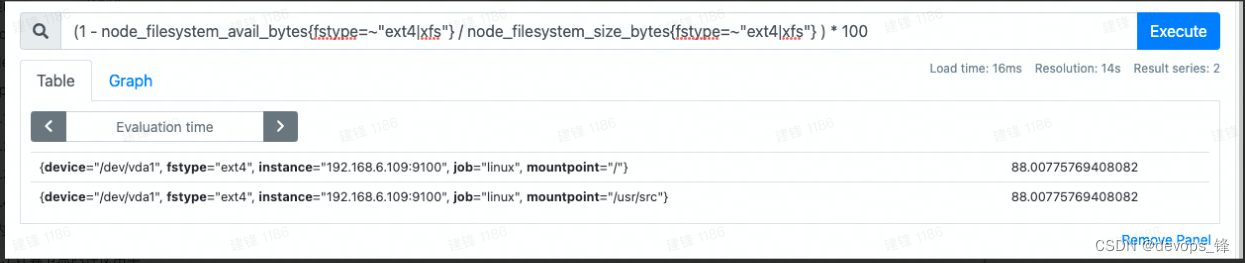
3. 内存监控
主要关注内存使用率:free或available这两列重点关注
free:显示还有多少物理内存和交换空间可用
available:显示还可以被应用程序使用的物理内存大小
节点内存使用率promql语句:
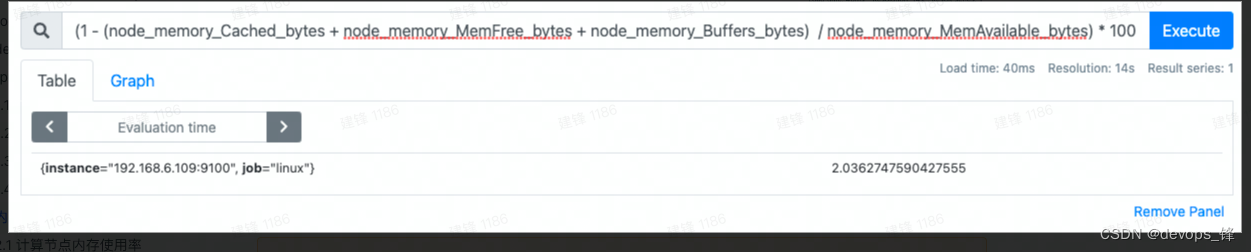
(1 - (node_memory_Cached_bytes + node_memory_MemFree_bytes + node_memory_Buffers_bytes) / node_memory_MemAvailable_bytes) * 100
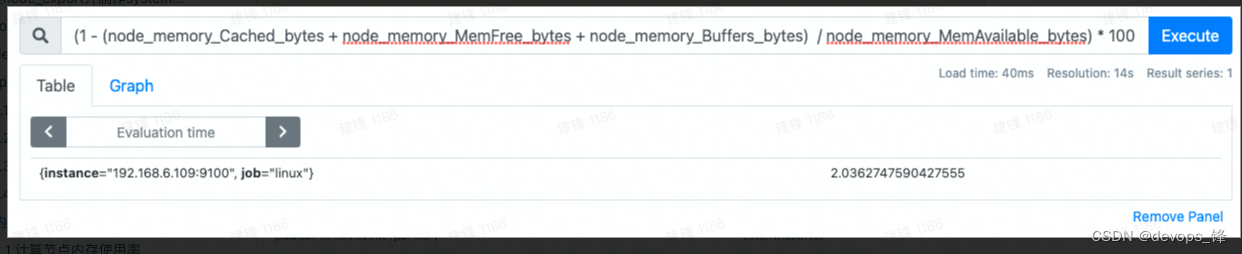
4. grafana数据统一可视化
普罗米修斯也可以可视化,但是他每一个指标都是单独的,而grafana是可以将普罗米修斯收集到的数据统一合并到一个美观的web图表上
