ShardingSphere分库分表(SpringBoot+mybatis+mysql)配置
ShardingSphere定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准
一、什么是ShardingSphere
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能。
二、应用场景
单数据库系统往往会随着业务的增长而导致无法满足互联网海量数据的应用场景,在性能,可用性以及运维等方面遇到瓶颈。为了解决这种问题,数据库横向以及纵向扩展(分库分表)的中间件也伴随满足类似的需求而产生。常见的分库分表的中间件有MyCat,ShardingSphere以及阿里巴巴分布式数据库服务DRDS。ShardingSphere是一套开源的分布式数据库中间件,当前就一个基于springBoot+mybatis+mysql的实例对ShardingSpher的分库分表配置操作进行详细的介绍。
三、实现过程
一、准备数据库环境
1、首先安装两个MySql数据库
(它们的端口分别为3306和3307),创建方式请参考这里。
2、在两个数据库中分别创建数据库
CREATE DATABASE shardingsphere;
3、在两个数据库中分别创建两张表
DROP TABLE IF EXISTS `t_user_0`;
CREATE TABLE `t_user_0` (
`user_id` bigint(32) NOT NULL COMMENT '主键',
`id_number` varchar(18) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '身份证号码',
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '姓名',
`age` int(4) NULL DEFAULT NULL COMMENT '年龄',
`gender` int(2) NULL DEFAULT 1 COMMENT '性别:1-男;2-女',
`birth_date` date NULL DEFAULT NULL COMMENT '出生日期',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表' ROW_FORMAT = Compact;
DROP TABLE IF EXISTS `t_user_1`;
CREATE TABLE `t_user_1` (
`user_id` bigint(32) NOT NULL COMMENT '主键',
`id_number` varchar(18) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '身份证号码',
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '姓名',
`age` int(4) NULL DEFAULT NULL COMMENT '年龄',
`gender` int(2) NULL DEFAULT 1 COMMENT '性别:1-男;2-女',
`birth_date` date NULL DEFAULT NULL COMMENT '出生日期',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表' ROW_FORMAT = Compact;
二、代码实现
1、创建一个springBoot系统
(本文使用的IDE工具是IntelliJ IDEA 2019.2 x64,具体过程请自行网上搜索创建),系统名称为shardingsphere。首先编写maven的pom.xml文件。此处shardingSphere使用的版本是3.1.0。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.teamo</groupId>
<artifactId>shardingsphere</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingsphere</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.60</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>5.1.32</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、编写配置文件application.yml文件
此处主要配置两个数据源ds0和ds1,他们分别对应一开始创建的两个数据库。
server:
port: 8090
spring:
datasource:
type-aliases-package: com.teamo.shardingsphere.mapper
mapper-locations: classpath:/mapper/*.xml
ds0:
url: jdbc:mysql://localhost:3306/shardingsphere?useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password:
driver-class-name: com.mysql.jdbc.Driver
initialSize: 2 #初始化大小
maxWait: 6000 #获取连接时最大等待时间,单位毫秒。
min-idle: 5 # 数据库连接池的最小维持连接数
maxActive: 20 # 最大的连接数
initial-size: 5 # 初始化提供的连接数
max-wait-millis: 200 # 等待连接获取的最大超时时间
type: com.alibaba.druid.pool.DruidDataSource
ds1:
url: jdbc:mysql://localhost:3307/shardingsphere?useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password:
driver-class-name: com.mysql.jdbc.Driver
initialSize: 2 #初始化大小
maxWait: 6000 #获取连接时最大等待时间,单位毫秒。
min-idle: 5 # 数据库连接池的最小维持连接数
maxActive: 20 # 最大的连接数
initial-size: 5 # 初始化提供的连接数
max-wait-millis: 200 # 等待连接获取的最大超时时间
type: com.alibaba.druid.pool.DruidDataSource
mybatis:
configuration:
map-underscore-to-camel-case: true
type-aliases-package: com.teamo.shardingsphere.model
