k8s 服务注册与发现(四)DNS解析异常问题排查
本文介绍关于DNS解析异常的诊断流程、排查思路、常见解决方案和排查方法。
DNS解析异常问题排查
https://help.aliyun.com/document_detail/404754.html#section-tuh-1hn-yhd
本文介绍关于DNS解析异常的诊断流程、排查思路、常见解决方案和排查方法。
本文目录
诊断流程
基本概念
- 集群内部域名:CoreDNS会将集群中的服务暴露为集群内部域名,默认以
.cluster.local结尾,这类域名的解析通过CoreDNS内部缓存完成,不会从上游DNS服务器查询。 - 集群外部域名:除了集群内部域名以外的域名。外部域名可由CoreDNS配置文件提供解析结果,或从DNSConfig配置文件中指定的上游DNS服务器查询,默认使用阿里云VPC中的私网DNS服务地址(100.100.2.136和100.100.2.138)。您可以修改其为您自建的DNS服务器。
- 业务Pod:您部署在Kubernetes集群中的容器Pod,不包含Kubernetes自身系统组件的容器。
- 接入CoreDNS的业务Pod:容器内DNS服务器指向了CoreDNS的业务Pod。
- 接入NodeLocal DNSCache的业务Pod:集群中安装了NodeLocal DNSCache插件后,通过自动或手动方式注入DNSConfig的业务Pod。这类Pod在解析域名时,会优先访问本地缓存组件。如果访问本地缓存组件不通时,会访问CoreDNS提供的kube-dns服务。
异常诊断流程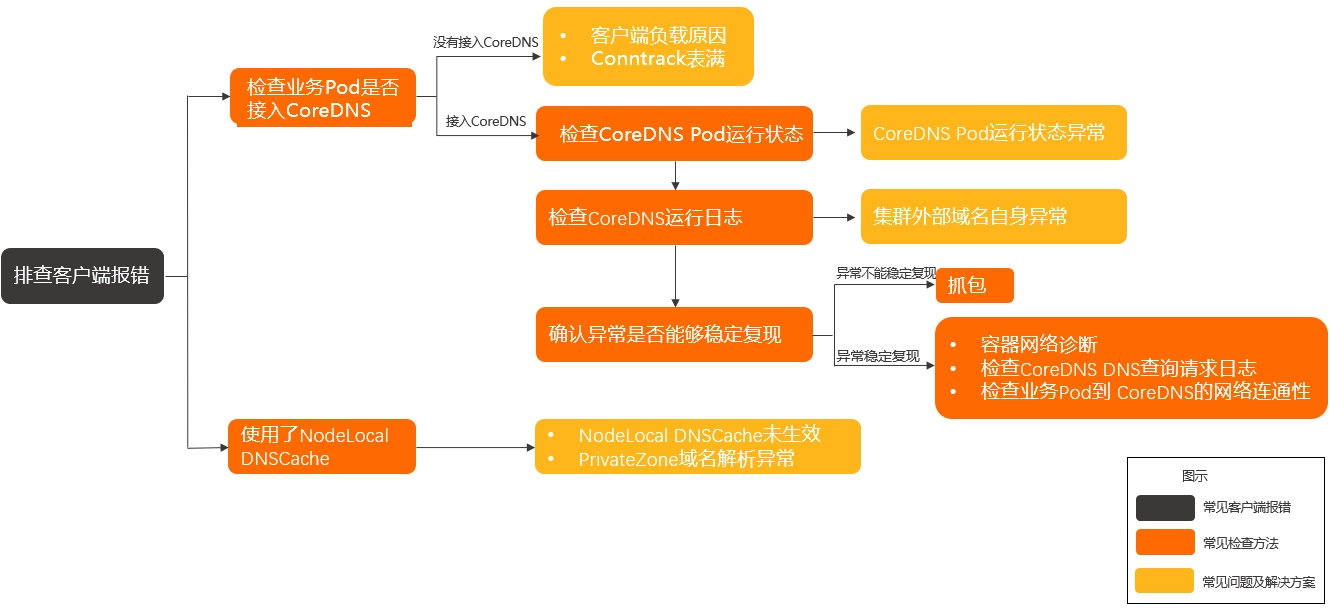
-
判断当前的异常原因。具体信息,请参见常见客户端报错。
-
如果以上排查无果,请按以下步骤排查。
-
检查业务Pod的DNS配置,是否已经接入CoreDNS。具体操作,请参见
。
- 如果没有接入CoreDNS,则考虑是客户端负载原因或Conntrack表满导致解析失败。具体操作,请参见客户端负载原因导致解析失败和Conntrack表满。
- 如果接入了CoreDNS,则按以下步骤排查。
- 通过检查CoreDNS Pod运行状态进行诊断。具体操作,请参见检查CoreDNS Pod运行状态和CoreDNS Pod运行状态异常。
- 通过检查CoreDNS运行日志进行诊断。具体操作,请参见检查CoreDNS运行日志和集群外部域名自身异常。
- 确认异常是否能够稳定复现。
- 如果异常稳定复现,请参见检查CoreDNS DNS查询请求日志、容器网络诊断和检查业务Pod到CoreDNS的网络连通性。
- 如果异常不能稳定复现,请参见抓包。
-
如果使用了NodeLocal DNSCache,请参见NodeLocal DNSCache未生效和PrivateZone域名解析异常。
-
-
如果以上排查无果,请提交工单排查。
常见客户端报错
| 客户端 | 报错日志 | 可能异常 |
|---|---|---|
| ping | ping: xxx.yyy.zzz: Name or service not known |
域名不存在或无法连接域名服务器。如果解析延迟大于5秒,一般是无法连接域名服务器。 |
| curl | curl: (6) Could not resolve host: xxx.yyy.zzz |
|
| PHP HTTP客户端 | php_network_getaddresses: getaddrinfo failed: Name or service not known in xxx.php on line yyy |
|
| Golang HTTP客户端 | dial tcp: lookup xxx.yyy.zzz on 100.100.2.136:53: no such host |
域名不存在。 |
| dig | ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: xxxxx |
|
| Golang HTTP客户端 | dial tcp: lookup xxx.yyy.zzz on 100.100.2.139:53: read udp 192.168.0.100:42922->100.100.2.139:53: i/o timeout |
无法连接域名服务器。 |
| dig | ;; connection timed out; no servers could be reached |
排查思路
| 排查思路 | 排查依据 | 问题及解决方案 |
|---|---|---|
