分布式事务以及seata介绍
一、单机事务二、什么是分布式事务三、分布式事务解决方案四、分布式事务解决方案seata学习五、seata源码学习
一、事务
1.事务定义
指的就是一个操作单元,在这个操作单元中的所有操作最终要保持一致的行为,要么所有操作都成功,要么所有的操作都被撤销。
2.事务的四个特性 - ACID
A:atomicity 原子性
事务中包含的各项操作在一次执行过程中,只允许出现以下两种状态之一:要么全做,要么不做,没有中间状态。
C:consistency 一致性
在事务开始和完成时,数据库的数据都保持一致的状态,即事务的执行使数据库从一种正确状态转到另一种正确状态。能量守恒,总量不变
I:isolation 隔离性
在并发环境中,一个事务的执行不能被其他事务干扰。也就是说,不同的事务并发操作相同的数据时,每个事务都有各自完整的数据空间。信息彼此独立,互不干扰
D:durability 持久性
一旦事务提交,那么它对数据库中的数据的改变就是永久性的,并不会被回滚。即使服务器系统崩溃或服务器宕机等故障。只要数据库重新启动,那么一定能够将其恢复到事务成功结束后的状态。
3.本地事务实现
begin/start transaction;
//1.本地数据库操作:生成订单
//2.本地数据库操作:减少库存
commit transation;二、什么是分布式事务
1.分布式事务定义
在分布式环境下由不同的服务之间通过网络远程协作完成事务称为分布式事务
随着互联网快速发展,软件系统由原来的单体应用转变为分布式应用,分布式系统把一个应用系统拆分为可独立部署的多个服务,需要服务与服务之间远程协作才能完成事务
2.传统数据库事务应对解决分布式事务
#传统事务实现:
begin/start transaction;
//1.本地数据库操作:生成订单
//2.远程调用:减少库存
commit transation;步骤2远程调成功,但网络问题造成超时没有返回,导致本地事务回滚,造成数据不一致。在分布式架构基础上,传统数据库事务无法使用。
3.分布式事务场景
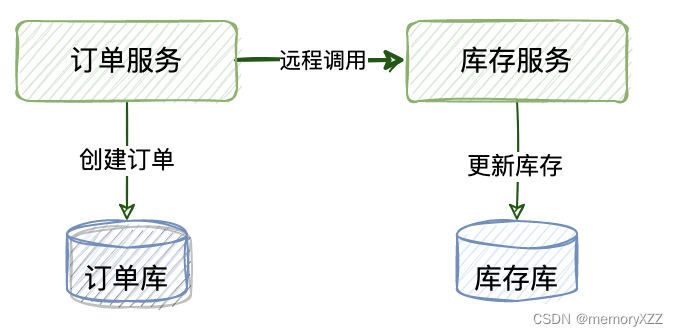
a.跨JVM进程产生分布式事务
典型场景是微服务之间通过远程调用完成事务
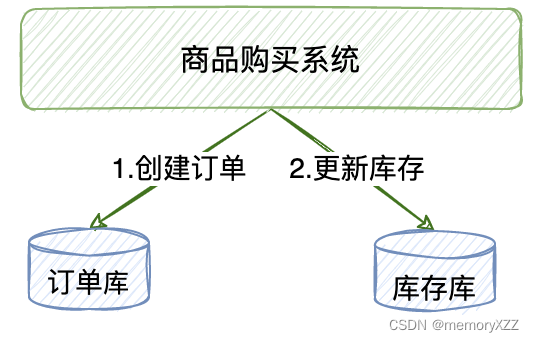
b.跨数据库实例
单体系统访问多个数据库实例。当单体系统访问多个数据库(实例)时会产生分布式事务
三、分布式事务解决方案
3.1分布式事务理论之CAP、BASE
1、 CAP理论
在分布式系统中不可能同时满足:一致性、可用性、分区容错性。
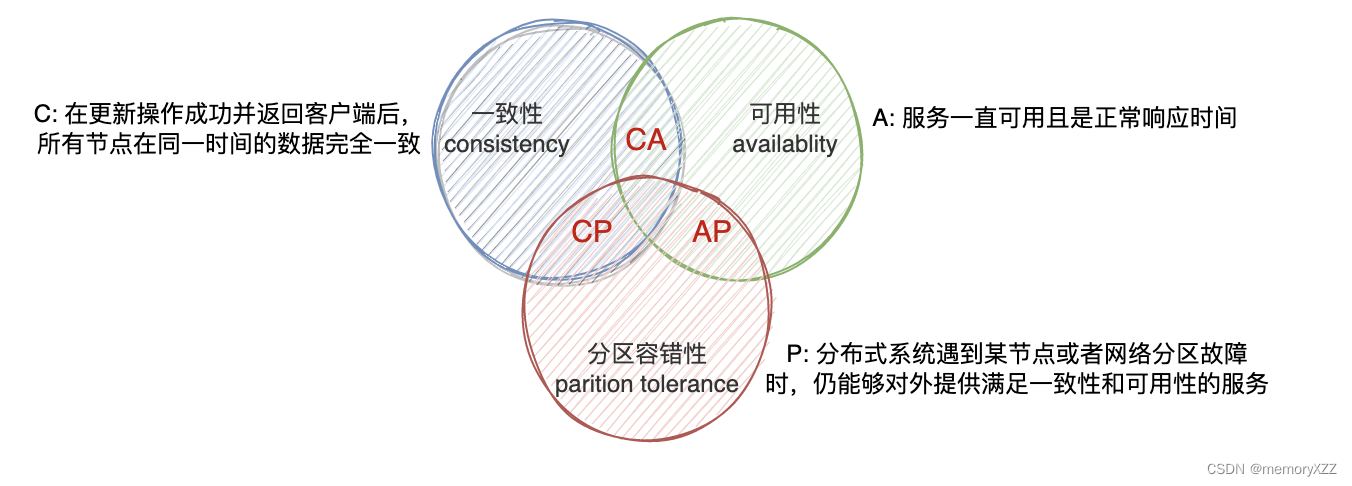
分布式系统无法同时满足以上三点,必须要做取舍,而分区容错性P是最基本的要求。因为分布式系统部署在不用的节点,而子网络必定会出现异常情况,因此分区容错性是分布式系统必须要解决的问题。
CP:实现一致性与分区容错性。数据强一致模型,弱化了可用性,性能偏低。
- 使用场景:对数据要求比较高的场景使用此模式,如金融业务等。
- 方案:XA两阶段提交、Seata AT模式的”读已提交“级别等。
AP:实现可用性和分区容错性,最终一致性模式,弱化了一致性。性能高,满足高并发业务需求
- 使用场景:互联网分布式服务多基于AP。
- 方案:TCC、基于消息的最终一致性、saga等
2、BASE理论
BA:基本可用basically available
- 对可用性A的妥协,即在分布式系统出现不可预知故障时,允许损失部分可用性。如在秒杀场景+雪崩的业务场景下进行降级处理,使核心功能可用,而不是所有功能可用
S: 软状态soft state
- 允许系统存在中间态,并认为该状态不会影响系统的整体可用性。允许系统在多个不同节点的数据副本存在数据延时。
E:最终一致性 eventyally consistency