mapper-locations: classpath:mapper/*.xml
3、创建shardingSphere的数据源配置类DataSourceConfig.java
特别需要关注的是方法userRuleConfig,该方法是对t_user表设置分库分表规则。
3.1、t_user表共创建了四张表分别是ds0_t_user0,ds0_t_user1,ds1_t_user0,ds1_t_user1。
tableRuleConfig.setActualDataNodes(“ds0.t_user_0,ds0.t_user_1,ds1.t_user_0,ds1.t_user_1”);
3.2、t_user表以主键user_id为分库键和分表键
//设置t_user分库规则
tableRuleConfig.setDatabaseShardingStrategyConfig(
new StandardShardingStrategyConfiguration(“user_id”, new DatabaseShardingAlgorithm()));
//设置t_user分表规则
tableRuleConfig.setTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration(“user_id”, new IdCommonShardingAlgorithm()));
其中类DatabaseShardingAlgorithm是分库类, 类IdCommonShardingAlgorithm是分表类,它们都实现PreciseShardingAlgorithm接口,并在接口方法中实现对应的分库分表逻辑,具体内容请看查看这两个类具体内容。
package com.teamo.shardingsphere.config;
import com.alibaba.druid.filter.Filter;
import com.alibaba.druid.filter.stat.StatFilter;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.teamo.shardingsphere.dbstrategy.DatabaseShardingAlgorithm;
import com.teamo.shardingsphere.dbstrategy.GenderTableShardingAlgorithm;
import com.teamo.shardingsphere.dbstrategy.IdCommonShardingAlgorithm;
import io.shardingsphere.api.config.rule.ShardingRuleConfiguration;
import io.shardingsphere.api.config.rule.TableRuleConfiguration;
import io.shardingsphere.api.config.strategy.InlineShardingStrategyConfiguration;
import io.shardingsphere.api.config.strategy.StandardShardingStrategyConfiguration;
import io.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import lombok.Data;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ConcurrentHashMap;
/***
* @author teamo
* @date 2022-03-18
*/
@Configuration
@Data
public class DataSourceConfig {
@Value("${spring.datasource.type-aliases-package}")
private String typeAliasesPackage;
@Value("${spring.datasource.mapper-locations}")
private String mapperLocation;
@Value("${spring.datasource.ds0.url}")
private String url0;
@Value("${spring.datasource.ds0.username}")
private String userName0;
@Value("${spring.datasource.ds0.password}")
private String password0;
@Value("${spring.datasource.ds0.driver-class-name}")
private String driverClassName0;
@Value("${spring.datasource.ds0.type}")
private String dsType0;
@Value("${spring.datasource.ds1.url}")
private String url1;
@Value("${spring.datasource.ds1.username}")
private String userName1;
@Value("${spring.datasource.ds1.password}")
private String password1;
@Value("${spring.datasource.ds1.driver-class-name}")
private String driverClassName1;
@Value("${spring.datasource.ds1.type}")
private String dsType1;
/**
* 获取数据源Map
*/
private Map<String, DataSource> getDatasourceMap() {
// 真实数据源map
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>(2);
// 配置第一个数据源
DruidDataSource dataSource0 = new DruidDataSource();
dataSource0.setDriverClassName(driverClassName0);
dataSource0.setUrl(url0);
dataSource0.setUsername(userName0);
dataSource0.setPassword(password0);
dataSource0.setMinIdle(5);
dataSource0.setMaxActive(20);
dataSource0.setInitialSize(5);
dataSource0.setMaxWait(6000);
