线程池的经典应用场景
在日常的开发工作中,我们经常会需要使用到线程池这类型的组件。例如下边几种应用场景:线程池经典应用场景异步发送邮件通知发送一个任务,然后注入到线程池中异步发送。心跳请求任务创建一个任务,然后定时发送请求到线程池中。类似的场景有很多,我们下边一步一步地来介绍不同的应用场景下,线程池的具体使用案例:异步发送邮件场景定义一个简单的邮件发送接口:public interface SendEmailServi
在日常的开发工作中,我们经常会需要使用到线程池这类型的组件。例如下边几种应用场景:
线程池经典应用场景
异步发送邮件通知
发送一个任务,然后注入到线程池中异步发送。
心跳请求任务
创建一个任务,然后定时发送请求到线程池中。
类似的场景有很多,我们下边一步一步地来介绍不同的应用场景下,线程池的具体使用案例:
异步发送邮件场景
定义一个简单的邮件发送接口:
public interface SendEmailService {
/**
* 发送邮件
*
* @param emailDTO 邮件对象
*/
void sendEmail(EmailDTO emailDTO);
}
接着是邮件发送的简单实现类:
@Service
public class SendEmailServiceImpl implements SendEmailService {
@Resource
private ExecutorService emailTaskPool;
@Override
public void sendEmail(EmailDTO emailDTO) {
emailTaskPool.submit(() -> {
try {
System.out.printf("sending email .... emailDto is %s \n", emailDTO);
Thread.sleep(1000);
System.out.println("sended success");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
邮件的发送逻辑通过一个简单的线程睡眠来模拟发送过程中的耗时操作。
然后是线程池方面的配置:
@Configuration
public class ThreadPoolConfig {
@Bean
public ExecutorService emailTaskPool() {
return new ThreadPoolExecutor(2, 4,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(), new SysThreadFactory("email-task"));
}
}
controller模块的触发
@RestController
@RequestMapping(value = "/test")
public class TestController {
@Resource
private SendEmailService sendEmailService;
@GetMapping(value = "/send-email")
public boolean sendEmail() {
EmailDTO emailDTO = new EmailDTO();
emailDTO.setContent("测试文案");
emailDTO.setReceiver("idea");
emailDTO.setTitle("邮件标题");
sendEmailService.sendEmail(emailDTO);
return true;
}
}
这是一个非常简单的案例,通过一个http请求,然后触发一个邮件的发送操作。
心跳请求场景
这类应用场景一般会在一些基础组件中使用到,例如一些具有心跳探活机制类型功能的中间件,如nacos。下边来看看对应的代码实践:
首先是心跳模块代码:
public class HeartBeatInfo {
private String info;
private long nextSendTimeDelay;
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
public long getNextSendTimeDelay() {
return nextSendTimeDelay;
}
public void setNextSendTimeDelay(long nextSendTimeDelay) {
this.nextSendTimeDelay = nextSendTimeDelay;
}
@Override
public String toString() {
return "HeartBeatInfo{" +
"info='" + info + '\'' +
", nextSendTimeDelay=" + nextSendTimeDelay +
'}';
}
}
然后是模拟一个心跳包的发送服务接口定义:
public interface HeartBeatTaskService {
void sendBeatInfo();
}
接下来是心跳任务的发送核心部分实现:
@Service
public class HeartBeatTaskServiceImpl implements HeartBeatTaskService {
@Resource
private ScheduledThreadPoolExecutor scheduledThreadPoolExecutor;
@Override
public void sendBeatInfo() {
HeartBeatInfo heartBeatInfo = new HeartBeatInfo();
heartBeatInfo.setInfo("test-info");
heartBeatInfo.setNextSendTimeDelay(1000);
scheduledThreadPoolExecutor.schedule(new HeartBeatTask(heartBeatInfo),
heartBeatInfo.getNextSendTimeDelay(), TimeUnit.MILLISECONDS);
}
class HeartBeatTask implements Runnable {
private HeartBeatInfo heartBeatInfo;
public HeartBeatTask(HeartBeatInfo heartBeatInfo) {
this.heartBeatInfo = heartBeatInfo;
}
@Override
public void run() {
System.out.println("发送心跳数据包:" + heartBeatInfo.getInfo());
HeartBeatInfo heartBeatInfo = new HeartBeatInfo();
heartBeatInfo.setInfo("test-info");
heartBeatInfo.setNextSendTimeDelay(1000);
scheduledThreadPoolExecutor.schedule(new HeartBeatTask(heartBeatInfo),
heartBeatInfo.getNextSendTimeDelay(), TimeUnit.MILLISECONDS);
}
}
}
在核心实现的内部有一个延时线程池ScheduledThreadPoolExecutor,ScheduledThreadPoolExecutor会在放入线程任务的一段指定的时间之后才触发任务的执行:
@Configuration
public class ThreadPoolConfig {
@Bean
public ScheduledThreadPoolExecutor scheduledThreadPoolExecutor(){
return new ScheduledThreadPoolExecutor(2, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("org.idea.threadpool.beat.sender");
return thread;
}
});
}
}
JDK内部线程池的设计
看了上边两个简单的案例之后,不知道你是否会有好奇:
到底线程池的内部运行机制会是怎样的呢?