- 同一数据的不同副本状态可以不要求实时一致,但经过一定的时间后一定是一致的
BASE理论是对CAP的一致性和可用性权衡的结果。核心思想:我们无法做到强一致,但每个应用可以根据自身的特定,采用适当的方式使系统达到最终一致性。
3.2 分布式事务协议
1、DB层面 -XA协议(两阶段提交、三阶段提交)
XA协议:基于分布式事务协议,主要由事务管理器和本地资源管理器组成,事务管理器是一个全局调度者,负责本地资源管理器统一的提交或回滚事务。mysql、oracle均已支持XA协议。XA模式是传统的分布式强一致性解决方案,性能较低,实际业务中使用较少。
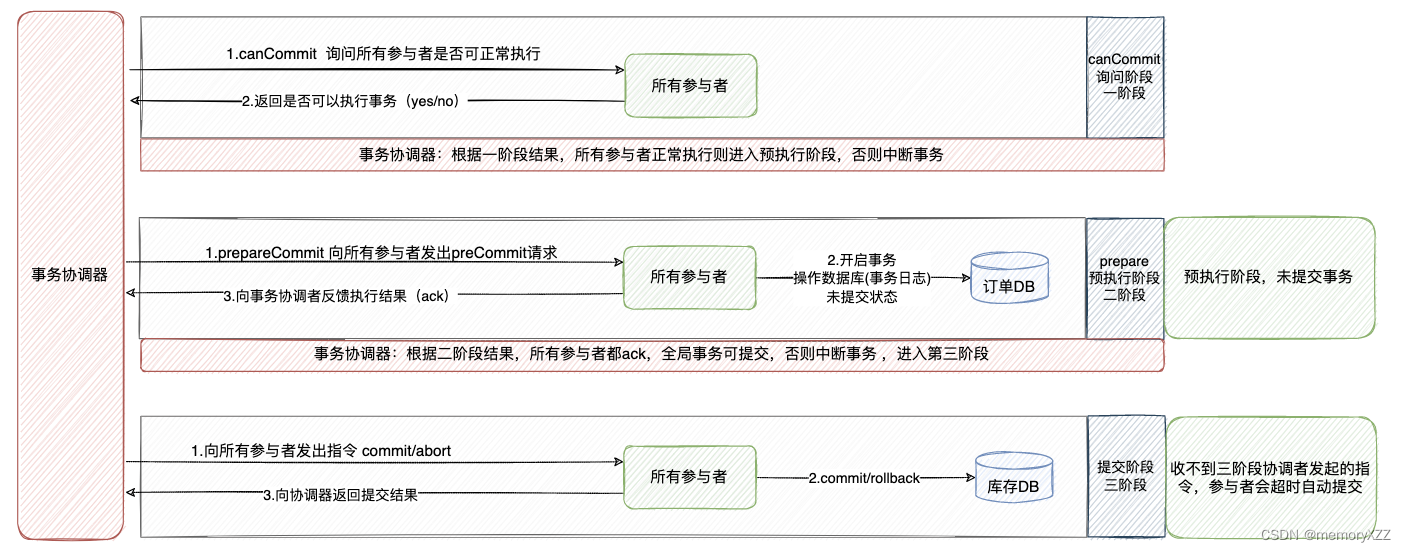
2PC - 二阶段提交协议
1、准备阶段
- 事务协调者,向所有事务参与者发送事务内容,询问是否可以提交事务,并等待参与者回复。
- 事务参与者收到事务内容,开始执行事务操作但不提交(将 undo 和 redo 信息记入事务日志中(但此时并不提交事务))
- 参与者将执行结果反馈给协调者,同时阻塞等待协调者后续的指令
2、提交阶段
- 协调器根据一阶段执行结果确定分布式事务提交 or 回滚。()所有的参与者都执行成功才能commit,否则rollback)
- 参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源并将二阶段阶段反馈给协调者。

- 优点:尽量保证了数据的强一致性,适用对数据强一致性要求很高的场景
- 缺点:实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景
二阶段提交的缺点:
- 同步阻塞问题。执行过程中,所有的参与者都是事务阻塞型,当参与者占有公共资源时,其他第三方节点访问公共资源时会被阻塞
- 可靠性问题。二阶段事务协调者发生故障时,参与者会一直处于事务资源锁定的状态,一直阻塞下去,需要额外的备机进行容错
- 事务状态不确定问题。二阶段协调者发出commit消息后宕机,唯一收到这条消息的参与者也宕机了。那么及时通过选举产生新的协调者,这条事务的状态也是不确定的。
3PC - 三阶段提交
比2PC增加了以下两点:
- 在协调者和参与者中都增加了超时机制
- 一二阶段之间增加了准备阶段,保证了在最后阶段提交前所有参与者的状态是一致的。
 缺点:
缺点:
- 同步阻塞问题。仍有
- 数据不一致问题,协调者发出rollback请求,但因为网络问题,参与者收不到rollback请求,导致参与者超时提交,造成数据不一致。
2、服务层面 分布式事务解决方案
- TCC
- 基于消息的最终一致性
- saga
TCC
try-confirm-cancel 应用层面侵入业务的两阶段提交。 核心思想:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
try-confirm-cancel 类比于XA两阶段协议中的prepare、commit、rollback。TCC是由业务开发者实现,XA是数据库自动完成对资源的操作。
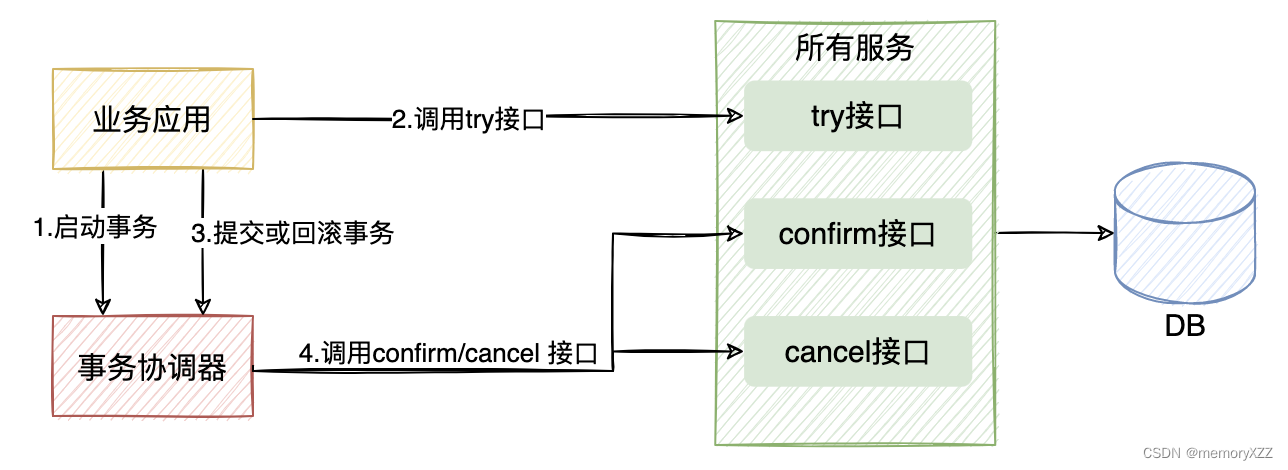 TCC让应用自己定义锁的粒度,使锁冲突概率降低。
TCC让应用自己定义锁的粒度,使锁冲突概率降低。
缺点:
- 对应用的侵入性强。业务逻辑的每个分支都需要实现 try、confirm、cancel这三个操作,改造成本大。
- 实现难度大。需要根据不同的失败的失败原因(系统故障、网络原因等),实现不同的回滚策略。为了满足一致性,confirm、cancel接口必须实现幂等性。
基于消息的最终一致性
核心思想:将分布式事务转换成两个本地事务,依靠下游业务的重试机制达到最终一致性。主要流程如下图所示
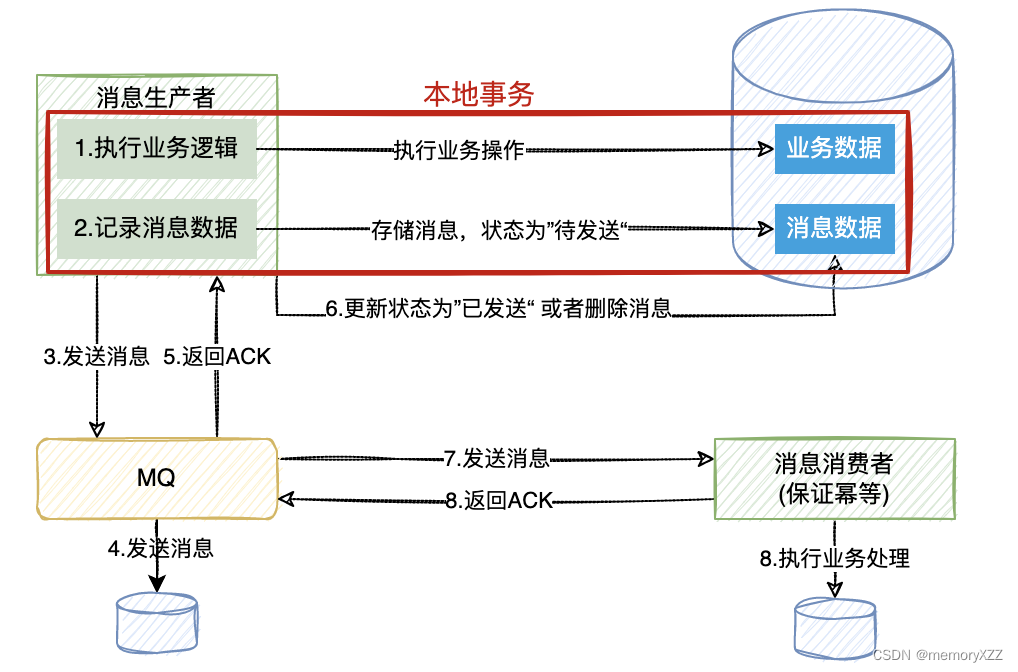