| 按解析异常的域名类型排查 | 集群内外域名都异常 | 安全组、交换机ACL配置错误容器网络连通性异常CoreDNS Pod负载高CoreDNS Pod负载不均CoreDNS Pod运行状态异常Conntrack表满AutoPath插件异常A记录和AAAA记录并发解析异常IPVS缺陷导致解析异常 |
| 仅集群外部域名异常 | 集群外部域名自身异常 | |
| 仅PrivateZone 、vpc-proxy域名解析异常 | PrivateZone域名解析异常 | |
| 仅Headless类型服务域名异常 | 新增Headless类型域名无法解析StatefulSets Pod域名无法解析 | |
| 按解析异常出现频次排查 | 完全无法解析 | CoreDNS Pod运行状态异常PrivateZone域名解析异常安全组、交换机ACL配置错误集群外部域名自身异常新增Headless类型域名无法解析StatefulSets Pod域名无法解析容器网络连通性异常 |
| 异常仅出现在业务高峰时期 | CoreDNS Pod负载高CoreDNS Pod负载不均 | |
| 异常出现频次非常高 | IPVS缺陷导致解析异常NodeLocal DNSCache未生效 | |
| 异常出现频次非常低 | AutoPath插件异常A记录和AAAA记录并发解析异常 | |
| 异常仅出现在节点扩缩容或CoreDNS缩容时 | IPVS缺陷导致解析异常 |
常见检查方法
检查业务Pod的DNS配置
-
命令
#查看foo容器的YAML配置,并确认DNSPolicy字段是否符合预期。 kubectl get pod foo -o yaml #当DNSPolicy符合预期时,可以进一步进入Pod容器中,查看实际生效的DNS配置。 #通过bash命令进入foo容器,若bash不存在可使用sh代替。 kubectl exec -it foo bash #进入容器后,可以查看DNS配置,nameserver后面为DNS服务器地址。 cat /etc/resolv.conf -
DNS Policy配置说明
DNS Policy示例如下所示。
apiVersion: v1 kind: Pod metadata: name: <pod-name> namespace: <pod-namespace> spec: containers: - image: <container-image> name: <container-name> #默认场景下的DNS Policy。 dnsPolicy: ClusterFirst #使用了NodeLocal DNSCache时的DNS Policy。 dnsPolicy: None dnsConfig: nameservers: - 169.254.20.10 - 172.21.0.10 options: - name: ndots value: "3" - name: timeout value: "1" - name: attempts value: "2" searches: - default.svc.cluster.local - svc.cluster.local - cluster.local securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30DNSPolicy字段值 使用的DNS服务器 Default 只适用于不需要访问集群内部服务的场景。Pod创建时会从ECS节点/etc/resolv.conf文件继承DNS服务器列表。 ClusterFirst 此为DNSPolicy默认值,Pod会将CoreDNS提供的kube-dns服务IP作为DNS服务器。开启HostNetwork的Pod,如果选择ClusterFirst模式,效果等同于Default模式。 ClusterFirstWithHostNet 开启HostNetwork的Pod,如果选择ClusterFirstWithHostNet模式,效果等同于ClusterFirst。 None 配合DNSConfig字段,可用于自定义DNS服务器和参数。在NodeLocal DNSCache开启注入时,DNSConfig会将DNS服务器指向本地缓存IP及CoreDNS提供的kube-dns服务IP。
检查CoreDNS Pod运行状态
命令
-
执行以下命令,查看容器组信息。
kubectl -n kube-system get pod -o wide -l k8s-app=kube-dns预期输出:
NAME READY STATUS RESTARTS AGE IP NODE coredns-xxxxxxxxx-xxxxx 1/1 Running 0 25h 172.20.6.53 cn-hangzhou.192.168.0.198 -
执行以下命令,查看Pod的实时资源使用情况。
kubectl -n kube-system top pod -l k8s-app=kube-dns预期输出:
NAME CPU(cores) MEMORY(bytes) coredns-xxxxxxxxx-xxxxx 3m 18Mi -
如果Pod不处于Running状态,可以通过
kubectl -n kube-system describe pod <CoreDNS Pod名称>命令,查询问题原因。
检查CoreDNS运行日志
命令
执行以下命令,检查CoreDNS运行日志。
kubectl -n kube-system logs -f --tail=500 --timestamps coredns-xxxxxxxxx-xxxxx
| 参数 | 描述 |
|---|---|
f |
持续输出。 |
tail=500 |
输出最后500行日志。 |
timestamps |
同时显示日志打印的时间。 |
coredns-xxxxxxxxx-xxxxx |
CoreDNS Pod副本的名称。 |
检查CoreDNS DNS查询请求日志
命令
DNS查询请求日志仅会在开启CoreDNS的Log插件后,才会打印到容器日志中。关于开启Log插件的具体操作,请参见CoreDNS配置说明。
命令与检查CoreDNS运行日志相同,请参见检查CoreDNS运行日志。
检查CoreDNS Pod的网络连通性
操作步骤
-
登录CoreDNS Pod所在集群节点。
-
执行
ps aux | grep coredns,查询CoreDNS的进程ID。 -
执行
nsenter -t <pid> -n bash,进入CoreDNS所在容器网络命名空间,其中pid为上一步得到的进程ID。 -
测试网络连通性。
-
运行
telnet <apiserver_slb_ip> 443,测试Kubernetes API Server的连通性。其中
apiserver_slb_ip为default命名空间下Kubernetes服务的IP地址。 -
运行
dig <domain> @<upstream_dns_server_ip>,测试CoreDNS Pod到上游DNS服务器的连通性。其中
domain为测试域名,upstream_dns_server_ip为上游DNS服务器地址,默认为100.100.2.136和100.100.2.138。
-
常见问题
| 现象 | 原因 | 处理方案 |
|---|---|---|
| CoreDNS无法连通Kubernetes API Server | APIServe异常、机器负载高、kube-proxy 没有正常运行等。 | 可提交工单排查。 |
| CoreDNS无法连通上游DNS服务器 | 机器负载高、CoreDNS配置错误、专线路由问题等。 | 可提交工单排查。 |
检查业务Pod到CoreDNS的网络连通性
操作步骤
-
选择以下任意一种方式,进入客户端Pod容器网络。
-
方法一:使用
kubectl exec命令。 -
方法二:
-
登录业务Pod所在集群节点。
-
执行
ps aux | grep <业务进程名>命令,查询业务容器的进程ID。 -
执行
nsenter -t <pid> -n bash命令,进入业务Pod所在容器网络命名空间。
其中
pid为上一步得到的进程ID。
-
-
方法三:如果频繁重启,请按以下步骤操作。
-
登录业务Pod所在集群节点。
-
执行
docker ps -a | grep <业务容器名>命令,查询k8s_POD_开头的沙箱容器,记录容器ID。 -
执行
docker inspect <沙箱容器 ID> | grep netns命令,查询/var/run/docker/netns/xxxx的容器网络命名空间路径。 -
执行
nsenter -n<netns 路径> bash命令,进入容器网络命名空间。
其中
netns 路径为上一步得到的路径。说明
-n和<netns 路径>之间不加空格。
-
-
-
测试网络连通性。
-
执行
dig <domain> @<kube_dns_svc_ip>命令,测试业务Pod到CoreDNS服务kube-dns解析查询的连通性。其中
<domain>为测试域名,<kube_dns_svc_ip>为kube-system命名空间中kube-dns的服务IP。 -
执行
