Springboot+爬虫+推荐算法+前后端分离实现小说推荐系统
如何针对互联网各大小说阅读网站的小说数据进行实时采集更新,建立自己的小说资源库,针对海量的小说数据开展标签处理特征分析,利用推荐算法完成针对用户的个性化阅读推荐?基于以上问题,本次小说推荐系统,建设过程主要分为小说推荐网站前端系统,小说运维管理后台系统,小说数据实时采集爬虫三个部分。小说推荐网站前端系统主要采用开源前端框架搭建小说推荐网站,提供用户登录注册,小说阅读等功能,小说运维管理后台,提供管
如何针对互联网各大小说阅读网站的小说数据进行实时采集更新,建立自己的小说资源库,针对海量的小说数据开展标签处理特征分析,利用推荐算法完成针对用户的个性化阅读推荐?
基于以上问题,本次小说推荐系统,建设过程主要分为小说推荐网站前端系统,小说运维管理后台系统,小说数据实时采集爬虫三个部分。小说推荐网站前端系统主要采用开源前端框架搭建小说推荐网站,提供用户登录注册,小说阅读等功能,小说运维管理后台,提供管理员用户使用完成系统内部小说,用户等数据的管理,小说数据采集爬虫支持各大小说阅读网站的内容采集及更新。