优点:
- 从应用设计开发的角度实现了消息的可靠性,消息数据的可靠性不依赖于消息中间件,弱化了对消息中间件的依赖
- 方案轻量,容易实现
缺点:
- 对应用的侵入性强,耦合性强,需要进行大量的业务改造。
Saga协议
事务协议如下
- 每个事务由一系列幂等的有序子事务Ti(sub-transaction)组成
- 、每个Ti都有对应的幂等补偿操作Ci,补偿动作用于撤销Ti造成的结果
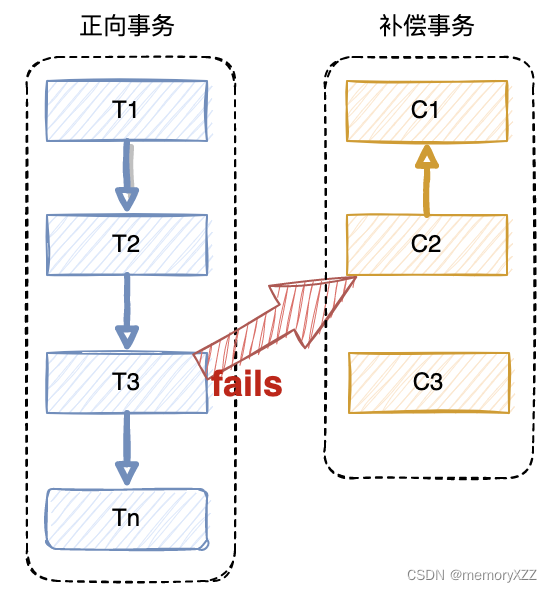
与TCC相比,saga没有”预留“动作,Ti是直接提交到数据库
- 如果所有正向操作都执行成功,则分布式事务提交
- 如果任一一个正向操作执行失败,则分布式事务会回退回去执行前面参与者的回滚操作
本章总结
- 业界普遍使用的是业务补偿、基于消息的最终一致性
DB层面分布式事务协议-XA
- 2PC/3PC:依赖于数据库,能够提供很好的强一致性和强事务性,但相对来说延迟比较高,比较适合传统的单体应用,在同一个方法中跨库操作的情况,不适合高并发和高性能要求的场景。
服务层面分布式事务协议-TCC、消息、safa
- TCC:适用于执行时间较短、实时性、数据一致性要求高场景,如金融企业最核心的三个服务:交易、支付、账务。
- 基于消息最终一致性:事务参与方需支持幂等,对一致性要求不高。
- saga事务:saga事务不能保证隔离性,需在业务层控制并发,适用于业务场景并发操作统一资源较少的情况。saga相比缺少预提交动作,导致补偿动作实现比较麻烦,适用于补偿动作容易处理的场景
四、分布式事务解决方案seata
seata是阿里开源的分布式事务解决方案,提供高性能和简单易用的分布式服务。提供了AT、TCC、SAGA、XA事务模式。
seata支持的事务模式
1、AT模式
- 模式最吸引客户,非侵入式,用户只需关注自己的业务SQL,提高研发效率
- AT模式使用:只需要在方法上加 @GlobalTransactionla注解
@GlobalTransactional
private static class MockClassAnnotation {
// 1.RPC
// 2.本地数据处理 dao.update
// ...
}2、TCC模式-业务侵入性强
- 用户需要根据自己的业务场景实现try()、confirm()、cancel(),事务发起方在一阶段执行try(),二阶段提交执行confirm(),二阶段回滚执行cancel()
3、Saga模式-业务侵入性强
- saga是一种补偿协议,saga模式中,分布式事务有多个参与者,需要用户根据业务场景实现参与者的补偿操作。
4、XA 模式
- 在XA模式中,需要在Seata定义的分布式事务范围内,利用事务资源实现对XA协议的支持,以XA协议的机制来管理分支事务。
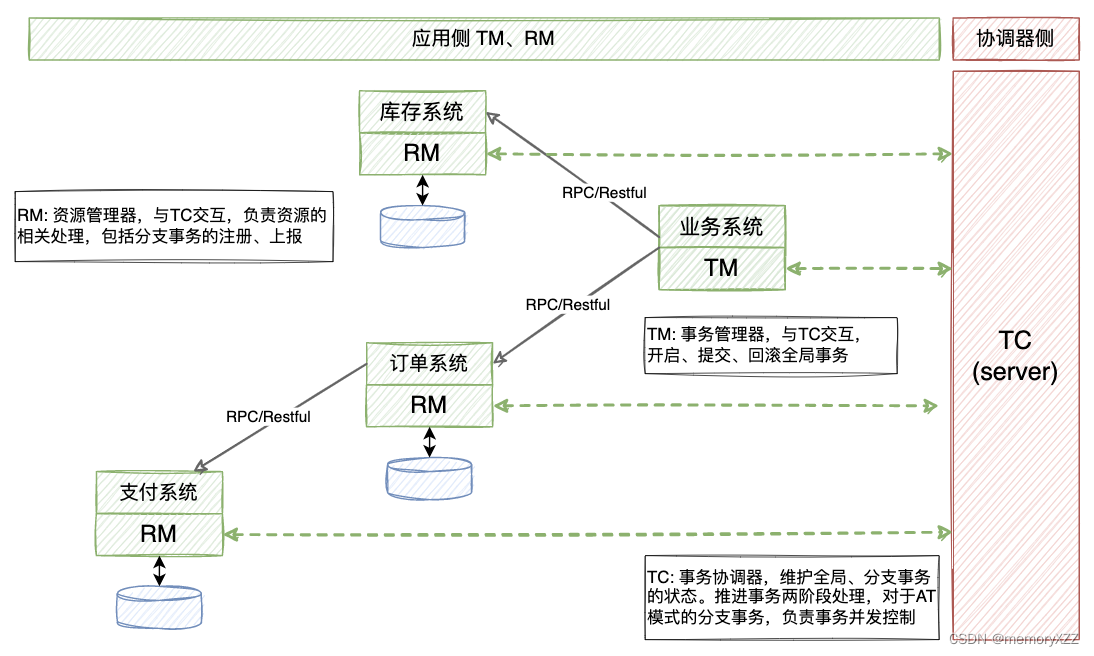
seata的三个主要角色
- TM:事务管理器 Transaction Manager。与TC交互,开启、提交、回滚全局事务
- RM:资源管理器 Resource Manager。与TC交互,负责资源的相关处理,包括分支事务的注册、上报
- TC:事务协调器 Transaction Coordinator。维护全局、分支事务的状态。推进事务两阶段处理,对于AT模式的分支事务,负责事务并发控制
seata处理分布式事务的主要流程
如下图所示

五、seataAT模式
AT模式基本原理
AT模式的一阶段、二阶段提交、二阶段回滚均由seata框架自动生成,用户只需编写 业务SQL代码
处理流程
一阶段流程:
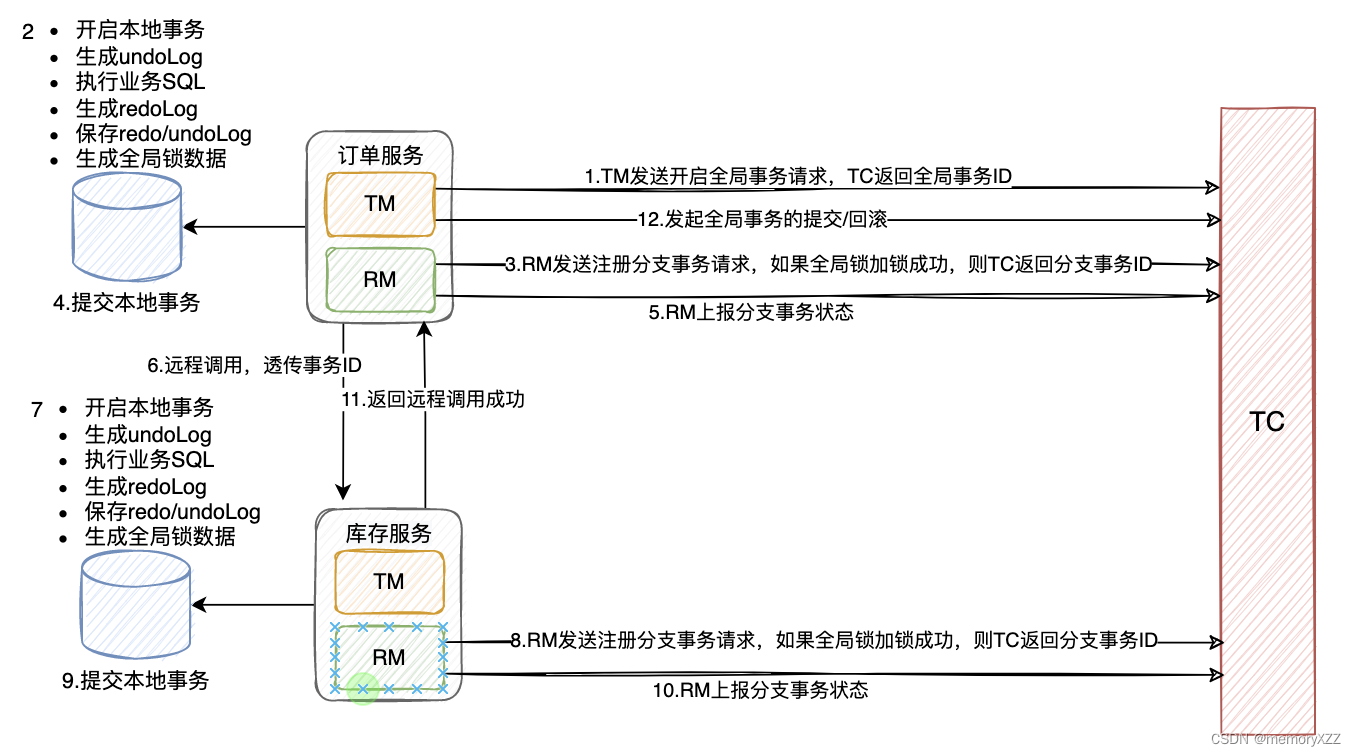
二阶段流程:
二阶段TC收到【全局事务提交/回滚】指令后发起二阶段处理
- 全局事务提交,TC通知多个RM异步清理本地的事务日志