ping <coredns_pod_ip>命令,测试业务Pod到CoreDNS容器副本的连通性。其中
<coredns_pod_ip>为kube-system命名空间中CoreDNS Pod的IP。 -
执行
dig <domain> @<coredns_pod_ip>命令,测试业务Pod到CoreDNS容器副本解析查询的连通性。其中
<domain>为测试域名,<coredns_pod_ip>为kube-system命名空间中CoreDNS Pod的IP。
-
常见问题
| 现象 | 原因 | 处理方案 |
|---|---|---|
| 业务Pod无法通过CoreDNS服务kube-dns解析 | 机器负载高、kube-proxy没有正常运行、安全组没有放开UDP协议53端口等。 | 检查安全组是否放开UDP 53端口,若已放开请提交工单排查。 |
| 业务Pod无法连通CoreDNS容器副本 | 容器网络异常或安全组没有放开ICMP。 | 运行容器网络诊断。 |
| 业务Pod无法通过CoreDNS容器副本解析 | 机器负载高、安全组没有放开UDP协议53端口等。 | 检查安全组是否放开UDP 53端口,若已放开请提交工单排查。 |
容器网络诊断
-
登录容器服务管理控制台。
-
在集群列表页面中,单击目标集群名称或者目标集群右侧操作列下的详情。
-
在控制台左侧导航栏中,单击集群。
-
在集群管理页左侧导航栏中,选择****运维管理** > *集群检查***。
-
在容器智能运维的左侧导航栏,选择****检查** > *故障诊断***。
-
在故障诊断页面,单击网络诊断页签。
-
在源地址输入业务Pod IP,在目标地址输入CoreDNS服务kube-dns IP,在端口输入53,同时选中报文跟踪,选中我已知晓并同意,单击发起诊断。
-
在故障诊断列表,单击目标诊断项右侧操作列的诊断详情。
根据诊断结果、访问全图及展开所有访问路径查看网络诊断详情,诊断结果将包含异常原因。关于网络诊断的具体操作,请参见通过集群故障诊断功能定位集群问题。
抓包
当无法定位问题时,需要抓包进行辅助诊断。
-
登录出现异常的业务Pod、CoreDNS Pod所在节点。
-
在ECS(非容器内)执行以下命令,可以将最近所有的53端口信息抓取到文件中。
tcpdump -i any port 53 -C 20 -W 200 -w /tmp/client_dns.pcap -
结合业务日志的报错定位到精准的报错时间的报文信息。
说明
- 在正常情况下,抓包对业务无影响,仅会增加小部分的CPU负载和磁盘写入。
- 以上命令会对抓取到的包进行rotate,最多可以写200个20 MB的.pcap文件。
集群外部域名自身异常
问题原因
上游服务器返回记录显示域名异常。
问题现象
业务Pod可以正常解析集群内部域名,但无法解析某些集群外部域名。
解决方案
检查CoreDNS DNS查询请求日志。
常见请求日志
CoreDNS接收到请求并回复客户端后会打印一行日志,示例如下:
# 其中包含状态码RCODE NOERROR,代表解析结果正常返回。
[INFO] 172.20.2.25:44525 - 36259 "A IN redis-master.default.svc.cluster.local. udp 56 false 512" NOERROR qr,aa,rd 110 0.000116946s
常见返回码RCODE
关于返回码RCODE定义的具体信息,请参见规范。
| 返回码RCODE | 含义 | 原因 |
|---|---|---|
| NXDOMAIN | 域名不存在 | 容器内请求域名时,会被拼接上search后缀,若拼接的结果域名不存在,则会出现该请求码。如果确认日志中请求的域名内容存在,则说明存在异常。 |
| SERVFAIL | 上游服务器异常 | 常见于无法连接上游DNS服务器等情况。 |
| REFUSED | 拒绝应答 | 常见于CoreDNS配置或集群节点/etc/resolv.conf文件指向的上游DNS服务器无法处理该域名的情况,请排查CoreDNS配置文件。 |
新增Headless类型域名无法解析
问题原因
1.7.0以前版本CoreDNS会在API Server抖动时异常退出,导致Headless域名停止更新。
问题现象
接入CoreDNS的业务Pod无法解析新增的Headless类型域名。
解决方案
升级CoreDNS至1.7.0以上。具体操作,请参见【组件升级】CoreDNS升级公告。
StatefulSets Pod域名无法解析
问题原因