dataSourceMap.put("ds0", dataSource0);
// 配置第二个数据源
DruidDataSource dataSource1 = new DruidDataSource();
dataSource1.setDriverClassName(driverClassName1);
dataSource1.setUrl(url1);
dataSource1.setUsername(userName1);
dataSource1.setPassword(password1);
dataSource1.setMinIdle(5);
dataSource1.setMaxActive(20);
dataSource1.setInitialSize(5);
dataSource1.setMaxWait(6000);
dataSourceMap.put("ds1", dataSource1);
return dataSourceMap;
}
@Bean
public Filter statFilter() {
StatFilter filter = new StatFilter();
filter.setSlowSqlMillis(5000);
filter.setLogSlowSql(true);
filter.setMergeSql(true);
return filter;
}
@Bean
public ServletRegistrationBean statViewServlet() {
//创建servlet注册实体
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
//设置ip白名单
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
//设置控制台管理用户
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
//是否可以重置数据
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
/****
* sharding-jdbc-core(3.1.0)
* @return
* @throws SQLException
*/
@Bean("dataSource")
@Primary
public DataSource dataSource() throws SQLException {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = getDatasourceMap();
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 设置全局默认库
//fshardingRuleConfig.setDefaultDataSourceName("ds0");
shardingRuleConfig.getTableRuleConfigs().add(userRuleConfig());
//设置默认数据源分片策略
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", new IdCommonShardingAlgorithm()));
Properties p = new Properties();
p.setProperty("sql.show",Boolean.TRUE.toString());
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), p);
return dataSource;
}
/**
* 需要手动配置事务管理器
* @param dataSource
* @return
*/
@Bean
public DataSourceTransactionManager transactitonManager(@Qualifier("dataSource") DataSource dataSource){
return new DataSourceTransactionManager(dataSource);
}
@Bean("sqlSessionFactory")
@Primary
public SqlSessionFactory sqlSessionFactory(@Qualifier("dataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return bean.getObject();
}
@Bean("sqlSessionTemplate")
@Primary
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("sqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
private TableRuleConfiguration userRuleConfig() {
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration();
tableRuleConfig.setLogicTable("t_user");
tableRuleConfig.setActualDataNodes("ds0.t_user_0,ds0.t_user_1,ds1.t_user_0,ds1.t_user_1");
tableRuleConfig.setKeyGeneratorColumnName("user_id");
tableRuleConfig.setDatabaseShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_id", new DatabaseShardingAlgorithm()));
tableRuleConfig.setTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("user_id", new IdCommonShardingAlgorithm()));
return tableRuleConfig;
}
}
4、表t_user分库规则类DatabaseShardingAlgorithm
分库逻辑就是主键user_id的值进行余2的值来判断数据库的选择
例如当前插入一条数据,主键user_id值为3,那么(3%2==1)则数据库选择db1
package com.teamo.shardingsphere.dbstrategy;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
/**
* 数据源分片策略
* @author teamo
* @date 2022/3/18
*/
public class DatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames,
