关于springboot项目的tomcat之url解码问题
springboot内嵌的tomcat之url解码问题
最近遇到一个问题
spring-boot项目,收到对方get请求里面的中文,乱码。
get请求会经过url编码,里面的中文,同样也被转换,类似这样:
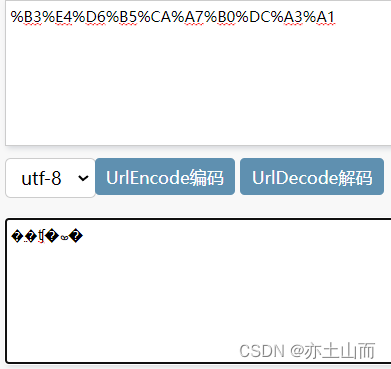
localhost:8080/callback/test?RetMsg=%B3%E4%D6%B5%CA%A7%B0%DC%A3%A1&Version=1.0
这串东西:%B3%E4%D6%B5%CA%A7%B0%DC%A3%A1 用gbk编码解出来就是“充值失败!”

用utf-8解出来就是乱码
因为对方是gbk编码,于是项目中配置一个 server.tomcat.uri-encoding: gbk
问题解决。
但是该项目并不是一个特定的项目,而是一个通用的项目,必须通过配置兼容各种编码,对于某一接入方来说是gbk,对于另外的接入方可能是utf-8
很明显,不能这样写死。
怎么办?
想到了在代码中处理,对乱码进行先url编码,再重新url解码
但是试了一些情况都没成功,比如上面举的那条例子,在配置文件中什么都不配置,然后用utf-8进行url编码或者iso-8859-1进行编码,再用本身的gbk编码, 结果仍然是乱码。
经过一番尝试,发现在配置文件中这样配置:
server.tomcat.uri-encoding: iso-8859-1
然后在代码中对乱码进行iso-8859-1的url编码,然后再用配置的编码进行解码,问题解决。
content = URLDecoder.decode(URLEncoder.encode(content, "iso8859-1"), configCharset);问题是解决了,还是想稍微深入了解一下,于是进行debug
调用request.getParameter:
String content = request.getParameter("RetMsg");
会调用到Request类的
public String getParameter(String name) {
if (!this.parametersParsed) {
this.parseParameters();
}
return this.coyoteRequest.getParameters().getParameter(name);
}然后会进入到 parseParameters() 这个方法:
protected void parseParameters() {