- 全局事务回滚,TC通知每个RM回滚数据 (此时本地事务已提交,通过seata的事务日志回滚当前分布式事务)
事务日志
表SQL
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL, // 分支事务ID
`xid` varchar(100) NOT NULL, // 全局事务ID
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,// 核心字段,记录回滚的数据信息,包含前后镜像
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;日志结构
实例:
{
"@class": "io.seata.rm.datasource.undo.BranchUndoLog",
"xid": "192.168.2.196:8091:104983180048351232",
"branchId": 104983207323910145,
"sqlUndoLogs": ["java.util.ArrayList", [{
"@class": "io.seata.rm.datasource.undo.SQLUndoLog",
"sqlType": "UPDATE",
"tableName": "tab_storage",
"beforeImage": {
"@class": "io.seata.rm.datasource.sql.struct.TableRecords",
"tableName": "tab_storage",
"rows": ["java.util.ArrayList", [{
"@class": "io.seata.rm.datasource.sql.struct.Row",
"fields": ["java.util.ArrayList", [{
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "id",
"keyType": "PRIMARY_KEY",
"type": 4,
"value": ["java.lang.Long", 1]
}, {
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "total",
"keyType": "NULL",
"type": 4,
"value": 88
}, {
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "used",
"keyType": "NULL",
"type": 4,
"value": 12
}]]
}]]
},
"afterImage": {
"@class": "io.seata.rm.datasource.sql.struct.TableRecords",
"tableName": "tab_storage",
"rows": ["java.util.ArrayList", [{
"@class": "io.seata.rm.datasource.sql.struct.Row",
"fields": ["java.util.ArrayList", [{
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "id",
"keyType": "PRIMARY_KEY",
"type": 5,
"value": ["java.lang.Long", 1]
}, {
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "total",
"keyType": "NULL",
"type": 4,
"value": 87
}, {
"@class": "io.seata.rm.datasource.sql.struct.Field",