StatefulSets Pod YAML中ServiceName必须和其暴露SVC的名字一致,否则无法访问Pod域名(例如pod.headless-svc.ns.svc.cluster.local),只能访问到服务域名(例如headless-svc.ns.svc.cluster.local)。
问题现象
Headless服务无法通过Pod域名解析。
解决方案
修改StatefulSets Pod YAML中ServiceName名称。
安全组、交换机ACL配置错误
问题原因
修改了ECS或容器使用的安全组(或交换机ACL),拦截了UDP协议下53端口的通信。
问题现象
部分节点或全部节点上接入CoreDNS的业务,Pod解析域名持续性失败。
解决方案
恢复安全组、交换机ACL的配置,放开其以UDP协议对53端口的通信。
容器网络连通性异常
问题原因
由于容器网络或其它原因导致的UDP协议53端口持续性不通。
问题现象
部分节点或全部节点上接入CoreDNS的业务,Pod解析域名持续性失败。
解决方案
运行容器网络诊断。具体操作,请参见通过集群故障诊断功能定位集群问题。
CoreDNS Pod负载高
问题原因
由于CoreDNS副本数不足、业务请求量高等情况导致的CoreDNS负载高。
问题现象
- 部分节点或全部节点接入CoreDNS的业务,Pod解析域名的延迟增加、概率性或持续性失败。
- 检查CoreDNS Pod运行状态发现各副本CPU、Memory使用量接近其资源限制。
解决方案
- 考虑采用NodeLocal DNSCache缓存方案,提升DNS解析性能,降低CoreDNS负载。具体操作,请参见使用NodeLocal DNSCache。
- 适当扩充CoreDNS副本数,使每个Pod的峰值CPU始终低于节点空闲CPU数。
CoreDNS Pod负载不均
问题原因
由于CoreDNS副本调度不均、Service亲和性设置导致CoreDNS Pod负载不均衡。
问题现象
- 部分接入CoreDNS的业务Pod解析域名的延迟增加、概率性或持续性失败。
- 检查CoreDNS Pod运行状态发现各副本CPU使用量负载不均衡。
- CoreDNS副本数少于两个,或多个CoreDNS副本位于同节点上。
解决方案
- 扩容并打散CoreDNS副本到不同的节点上。
- 负载不均衡时,可禁用kube-dns服务的亲和性属性。具体操作,请参见配置Kube-DNS服务。
CoreDNS Pod运行状态异常
问题原因
由于CoreDNS YAML模板、配置文件等导致CoreDNS运行异常。
问题现象
- 部分接入CoreDNS的业务Pod解析域名的延迟增加、概率性或持续性失败。
- CoreDNS副本状态Status不处于Running状态,或重启次数RESTARTS持续增加。
- CoreDNS运行日志中出现异常。
解决方案
检查CoreDNS Pod运行状态和运行日志。
常见异常日志及处理方案
| 日志中字样 | 原因 | 处理方案 |
|---|---|---|
/etc/coredns/Corefile:4 - Error during parsing: Unknown directive 'ready' |
配置文件和CoreDNS不兼容,Unknown directive代表当前运行的CoreDNS版本不支持ready插件。 |
从kube-system命名空间中CoreDNS配置项中删除ready插件,其它报错同理。 |
pkg/mod/k8s.io/client-go@v0.18.3/tools/cache/reflector.go:125: Failed to watch *v1.Pod: Get "https://192.168.0.1:443/api/v1/": dial tcp 192.168.0.1:443: connect: connection refused |
日志出现时间段内,API Server中断。 | 如果是日志出现时间和异常不吻合,可以排除该原因,否则请检查CoreDNS Pod网络连通性。具体操作,请参见检查CoreDNS Pod的网络连通性。 |
[ERROR] plugin/errors: 2 www.aliyun.com. A: read udp 172.20.6.53:58814->100.100.2.136:53: i/o timeout |
日志出现时间段内,CoreDNS无法连接到上游DNS服务器。 |
客户端负载原因导致解析失败
问题原因
接入CoreDNS的业务Pod所在ECS负载达到100%等情况导致UDP报文丢失。
问题现象
业务高峰期间或突然偶发的解析失败,ECS监控显示机器网卡重传率、CPU负载有异常。