PreciseShardingValue<Long> shardingValue) {
long res = 0 ;
for (String each : availableTargetNames) {
res = shardingValue.getValue() ;
res = res % 2;
if (each.endsWith(res + "")) {
return each;
}
}
throw new UnsupportedOperationException();
}
}
5、表t_user分表规则IdCommonShardingAlgorithm
分表逻辑是取t_user表主键user_id的值,user_id的长度为len,取0到len-1位之间进行求和,用求和的值%2得到的值来确定选择那张表
例1:当前插入一条数据,user_id的值为11,则user_id的长度为2,0-1之间的数字只有一位为1,则1%2=1,所以选择的库为t_user1
例2:当前插入一条数据,user_id的值为131,则user_id的长度为3,0-2之间的数字为1和3,则(1+3)%2=0,所以选择的库为t_user0
package com.teamo.shardingsphere.dbstrategy;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
public class IdCommonShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String target = availableTargetNames.stream().findFirst().get();
for (String tableName : availableTargetNames) {
if (tableName.endsWith(idToTableSuffix(shardingValue.getValue()))) {
target = tableName;
}
}
return target;
}
private String idToTableSuffix(Long id) {
String idStr = String.valueOf(id);
int total = 0;
for(int i=0;i <idStr.length()-1; i++){
Integer num = Integer.parseInt(idStr.substring(i,i+1));
total+=num;
}
return String.valueOf(total % 2);
}
}
6、Model类
package com.teamo.shardingsphere.model;
import java.io.Serializable;
import java.util.Date;
public class User implements Serializable {
private Long userId;
private String idNumber;
private String name;
private Integer age;
private Integer gender;
private Date birthDate;
private static final long serialVersionUID = 1L;
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getIdNumber() {
return idNumber;
}
public void setIdNumber(String idNumber) {
this.idNumber = idNumber == null ? null : idNumber.trim();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name == null ? null : name.trim();
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
public Date getBirthDate() {
return birthDate;
}
public void setBirthDate(Date birthDate) {
this.birthDate = birthDate;
}
}
7、Dao类
package com.teamo.shardingsphere.mapper;
import com.teamo.shardingsphere.model.User;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Component;
import java.util.List;
@Mapper
@Component
public interface UserMapper {
int deleteByPrimaryKey(Long userId);
int insert(User record);
int insertSelective(User record);
User selectByPrimaryKey(Long userId);
int updateByPrimaryKeySelective(User record);
int updateByPrimaryKey(User record);
List<User> selectAll(int start, int limit);
}
8、mapper配置文件(.xml文件)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.teamo.shardingsphere.mapper.UserMapper">
<resultMap id="BaseResultMap" type="com.teamo.shardingsphere.model.User">
<id column="user_id" jdbcType="BIGINT" property="userId" />
<result column="id_number" jdbcType="VARCHAR" property="idNumber" />
<result column="name" jdbcType="VARCHAR" property="name" />
<result column="age" jdbcType="INTEGER" property="age" />
<result column="gender" jdbcType="INTEGER" property="gender" />
<result column="birth_date" jdbcType="DATE" property="birthDate" />
</resultMap>
<sql id="Base_Column_List">