一、程序设计
本次小说推荐系统主要内容涉及:
主要功能模块:小说推荐网站前台,系统管理后台,小说爬虫采集平台
主要包含技术:springboot,mybatis,mysql,javascript,vue.js,html,css,Jsoup,httpclient
主要包含算法:基于用户协同过滤推荐,余弦相似度,Kmeans聚类分析,内容标签计算
系统采用前后端分离的开发模式完成,系统前端主要采用Vue.js,javascript,html,CSS等技术实现。系统后端框架采用springboot+mybatis+mysql数据库搭建,针对海量的小说数据采用分表操作,完成数据存储分析。系统前后端数据交互,采用Ajax异步调用传输JSON实现。
二、效果实现
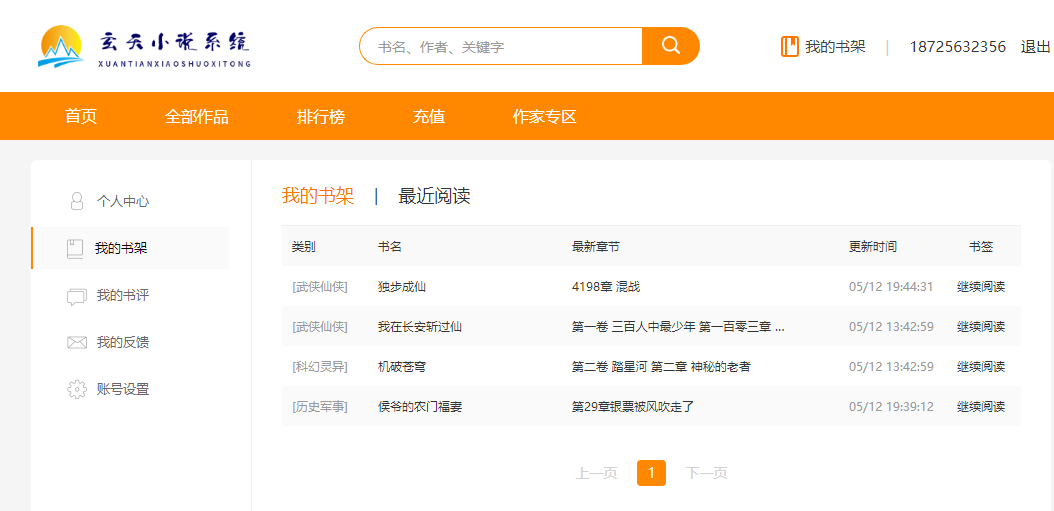
网站登录
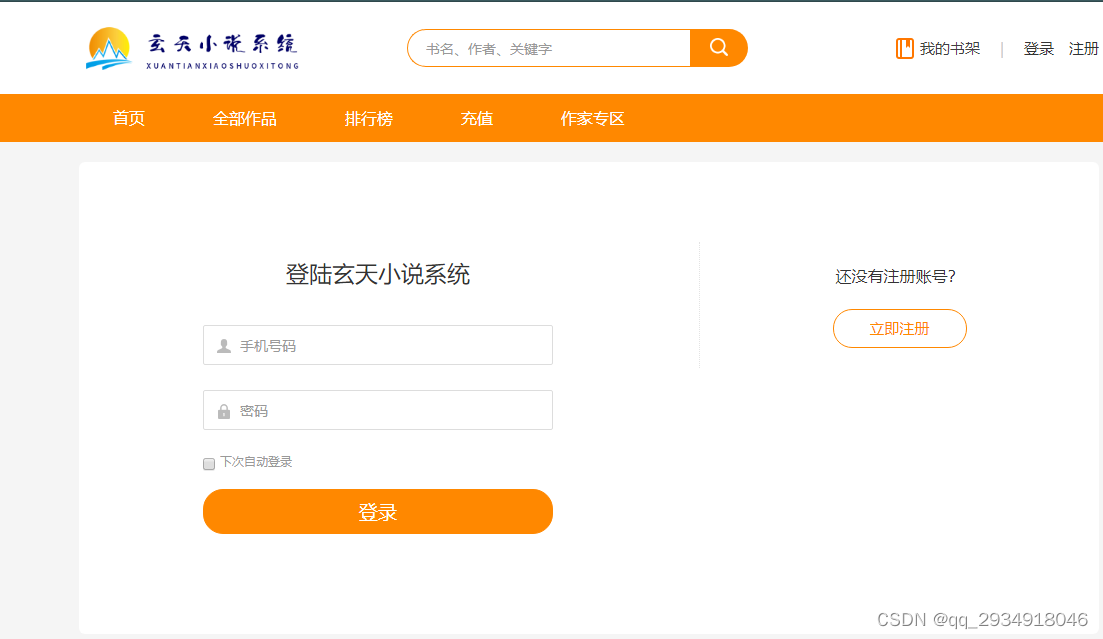
系统主页
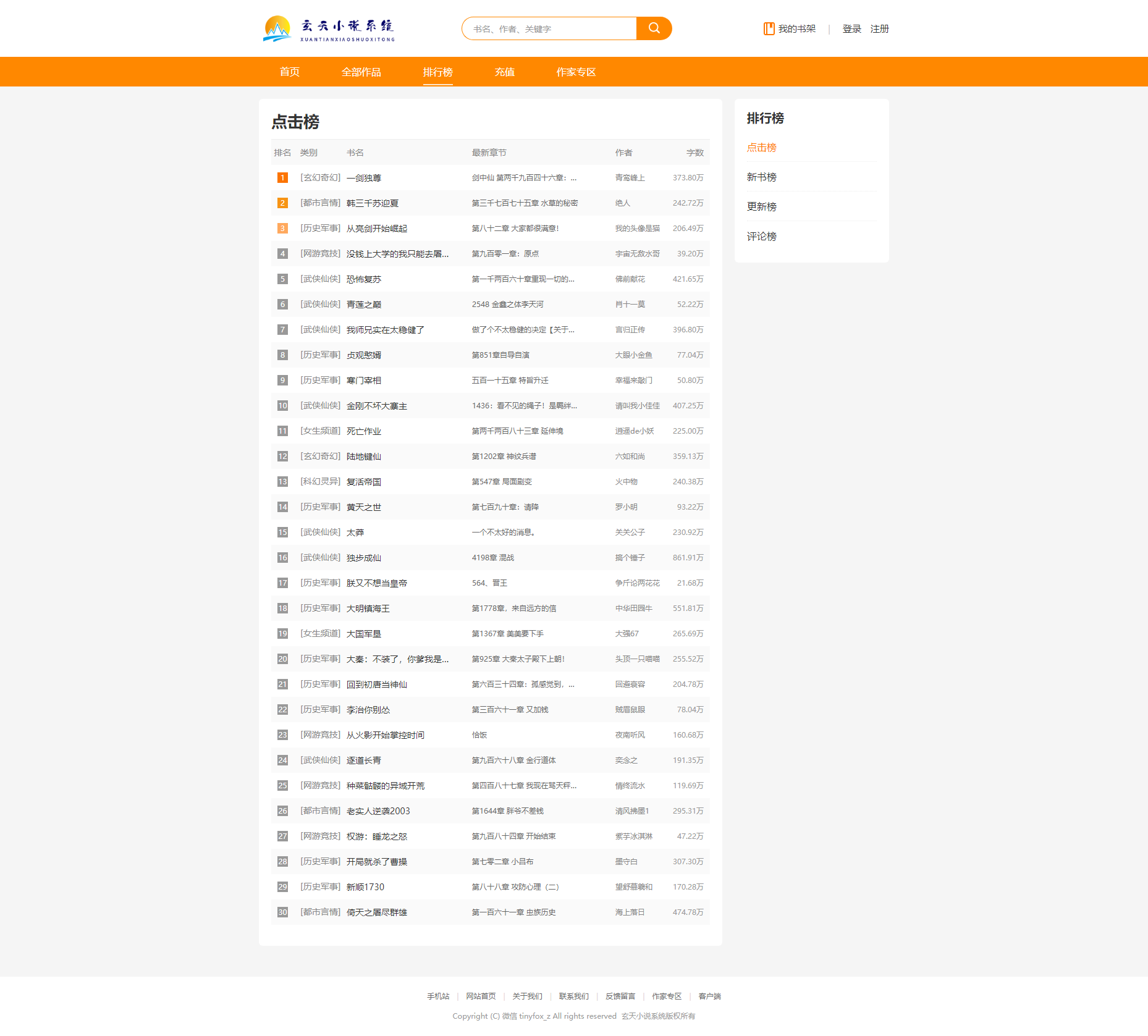
排行榜
全部作品