"name": "used",
"keyType": "NULL",
"type": 4,
"value": 13
}]]
}]]
}
}]]
}- beforeImage:前镜像,”写“操作前的数据备份,记录这个事务事务分支所在行在修改前的数据
- afterImage:后镜像,”写“操作后的数据,记录这个事务分支所修改行在修改后的数据
| 类型 | 前镜像 | 后镜像 | 全局锁数据 | 备注 |
|---|---|---|---|---|
| INSERT | 空 | 新插入行的数据 | 后镜像 | - |
| UPDATE | 更新前数据 | 更新后数据 | 后镜像 | 数据量相同 |
| DELETE | 删除前数据 | 空 | 前镜像 | - |
根据前后镜像可以构建回滚语句,回复到事务进行前的状态。
实例中包含三个对象:
- io.seata.rm.datasource.sql.struct.TableRecords
- io.seata.rm.datasource.sql.struct.Row
- io.seata.rm.datasource.sql.struct.Field
对象结构如下图所示:

通过TableMeta.表元数据、ColumnMeta.列元数据、IndexMeta 索引元数据 可以看到一个完整的数据库表结构定义,在用AT模式处理SQL语句时要使用这些信息,可以从TableREcords中得到这这些信息
表元数据获取方式(AbstractTableMetaCache.getTableMeta())
- 从缓存中获取表元数据,缓存失效时间是900s
- 如果缓存为空或失效,则从数据库中获取表元数据 。构建查询语句得到结果集(包括结果集元数据+数据库元数据,JDBC本身具备的能力),转换成表元数据
事务日志管理器
public interface UndoLogManager {
// 保存事务日志的flushUndoLogs()方法
void flushUndoLogs(ConnectionProxy cp) throws SQLException;
// 二阶段回滚处理的undo()方法
void undo(DataSourceProxy dataSourceProxy, String xid, long branchId) throws TransactionException;
// 二阶段回滚处理的删除事务日志的deleteUndoLog()方法
void deleteUndoLog(String xid, long branchId, Connection conn) throws SQLException;
// 二阶段提交处理的批量删除事务日志的dbatchDeleteUndoLog()方法
void batchDeleteUndoLog(Set<String> xids, Set<Long> branchIds, Connection conn) throws SQLException;
// 根据创建时间删除事务日志的deleteUndoLogByLogCreated()方法
int deleteUndoLogByLogCreated(Date logCreated, int limitRows, Connection conn) throws SQLException;
}seata的数据源代理
数据源代理是AT模式的一个核心组件,seata对java.sql库中的DataSource、Connection、Statement、PreparedStatement 四个接口进行再包装,包装类分别是DataSourceProxy、ConnectionProxy、StatementProxy、PreparedStatementProxy