user_id, id_number, name, age, gender, birth_date
</sql>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from t_user
where user_id = #{userId,jdbcType=BIGINT}
</select>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete from t_user
where user_id = #{userId,jdbcType=BIGINT}
</delete>
<insert id="insert" parameterType="com.teamo.shardingsphere.model.User">
insert into t_user (user_id, id_number, name,
age, gender, birth_date
)
values (#{userId,jdbcType=BIGINT}, #{idNumber,jdbcType=VARCHAR}, #{name,jdbcType=VARCHAR},
#{age,jdbcType=INTEGER}, #{gender,jdbcType=INTEGER}, #{birthDate,jdbcType=DATE}
)
</insert>
<insert id="insertSelective" parameterType="com.teamo.shardingsphere.model.User" useGeneratedKeys="true" keyProperty="userId">
insert into t_user
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="userId != null">
user_id,
</if>
<if test="idNumber != null">
id_number,
</if>
<if test="name != null">
name,
</if>
<if test="age != null">
age,
</if>
<if test="gender != null">
gender,
</if>
<if test="birthDate != null">
birth_date,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="userId != null">
#{userId,jdbcType=BIGINT},
</if>
<if test="idNumber != null">
#{idNumber,jdbcType=VARCHAR},
</if>
<if test="name != null">
#{name,jdbcType=VARCHAR},
</if>
<if test="age != null">
#{age,jdbcType=INTEGER},
</if>
<if test="gender != null">
#{gender,jdbcType=INTEGER},
</if>
<if test="birthDate != null">
#{birthDate,jdbcType=DATE},
</if>
</trim>
</insert>
<update id="updateByPrimaryKeySelective" parameterType="com.teamo.shardingsphere.model.User">
update t_user
<set>
<if test="idNumber != null">
id_number = #{idNumber,jdbcType=VARCHAR},
</if>
<if test="name != null">
name = #{name,jdbcType=VARCHAR},
</if>
<if test="age != null">
age = #{age,jdbcType=INTEGER},
</if>
<if test="gender != null">
gender = #{gender,jdbcType=INTEGER},
</if>
<if test="birthDate != null">
birth_date = #{birthDate,jdbcType=DATE},
</if>
</set>
where user_id = #{userId,jdbcType=BIGINT}
</update>
<update id="updateByPrimaryKey" parameterType="com.teamo.shardingsphere.model.User">
update t_user
set id_number = #{idNumber,jdbcType=VARCHAR},
name = #{name,jdbcType=VARCHAR},
age = #{age,jdbcType=INTEGER},
gender = #{gender,jdbcType=INTEGER},
birth_date = #{birthDate,jdbcType=DATE}
where user_id = #{userId,jdbcType=BIGINT}
</update>
<select id="selectAll" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from t_user
order by user_id
limit #{start}, #{limit}
</select>
</mapper>
9、Service类
此处是demo示例,没有严格按照接口实现类的方式
package com.teamo.shardingsphere.Service;
import com.teamo.shardingsphere.mapper.*;
import com.teamo.shardingsphere.model.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class BussinessService {
@Autowired
private UserMapper userMapper;
@Transactional
public void saveUser(User user) {
userMapper.insertSelective(user);
}
public List<User> selectAllUser(int start, int limit ){
return userMapper.selectAll(start, limit);
}
}
10、Controller类
Controller类就写了两个方法,一个是写入t_user表数据的方法(用for循环写入40条及记录),一个是查询t_user表并进行分页的方法,目的就是检测t_user表写入数据和读取数据的时候是否按照我们设置的分库分表规则进行操作。