解决方案
- 建议提交工单排查原因。
- 考虑采用NodeLocal DNSCache缓存方案,提升DNS解析性能,降低CoreDNS负载。具体操作,请参见使用NodeLocal DNSCache。
Conntrack表满
问题原因
Linux内Conntrack表条目有限,无法进行新的UDP或TCP请求。
问题现象
- 部分节点或全部节点上接入CoreDNS的业务,Pod解析域名在业务高峰时间段内出现大批量域名解析失败,高峰结束后失败消失。
- 运行
dmesg -H,滚动到问题对应时段的日志,发现出现conntrack full字样的报错信息。
解决方案
增加Conntrack表限制。具体操作,请参见如何提升Linux连接跟踪Conntrack数量限制?。
AutoPath插件异常
问题原因
CoreDNS处理缺陷导致AutoPath无法正常工作。
问题现象
- 解析集群外部域名时,概率性解析失败或解析到错误的IP地址,解析集群内部域名无异常。
- 高频创建容器时,集群内部服务域名解析到错误的IP地址。
解决方案
按照以下步骤,关闭AutoPath插件。
- 执行
kubectl -n kube-system edit configmap coredns命令,打开CoreDNS配置文件。 - 删除
autopath @kubernetes一行后保存退出。 - 检查CoreDNS Pod运行状态和运行日志,运行日志中出现
reload字样后说明修改成功。
A记录和AAAA记录并发解析异常
问题原因
并发A和AAAA的DNS请求触发Linux内核Conntrack模块缺陷,导致UDP报文丢失。
问题现象
- 接入CoreDNS的业务Pod解析域名概率性失败。
- 从抓包或检查CoreDNS DNS查询请求日志可以发现,A和AAAA通常在同一时间的出现,并且请求的源端口一致。
解决方案
- 考虑采用NodeLocal DNSCache缓存方案,提升DNS解析性能,降低CoreDNS负载。具体操作,请参见使用NodeLocal DNSCache。
- CentOS、Ubuntu等基础镜像,可以通过
options timeout:2 attempts:3 rotate single-request-reopen等参数优化。 - 如果容器镜像是以Alpine制作的,建议更换基础镜像。更多信息,请参见Alpine。
- PHP类应用短连接解析问题较多,如果使用的是PHP Curl的调用,可以使用
CURL_IPRESOLVE_V4参数仅发送IPv4解析。更多信息,请参见函数说明。
IPVS缺陷导致解析异常
问题原因
若您集群的kube-proxy负载均衡模式为IPVS,在CentOS、Alibaba Cloud Linux 2内核版本小于4.19.91-25.1.al7.x86_64的节点上,摘除IPVS UDP类型后端后,一段时间内若新发起的UDP报文源端口冲突,该报文会被丢弃。
问题现象
当集群节点扩缩容、节点关机、CoreDNS缩容时,出现概率性解析失败,通常时长在五分钟左右。
解决方案
- 考虑采用NodeLocal DNSCache缓存方案,可以容忍IPVS丢包。具体操作,请参见使用NodeLocal DNSCache。
- 优化IPVS UDP超时时间。具体操作,请参见配置IPVS类型集群的UDP超时时间。
NodeLocal DNSCache未生效
问题原因
- 未配置DNSConfig注入,业务Pod实际仍配置了CoreDNS kube-dns服务IP作为DNS服务器地址。
- 业务Pod采用Alpine作为基础镜像,Alpine基础镜像会并发请求所有nameserver,包括本地缓存和CoreDNS。
问题现象
NodeLocal DNSCache没有流量进入,所有请求仍在CoreDNS上。
解决方案
- 配置DNSConfig自动注入。具体操作,请参见使用NodeLocal DNSCache。
- 如果容器镜像是以Alpine制作的,建议更换基础镜像。更多信息,请参见Alpine。
PrivateZone域名解析异常
问题原因
PrivateZone不支持TCP协议,需要使用UDP协议访问。
问题现象
对于接入NodeLocal DNSCache的业务,Pod无法解析PrivateZone上注册的域名,或无法解析包含vpc-proxy字样的阿里云云产品API域名,或解析结果不正确。
解决方案
在CoreDNS中配置prefer_udp。具体操作,请参见CoreDNS配置说明。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)