数据源代理的功能,在SQL执行前后、事务commit、事务rollback执行前后,进行一些与seata分布式事务相关的操作(分支事务的注册、分支状态汇报、全局锁查询、事务日志插入等)
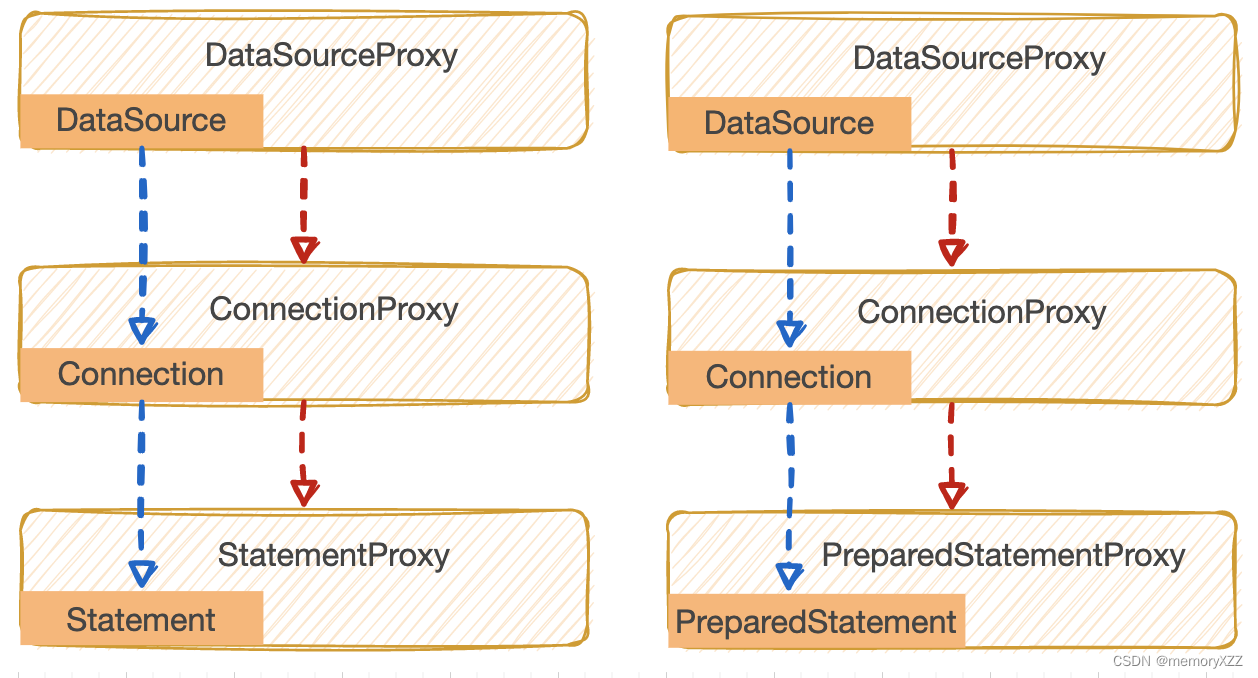
数据源代理类 DataSourceProxy
功能:分析要执行的SQL语句,以及生成对应的回滚SQL语句&资源管理器可以把它看做一个资源进行管理(数据源初始化时将数据源注册到管理器中)

初始化数据源代理:
- 保存数据库信息。数据库连接URL、数据库类型等
- 注册到资源管理器RM
- 定时任务刷新表元数据
资源管理器
资源管理器ResourceManger接口相关类图:
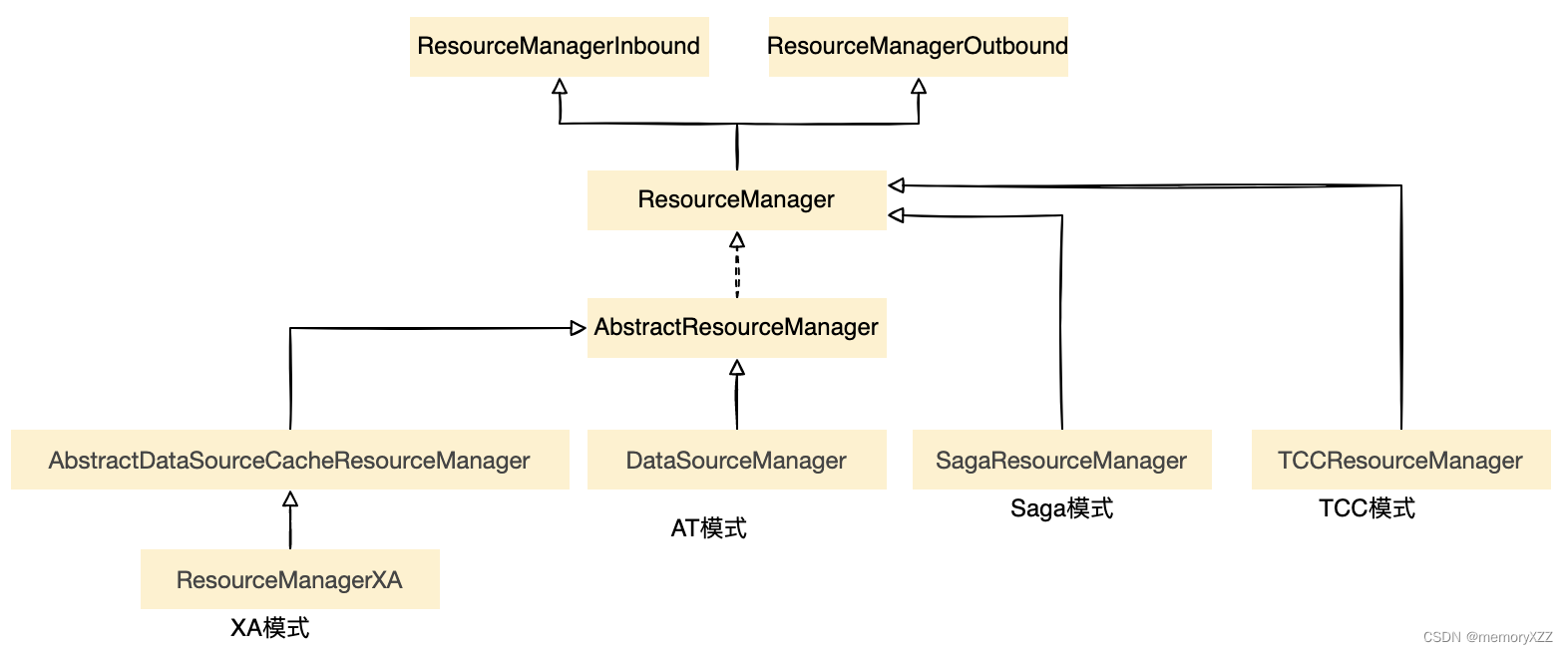
ResourceManager接口
public interface ResourceManager extends ResourceManagerInbound, ResourceManagerOutbound {
// 注册一个资源
void registerResource(Resource resource);
// 取消注册一个资源
void unregisterResource(Resource resource);
// 获取管理的所有资源
Map<String, Resource> getManagedResources();
// 获取分支类型
BranchType getBranchType();
}ResourceManagerInbound接口
定义了“对内”的操作,接收事务协调器TC发来的请求(包括二阶段的分支事务提交请求、二阶段分支事务的回滚请求)
public interface ResourceManagerInbound {
// 提交分支事务
BranchStatus branchCommit(BranchType branchType, String xid, long branchId, String resourceId, String applicationData) throws TransactionException;
// 回滚分支事务
BranchStatus branchRollback(BranchType branchType, String xid, long branchId, String resourceId, String applicationData) throws TransactionException;
}ResourceManagerOutbound接口
定义了“对外”的操作,资源管理器主动发送到事务协调器的事务处理请求(包括分支事务注册、分支事务状态上报,Seata锁查询)
public interface ResourceManagerOutbound {
// 注册分支事务
Long branchRegister(BranchType branchType, String resourceId, String clientId, String xid, String applicationData, String lockKeys) throws
TransactionException;
// 上报分支状态
void branchReport(BranchType branchType, String xid, long branchId, BranchStatus status, String applicationData) throws TransactionException;
// 查询全局锁
boolean lockQuery(BranchType branchType, String resourceId, String xid, String lockKeys) throws TransactionException;