this.parametersParsed = true;
Parameters parameters = this.coyoteRequest.getParameters();
boolean success = false;此时:
parameters:见截图
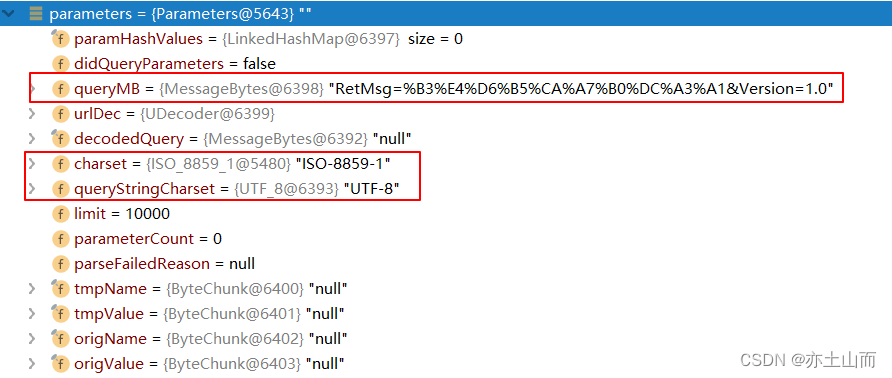
其中,charset 和 queryStringCharset 是构造方法中默认的:
public Parameters() { this.charset = StandardCharsets.ISO_8859_1; this.queryStringCharset = StandardCharsets.UTF_8; this.limit = -1; this.parameterCount = 0; this.parseFailedReason = null; this.tmpName = new ByteChunk(); this.tmpValue = new ByteChunk(); this.origName = new ByteChunk(); this.origValue = new ByteChunk(); }
跟着代码走,会调用到parseParameters()中的这段 parameters.handleQueryParameters();
最终走到:org.apache.tomcat.util.http.Parameters的processParameters()方法
这里的这个value还是encode的初始值(记住这张图,待会儿还要回来)
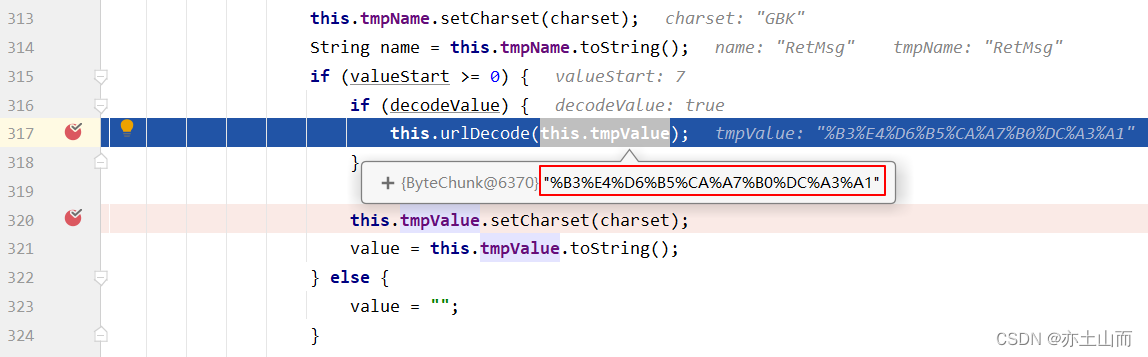
this.urlDecode(this.tmpValue) -> this.urlDec.convert(bc, true) ->
this.convert(mb, true, EncodedSolidusHandling.DECODE);
this.convert 是 org.apache.tomcat.util.buf.UDecoder 类中的方法
注意此时 ByteChunk 对象中的编码是 ISO-8859-1,这是默认的
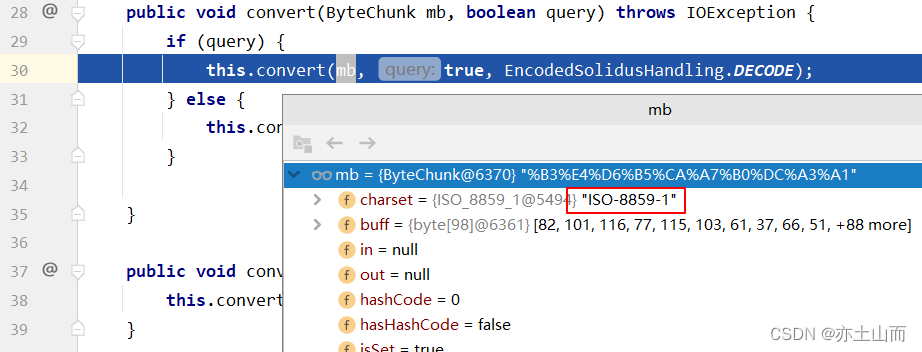
然后在这个重载的this.convert(mb, true, EncodedSolidusHandling.DECODE); 方法中
会进行一次url解码,编码是 ISO-8859-1,解码之后是一堆乱码