1. 下载热门json模块,id:8919
https://grafana.com/api/dashboards/12633/revisions/1/download 下载链接
2. 登陆grafana后台http://192.168.6.109:3000添加datasource
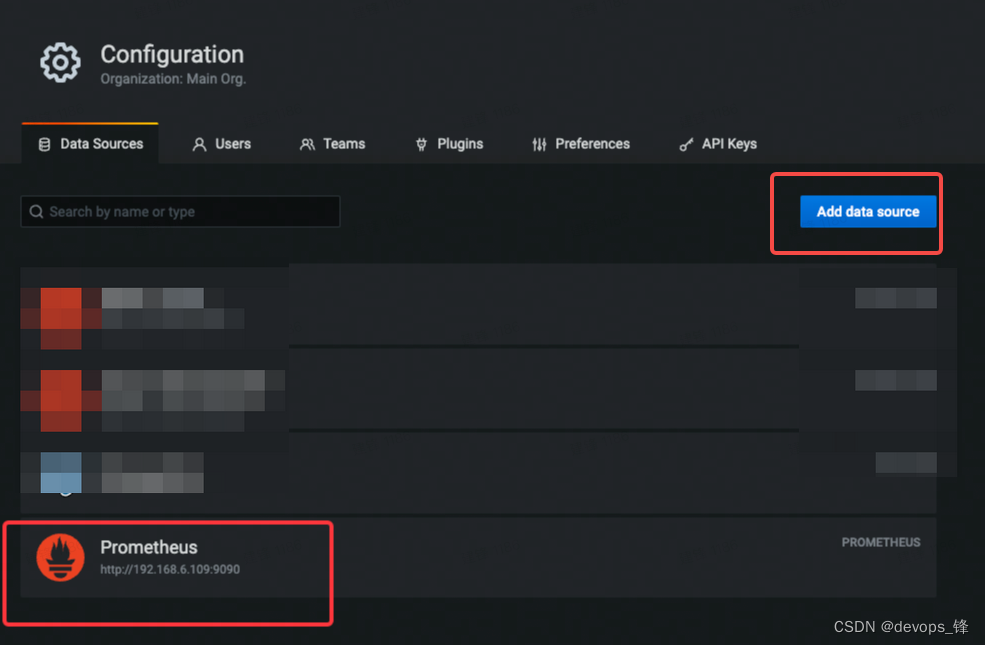
3. 导入json模块并指定普罗米修斯数据源
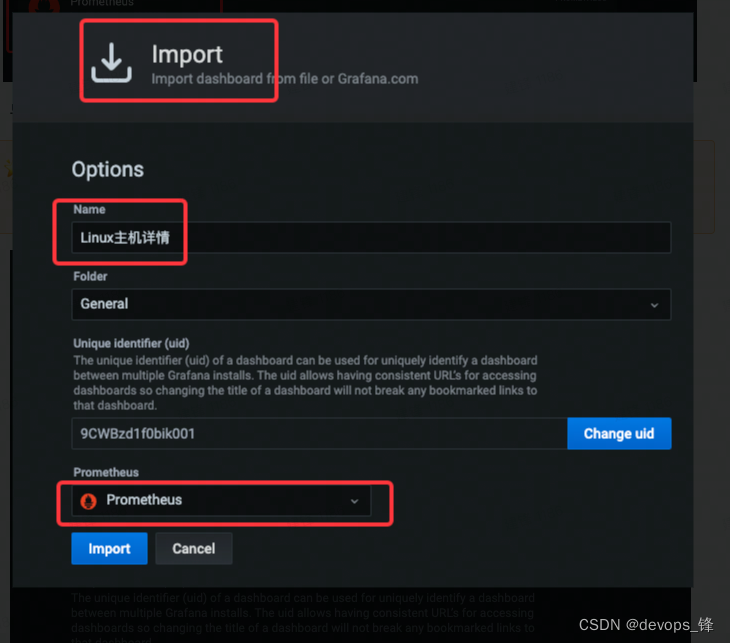
4. 最终结果展示数据
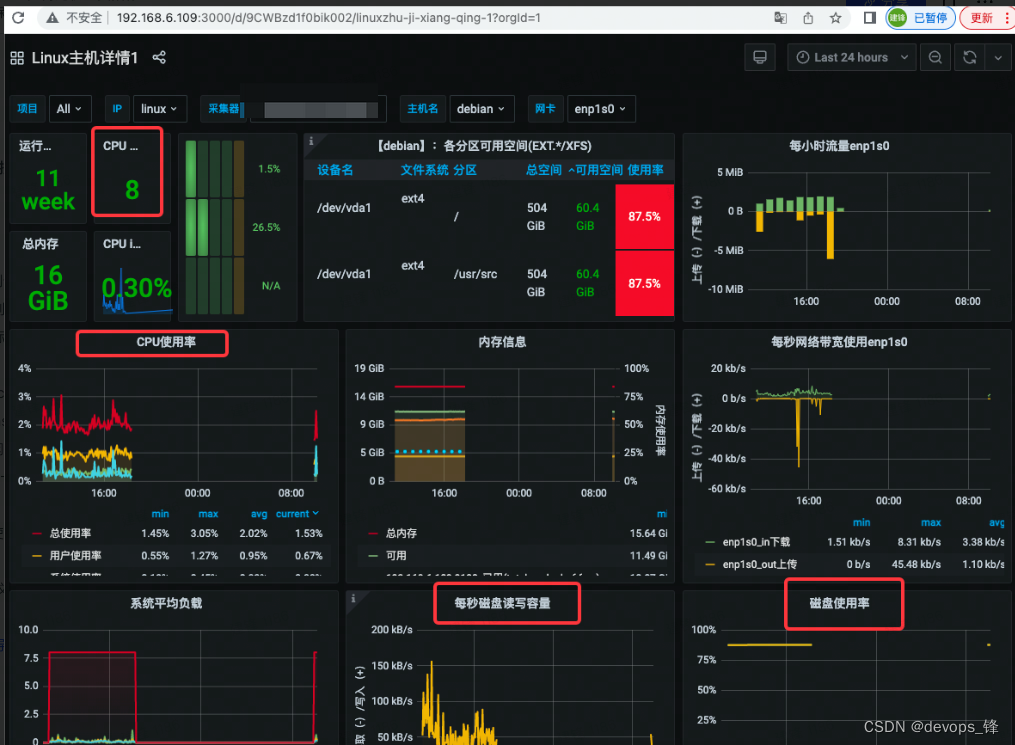
作者:devops_锋
邮箱:1195494025@qq.com (有问题可邮箱发送)
后续:后期会出一期阿里云上sae部署相关服务,且日志收集,监控的相关的文章。尽情期待吧。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)