}注册到资源管理器RM
- 注册到RM中,存储在本地缓存中Map<String, Resource> dataSourceCache
- 注册到TC中 二阶段提交、回滚时找到对应的客户端连接并发送请求,保证二阶段操作的高可用
数据库连接代理类ConnectionProxy
本地事务的提交-commit流程:
锁冲突重试
- commit
private void doCommit() throws SQLException {
if (context.inGlobalTransaction()) {
// 1.参与全局事务,进行分支事务提交
processGlobalTransactionCommit();
} else if (context.isGlobalLockRequire()) {
// 2.查询全局锁请求,则查询全局锁
processLocalCommitWithGlobalLocks();
} else {
// 3.普通本地事务
targetConnection.commit();
}
}提交处理流程:
- 参与全局事务,分支事务提交。
- 没参与全局事务,则查询全局锁
- 普通本地事务提交
分支事务提交
- 向TC注册分支事务;
- 保存事务日志;
- 提交本地事务;
- 向TC上报分支事务状态事务
- 日志与业务SQL在同一个本地事务中完成,强绑定,保证了二阶段回滚的幂等性,因为二阶段回滚是以查到事务日志为准
查询全局锁请求
- “为了支持“读未提交”以上的隔离级别。AT工作机制是在一阶段加“Seata全局锁”,提交本地事务,释放数据库锁。
- eg:分布式事务 T1 一阶段完成后,提交本地事务,数据库更改已入库,但T1可能还处于一个未结束的分布式事务。分布式事务T2会读到中间数据。
StatementProxy、PreparedStatementProxy
- Statement:执行SQL语句。执行静态SQL
- PreparesStatement:预编译Statement对象,语句中包含动态参数“?”,动态设置参数值
- sql的执行都是通过模板类ExecuteTemplate.execute()方法实现
protected T executeAutoCommitFalse(Object[] args) throws Exception {
if (!JdbcConstants.MYSQL.equalsIgnoreCase(getDbType()) && isMultiPk()) {
throw new NotSupportYetException("multi pk only support mysql!");
}
// 1.生成前镜像
TableRecords beforeImage = beforeImage();
// 2.执行原始语句
T result = statementCallback.execute(statementProxy.getTargetStatement(), args);
// 3.生成后镜像
TableRecords afterImage = afterImage(beforeImage);
// 4.准备事务日志
prepareUndoLog(beforeImage, afterImage);
return result;
}数据源代理总结:

AT模式的两阶段提交
一阶段处理
处理流程如下图所示。所有操作都在一个数据库本地事务内完成,保证了一阶段操作的原子性。

eg: update storage set count=10 where sku='S1000)'
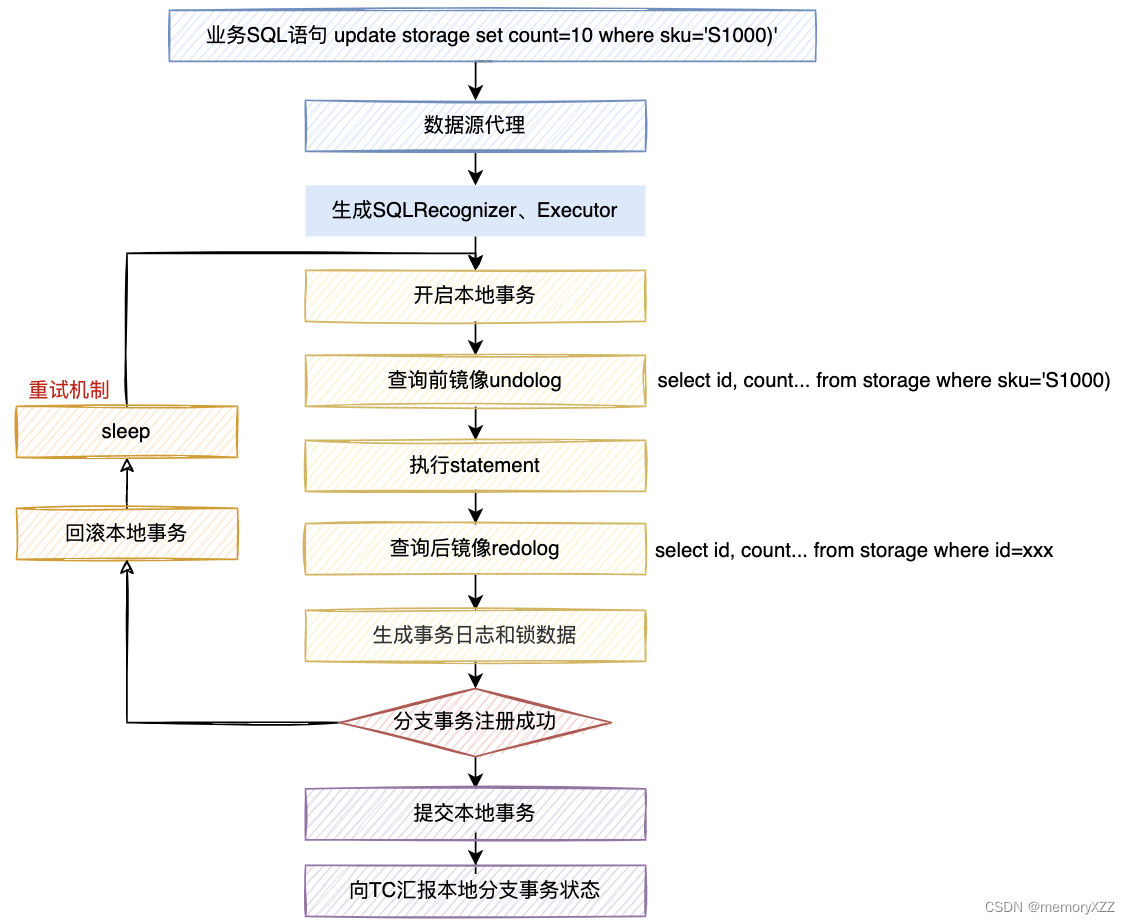
‘“写”隔离
本地事务提交提交前,需向TC注册分支事务,分支注册信息包含【由表名和行主键组成的全局锁数据】。分支注册中发现【全局锁数据】正在被其他全局事务锁定,则抛-全局锁冲突异常,客户端需循环等待,直到其他全局事务放锁后,本地事务才能提交。