简单手写一个单消费者任务处理模型
这里我们可以通过一段简单的代码来学习这部分的内容:
首先,我们将需要处理的任务封装在一个对象内部,暂时定义如下所示:
public class AsyncHandlerData {
private String dataInfo;
public String getDataInfo() {
return dataInfo;
}
public void setDataInfo(String dataInfo) {
this.dataInfo = dataInfo;
}
@Override
public String toString() {
return "AsyncHandlerData{" +
"dataInfo='" + dataInfo + '\'' +
'}';
}
}
然后会有一个专门消费这些个任务的service:
public interface AsyncHandlerService {
/**
* 任务放入队列中
*
* @param asyncHandlerData
*/
void putTask(AsyncHandlerData asyncHandlerData);
}
最后根据提前定义好的接口编写一个实现类,此时将相关的任务处理逻辑规整到了一个对象当中:
@Service
public class AsyncHandlerServiceImpl implements AsyncHandlerService, CommandLineRunner {
private volatile TaskQueueHandler taskQueueHandler = new TaskQueueHandler();
@Override
public void putTask(AsyncHandlerData asyncHandlerData) {
taskQueueHandler.addTask(asyncHandlerData);
}
@Override
public void run(String... args) throws Exception {
Thread thread = new Thread(taskQueueHandler);
thread.setDaemon(true);
thread.start();
}
public class TaskQueueHandler implements Runnable {
private BlockingQueue<AsyncHandlerData> tasks = new ArrayBlockingQueue<>(1024 * 1024);
public void addTask(AsyncHandlerData asyncHandlerData) {
tasks.offer(asyncHandlerData);
}
@Override
public void run() {
for (; ; ) {
try {
AsyncHandlerData asyncHandlerData = tasks.take();
System.out.println("异步处理任务数据:" + asyncHandlerData.getDataInfo());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
整个代码的思路逻辑比较简单,大致可以归整成下图所示:
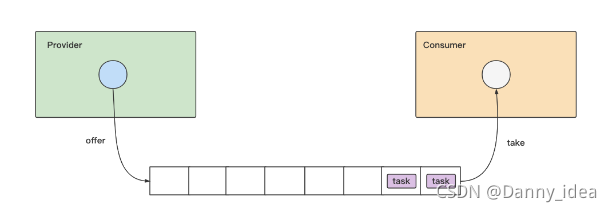
整体的设计模式就是一端放入,由单个消费者取出。但是存在一个不足点,一旦消费者能力较弱,或者出现任务堵塞的话,就会导致任务队列出现堆积,然后越堆积越难处理地过来。
但是这样的设计还是一个过于简单的模型,下边我们来看看jdk内部线程池的设计模式:
线程池内部的源代码分析
我们在项目里使用线程池的时候,通常都会先创建一个具体实现Bean来定义线程池,例如:
@Bean
public ExecutorService emailTaskPool() {
return new ThreadPoolExecutor(2, 4,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(), new SysThreadFactory("email-task"));
}
ThreadPoolExecutor的父类是AbstractExecutorService,然后AbstractExecutorService的顶层接口是:ExecutorService。
就例如发送邮件接口而言,当线程池触发了submit函数的时候,实际上会调用到父类AbstractExecutorService对象的java.util.concurrent.AbstractExecutorService#submit(java.lang.Runnable)方法,然后进入到ThreadPoolExecutor#execute部分。
@Override
public void sendEmail(EmailDTO emailDTO) {
emailTaskPool.submit(() -> {
try {
System.out.printf("sending email .... emailDto is %s \n", emailDTO);
Thread.sleep(1000);
System.out.println("sended success");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
java.util.concurrent.AbstractExecutorService#submit(java.lang.Runnable) 源代码位置:
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
这里面你会看到返回的是一个future对象供调用方判断线程池内部的函数到底是否有完全执行成功。因此如果有时候如果需要判断线程池执行任务的结果话,可以这样操作:
Future future = emailTaskPool.submit(() -> {
try {
System.out.printf("sending email .... emailDto is %s \n", emailDTO);
Thread.sleep(1000);
System.out.println("sended success");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//todo something
future.get();
}
在jdk8源代码中,提交任务的执行逻辑部分如下所示:
新增线程任务的时候代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
//工作线程数小于核心线程的时候,可以填写worker线程
if (workerCountOf(c) < corePoolSize) {
//新增工作线程的时候会加锁