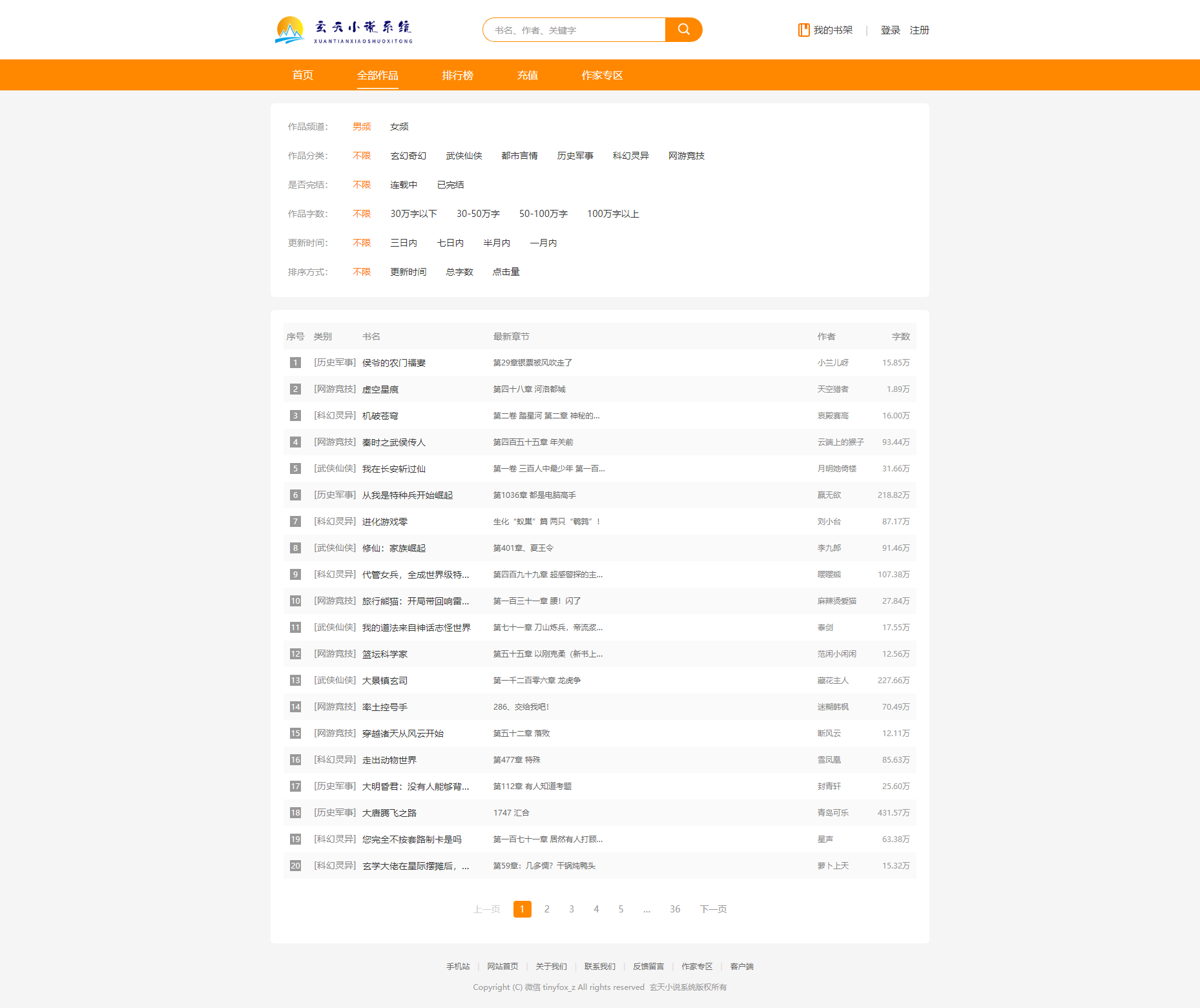
全部章节
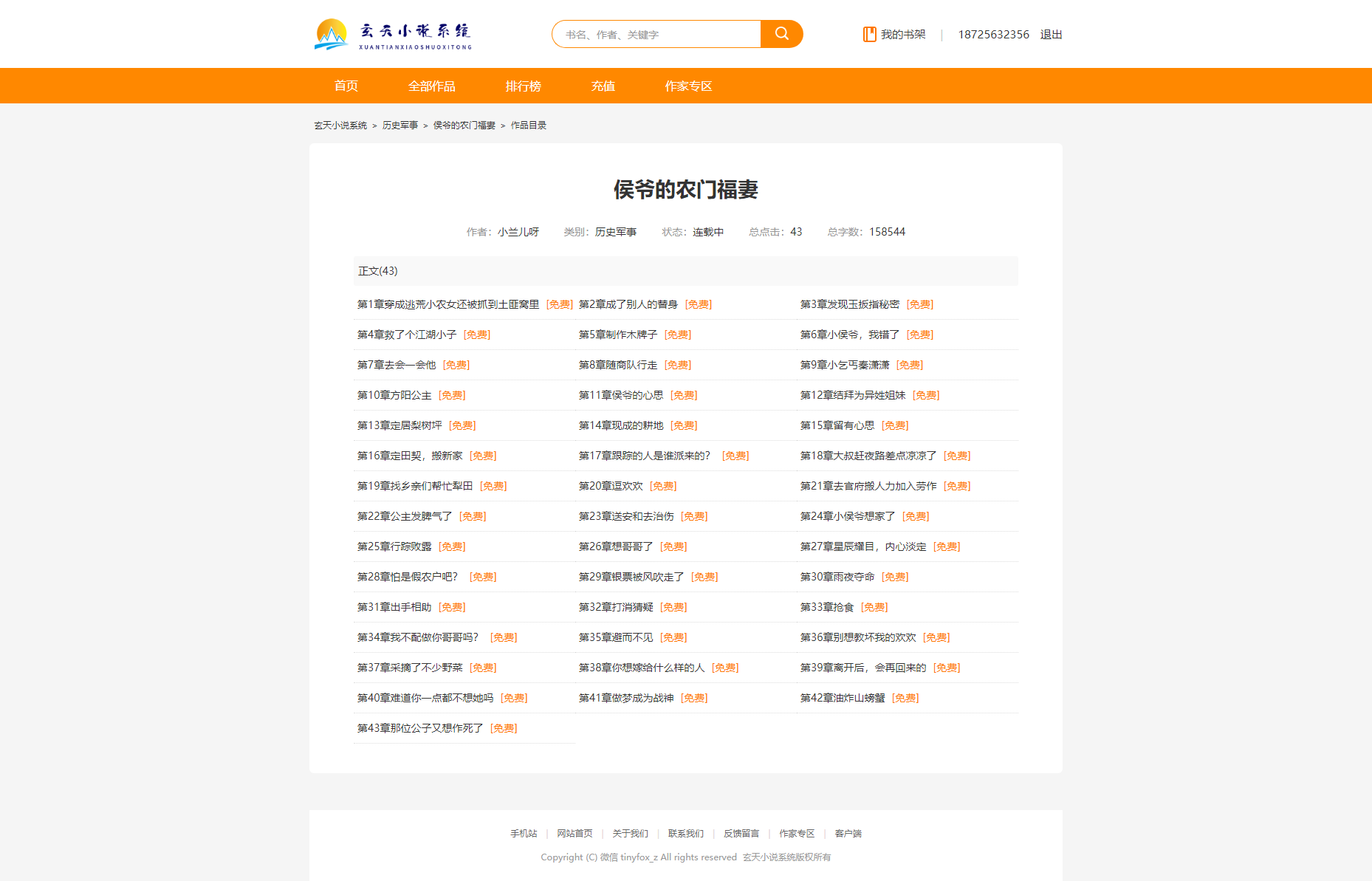
章节阅读
![![其他][5]](https://img-blog.csdnimg.cn/3b15530e480b4fcc9371a021635a35cc.png)
个人中心
后台管理

爬虫配置
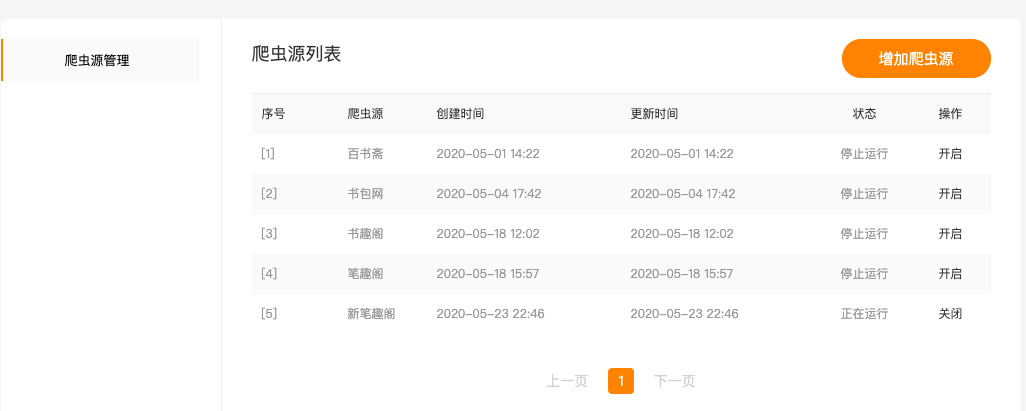
其他效果省略
三、小说爬虫设计
采集小说页面
采用HttpClinet构造http请求,获取第三方小说资源地址,解析网页小说内容
java实现请求代码
private static String getByHttpClient(String url) {
try {
ResponseEntity<String> forEntity = restTemplate.getForEntity(url, String.class);
if (forEntity.getStatusCode() == HttpStatus.OK) {