二阶段的提交处理
- 立即向TC返回处理成功
- 异步线程跑批删除在二阶段中提交非分支事务日志数据。
二阶段的回滚处理

脏写原因:一阶段已加锁,正常不会出现脏写。出现“脏写”通常是绕过seata对数据进行修改,比如通过SQL工具直接修改数据,需人工排查。
SEATA事务协调器
默认的事务协调器-DefaultCoordinator
public interface TCInboundHandler {
// 处理全局事务开始事件
GlobalBeginResponse handle(GlobalBeginRequest globalBegin, RpcContext rpcContext);
// 处理全局事务提交事件
GlobalCommitResponse handle(GlobalCommitRequest globalCommit, RpcContext rpcContext);
// 处理全局事务回滚事件
GlobalRollbackResponse handle(GlobalRollbackRequest globalRollback, RpcContext rpcContext);
// 处理分支事务注册事件
BranchRegisterResponse handle(BranchRegisterRequest branchRegister, RpcContext rpcContext);
// 处理分支事务上报状态事件
BranchReportResponse handle(BranchReportRequest branchReport, RpcContext rpcContext);
// 处理全局锁查询事件
GlobalLockQueryResponse handle(GlobalLockQueryRequest checkLock, RpcContext rpcContext);
// 处理全局事务状态事件
GlobalStatusResponse handle(GlobalStatusRequest globalStatus, RpcContext rpcContext);
// 处理全局事务状态上报事件
GlobalReportResponse handle(GlobalReportRequest globalReport, RpcContext rpcContext);
}事务的二阶段推进-Core接口
public interface TransactionCoordinatorOutbound {
// 分支事务提交
BranchStatus branchCommit(GlobalSession globalSession, BranchSession branchSession) throws TransactionException;
// 分支事务回滚
BranchStatus branchRollback(GlobalSession globalSession, BranchSession branchSession) throws TransactionException;
}全局锁原理
seata全局锁是AT模式并发控制的核心组件。
分支事务的锁处理流程:
- 开启本地事务,获取数据库锁,可以修改本地数据,但不允许提交本地事务
- 通过TC获取全局锁,可修改数据并持久化
- 提交本地事务,释放数据库锁
- 在全局事务中提交或回滚释放全局锁
seata不会出现死锁
- 顺序固定,先获取数据库锁,再获取全局锁
- 在获取全局锁前,不会释放数据锁
- 获取不到全局锁不会一直等,会快速失败并释放数据库锁
备注:锁管理器接口LockManager
六、附录

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)