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池的状态正常,切任务放入就绪队列正常
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
//如果当前线程池处于关闭状态,则抛出拒绝异常
reject(command);
//如果工作线程数超过了核心线程数,那么就需要考虑新增工作线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果新增的工作线程已经达到了最大线程数限制的条件下,需要触发拒绝策略的抛出
else if (!addWorker(command, false))
reject(command);
}
通过深入阅读工作线程主要存放在了一个hashset集合当中,
添加工作线程部分的逻辑代码如下所示:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//确保当前线程池没有进入到一个销毁状态中
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
// 如果传入的core属性是false,则这里需要比对maximumPoolSize参数
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过cas操作去增加线程池的工作线程数亩
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//真正需要指定的任务是firstTask,它会被注入到worker对象当中
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//加入了锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//workers是一个hashset集合,会往里面新增工作线程
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//worker本身是一个线程,但是worker对象内部还有一个线程的参数,
//这个t才是真正的任务内容
t.start();
workerStarted = true;
}
}
} finally {
//如果worker线程创建好了,但是内部的真正任务还没有启动,此时突然整个
//线程池的状态被关闭了,那么这时候workerStarted就会为false,然后将
//工作线程的数目做自减调整。
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
进过理解之后,整体执行的逻辑以及先后顺序如下图所示:
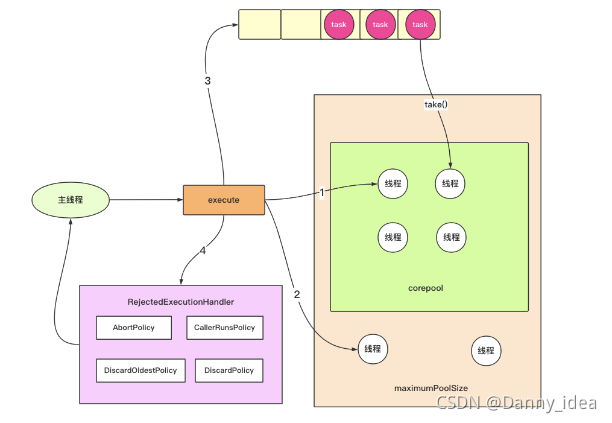
首先判断线程池内部的现场是否都有任务需要执行。如果不是,则使用一个空闲的工作线程用于任务执行。否则会判断当前的工作队列是否已经满了,如果没有满则往队列里面投递一个任务,等待线程去处理。如果工作队列已经满了,此时会根据饱和策略去判断,是否需要创建新的线程还是果断抛出异常等方式来进行处理。
线程池常用参数介绍
corePoolSize
核心线程数,当往线程池内部提交任务的时候,线程池会创建一个线程来执行任务。即使此时有空闲的工作线程能够处理当前任务,只要总的工作线程数小于corePoolSize,也会创建新的工作线程。
maximumPoolSize
当任务的堵塞队列满了之后,如果还有新的任务提交到线程池内部,此时倘若工作线程数小于maximumPoolSize,则会创建新的工作线程。
keepAliveTime
上边我们说到了工作线程Worker(java.util.concurrent.ThreadPoolExecutor.Worker),当工作线程处于空闲状态中,如果超过了keepAliveTime依然没有任务,那么就会销毁当前工作线程。
如果工作线程需要一直处于执行任务,每个任务的连续间隔都比较短,那么这个keepAliveTime
属性可以适当地调整大一些。
unit
keepAliveTime对应的时间单位
workQueue
工作队列,当工作线程数达到了核心线程数,那么此时新来的线程就会被放入到工作队列中。
线程池内部的工作队列全部都是继承自阻塞队列的接口,对于常用的阻塞队列类型为:
- ArrayBlockingQueue
- LinkedBlockingQueue
- SynchronousQueue
- PriorityBlockingQueue
RejectedExecutionHandler
JDK内部的线程拒绝策略包含了多种许多种,这里我罗列一些常见的拒绝策略给大家认识下:
- AbortPolicy
直接抛出异常 - CallerRunsPolicy
任务的执行由注入的线程自己执行 - DiscardOldestPolicy
直接抛弃掉堵塞队列中队列头部的任务,然后执行尝试将当前任务提交到堵塞队列中。 - DiscardPolicy
直接抛弃这个任务
从线程池设计中的一些启发
多消费队列的设计
场景应用:
业务上游提交任务,然后任务被放进一个堵塞队列中,接下来消费者需要从堵塞队列中提取元素,并且将它们转发到多个子队列中,各个子队列分别交给不同的子消费者处理数据。例如下图所示:
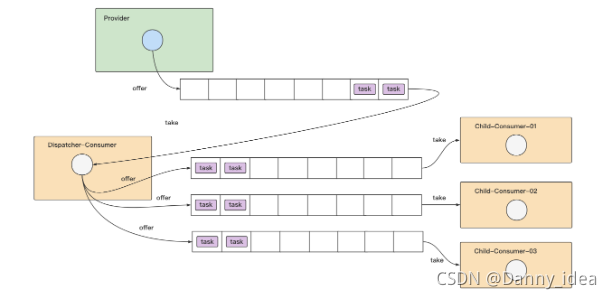
public interface AsyncHandlerService {
/**
* 任务放入队列中
*
* @param asyncHandlerData
*/
boolean putTask(AsyncHandlerData asyncHandlerData);
/**
* 启动消费
*/
void startJob();
}
多消费者分发处理实现类:
@Component("asyncMultiConsumerHandlerHandler")
public class AsyncMultiConsumerHandlerHandler implements AsyncHandlerService{
private volatile TaskQueueHandler taskQueueHandler = new TaskQueueHandler(10);
@Override
public boolean putTask(AsyncHandlerData asyncHandlerData) {
return taskQueueHandler.addTask(asyncHandlerData);
}
@Override
public void startJob(){
Thread thread = new Thread(taskQueueHandler);
thread.setDaemon(true);
thread.start();
}
/**
* 将任务分发给各个子队列去处理
*/
static class TaskQueueHandler implements Runnable {