String body = forEntity.getBody();
assert body != null;
if (body.length() < Constants.INVALID_HTML_LENGTH) {
return processErrorHttpResult(url);
}
//成功获得html内容
return body;
}
} catch (Exception e) {
e.printStackTrace();
}
return processErrorHttpResult(url);
}
监听采集任务
采用spring-quartz实现定时任务监听,小说采集爬虫的运行过程,任务状态设置为停止、运行、失败、成功四种。
java监听实现
//查询需要监控的正在运行的爬虫源
List<CrawlSource> sources = crawlService.queryCrawlSourceByStatus((byte) 1);
for (CrawlSource source : sources) {
Set<Long> runningCrawlThreadIds = (Set<Long>)cacheService.getObject(CacheKey.RUNNING_CRAWL_THREAD_KEY_PREFIX + source.getId());
boolean sourceStop = true;
if (runningCrawlThreadIds != null) {
for (Long threadId : runningCrawlThreadIds) {
Thread thread = ThreadUtil.findThread(threadId);
if (thread != null && thread.isAlive()) {
//有活跃线程,说明该爬虫源正在运行,数据库中状态正确,不需要修改
sourceStop = false;
}
}
}
if (sourceStop) {
crawlService.updateCrawlSourceStatus(source.getId(), (byte) 0);
}


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)