package com.teamo.shardingsphere.controller;
import cn.hutool.core.date.DateUtil;
import com.teamo.shardingsphere.Service.BussinessService;
import com.teamo.shardingsphere.model.*;
import com.teamo.shardingsphere.util.SnowflakeKeyGenerator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.propertyeditors.CustomDateEditor;
import org.springframework.web.bind.WebDataBinder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@RestController
public class BussinessController {
@Autowired
private BussinessService bussinessService;
@GetMapping("/buss/create")
public String create() {
for (int i = 1; i <= 40; i++) {
User user = new User();
//user.setUserId(snowflakeKeyGenerator.nextId());
user.setUserId(Long.parseLong((i)+""));
user.setName("王小晖" + i);
user.setGender(GenderEnum.MALE.getCode());
user.setAge(20 + i);
user.setBirthDate(DateUtil.parseDate("1989-08-16"));
user.setIdNumber("4101231989691" + i);
bussinessService.saveUser(user);
}
return "成功";
}
@GetMapping("/buss/allUser")
public List<User> findAllUser(int start, int limit){
return bussinessService.selectAllUser(start, limit);
}
}
11、SpringBoot的启动类
package com.teamo.shardingsphere;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
@SpringBootApplication(exclude={DataSourceAutoConfiguration.class})
public class ShardingsphereApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingsphereApplication.class, args);
}
}
到此,整个demo系统编写完成
三、运行测试
1、启动系统
右键点击启动类启动demo系统
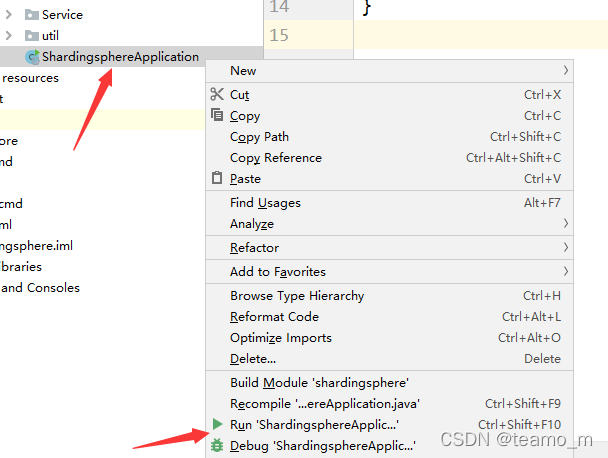
2、数据插入测试
待系统启动成功后打开浏览器,在地址栏上输入http://localhost:9090/buss/create,当页面显示成功之后标识插入t_user表数据的方法执行成功。

然后登录数据库,查看输入插入库表的情况
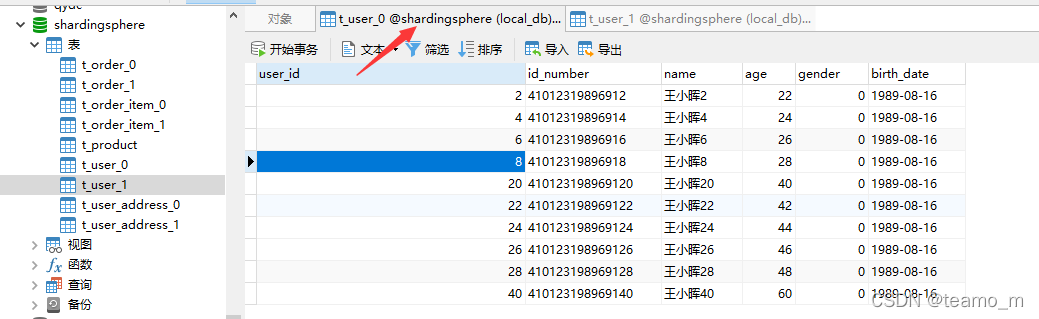
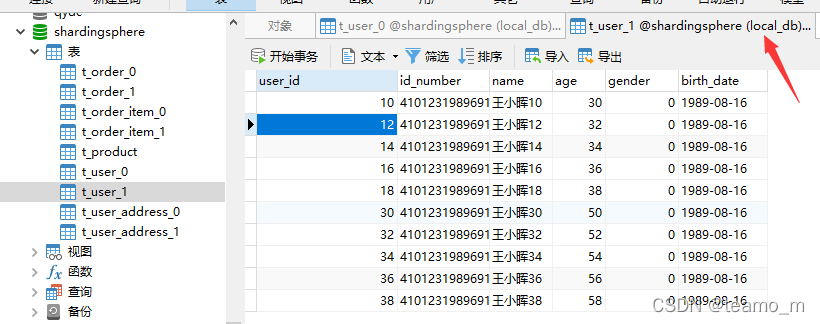
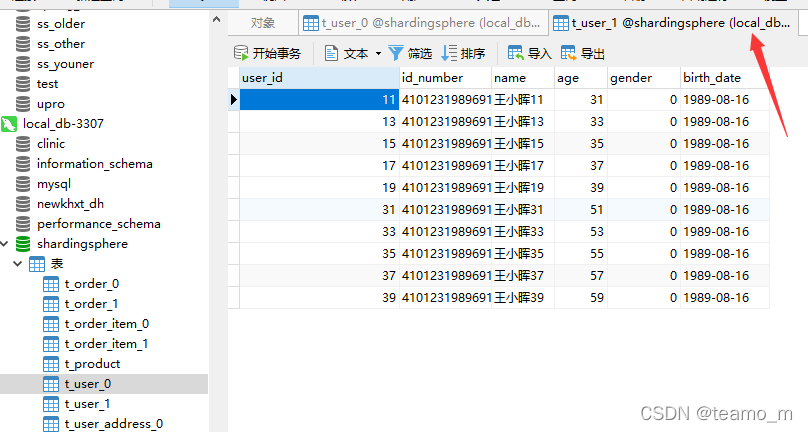
ds0库: 抽取ds0库的t_user0和t_user1表的第3条记录进行分库分表逻辑校验
t_user0第3条记录的user_id=6
分库规则user_id的值%2==0,所以分库到ds0
分表规则user_id值长度为1,0到(1-1)之间没有数字,即为0,所以分表到t_user0
因此user_id=6的记录将被插入的ds0库,t_user0表中,校验正确
t_user1第3条记录的user_id=14
分库规则user_id的值%2==0,所以分库到ds0
分表规则user_id值长度为2,[0到(2-1))之间为1,按长度求和为1,所以分表到t_user1
因此user_id=6的记录将被插入的ds0库,t_user1表中,校验正确
ds1库
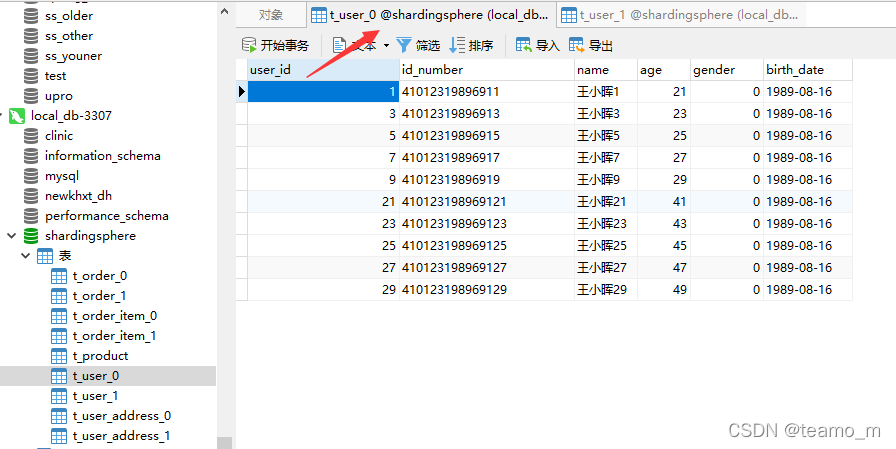
ds1库: 抽取ds0库的t_user0和t_user1表的第5条记录进行分库分表逻辑校验
t_user0第5条记录的user_id=9
分库规则user_id的值%2==1,所以分库到ds1
分表规则user_id值长度为1,0到(1-1)之间没有数字,即为0,所以分表到t_user0
因此user_id=6的记录将被插入的ds1库,t_user0表中,校验正确
t_user1第5条记录的user_id=19
分库规则user_id的值%2==1,所以分库到ds1
分表规则user_id值长度为2,[0到(2-1))之间为1,按长度求和为1,所以分表到t_user1
因此user_id=6的记录将被插入的ds1库,t_user1表中,校验正确
3、数据查询测试
在浏览器中输入http://localhost:9090/buss/allUser?start=0&limit=5
 查看后台打印sql日志,系统经过ShardingSphere的规则解析后向数据库真实发出的sql是
查看后台打印sql日志,系统经过ShardingSphere的规则解析后向数据库真实发出的sql是

由此可见,经过ShardingSphere进行分库分表配置操作之后,系统单表查询的数据来源将有配置过的所有库表(此例是两个库四张表)进行获取。
四、总结
当我们们在一开始规划系统的时候,如果有预见系统可能存在大数据存储量导致性能风险或者系统在运维过程中发现某个业务的某个表数据量太大导致性能问题等情况就可以考虑采用ShardingSphere。高效率使用ShardingSphere的关键就是对分库分表规则的确定和设置,这些规则的确定需要根据对该表的查询业务的逻辑来确定。只有一个好的规则设置才能让它体现出它的优势。分库分表键的最优规则是将对应数据按业务进行拆分到不同的表中,比如按单位进行拆分(前提是业务都是在相同单位中进行,单位交叉的业务比较少),这样才会起到我们希望的效果。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)