回到刚刚这段代码:
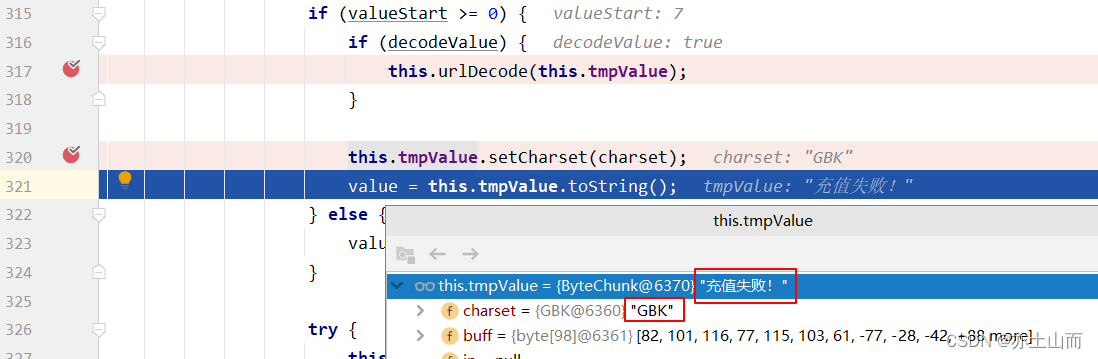
如果我们在配置文件中设置了GBK编码

下一步,发现setCharset为GBK之后,tmpValue已经正确解码了
但是如果我们没有在配置文件中指定编码,默认utf-8
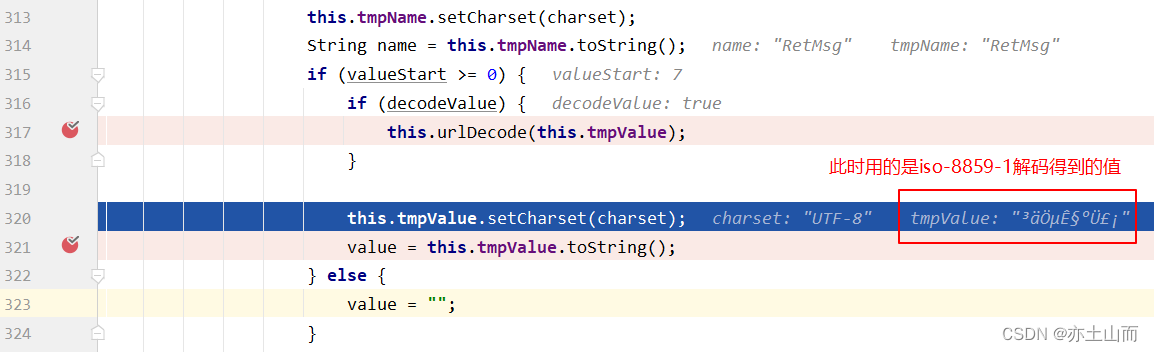

在调用完this.tmpValue.setCharset(charset)方法之后,tmpValue也已经变成了另外一种乱码了
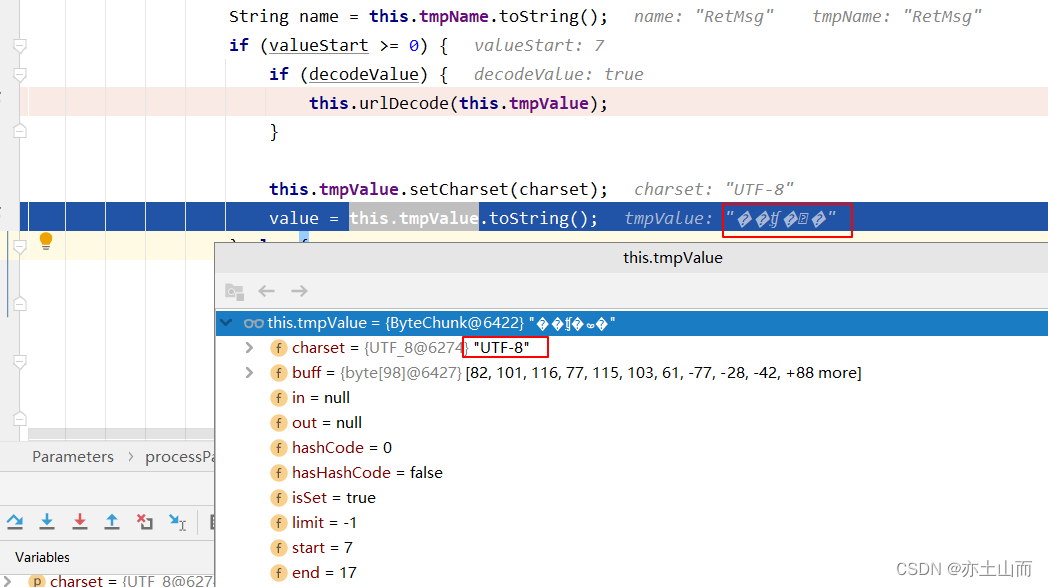
(具体为什么this.tmpValue.setCharset(charset)之后,就进行了编码,没看到具体在哪里触发的,暂时不深究了,如果哪位大神知道,烦请指出。)
不管如何配置,this.urlDecode(this.tmpValue) 这一步是不变的:

关键是在 this.tmpValue.setCharset(charset)
1.默认是UTF-8
2.中文用什么编码encode的,则配置成该编码,这一步则解码成功
3.中文用什么编码encode的,配置文件中配置成除 iso-8859-1 之外的其它编码,则永远乱码了
4.不管中文是用什么编码encode的,配置为iso-8859-1,则这种乱码可以通过后期编码再解码得到解决
所以综上,万能方法:
配置文件中配置为iso-8859-1,然后代码中用iso-8859-1去url编码一次,最后用正确的编码去解码
URLDecoder.decode(URLEncoder.encode(requestValue, "iso8859-1"), rightCharset);

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)