private static BlockingQueue<AsyncHandlerData> tasks = new ArrayBlockingQueue<>(11);
public static BlockingQueue<AsyncHandlerData> getAllTaskInfo() {
return tasks;
}
private TaskDispatcherHandler[] taskDispatcherHandlers;
private int childConsumerSize = 0;
public TaskQueueHandler(int childConsumerSize) {
this.childConsumerSize = childConsumerSize;
taskDispatcherHandlers = new TaskDispatcherHandler[childConsumerSize];
for (int i = 0; i < taskDispatcherHandlers.length; i++) {
taskDispatcherHandlers[i] = new TaskDispatcherHandler(new ArrayBlockingQueue<>(100), "child-worker-" + i);
Thread thread = new Thread(taskDispatcherHandlers[i]);
thread.setDaemon(false);
thread.setName("taskQueueHandler-child-"+i);
thread.start();
}
}
public boolean addTask(AsyncHandlerData asyncHandlerData) {
return tasks.offer(asyncHandlerData);
}
@Override
public void run() {
int index = 0;
for (; ; ) {
try {
AsyncHandlerData asyncHandlerData = tasks.take();
index = (index == taskDispatcherHandlers.length) ? 0 : index;
taskDispatcherHandlers[index].addAsyncHandlerData(asyncHandlerData);
index++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class TaskDispatcherHandler implements Runnable {
private BlockingQueue<AsyncHandlerData> subTaskQueue;
private String childName;
private AtomicLong taskCount = new AtomicLong(0);
public TaskDispatcherHandler(BlockingQueue<AsyncHandlerData> blockingQueue, String childName) {
this.subTaskQueue = blockingQueue;
this.childName = childName;
}
public void addAsyncHandlerData(AsyncHandlerData asyncHandlerData) {
subTaskQueue.add(asyncHandlerData);
}
@Override
public void run() {
for (; ; ) {
try {
AsyncHandlerData asyncHandlerData = subTaskQueue.take();
long count = taskCount.incrementAndGet();
System.out.println("【" + childName + "】子任务队列处理:" + asyncHandlerData.getDataInfo() + count);
Thread.sleep(3000);
System.out.println("【" + childName + "】子任务队列处理:" + asyncHandlerData.getDataInfo()+" 任务处理结束" + count);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
测试接口:
@GetMapping(value = "/send-async-data")
public boolean sendAsyncData(){
AsyncHandlerData asyncHandlerData = new AsyncHandlerData();
asyncHandlerData.setDataInfo("data info");
boolean status = asyncMultiConsumerHandlerHandler.putTask(asyncHandlerData);
if(!status){
throw new RuntimeException("insert fail");
}
return status;
}
这种设计模型适合用于对于请求吞吐量要求较高,每个请求都比较耗时的场景中。
自定义拒绝策略的应用
根据具体的应用场景,通过实现java.util.concurrent.RejectedExecutionHandler接口,自定义拒绝策略,例如对于当抛出拒绝异常的时候,往数据库中记录一些信息或者日志。
相关案例代码:
public class MyRejectPolicy{
static class MyTask implements Runnable{
@Override
public void run() {
System.out.println("this is test");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS
, new LinkedBlockingQueue<>(10), Executors.defaultThreadFactory(), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("任务被拒绝:" + r.toString());
//记录一些信息
}
});
for(int i=0;i<100;i++){
Thread thread = new Thread(new MyTask());
threadPoolExecutor.execute(thread);
}
Thread.yield();
}
}
统计线程池的详细信息
通过阅读线程池的源代码之后,可以借助重写beforeExecute、afterExecute、terminated 方法去对线程池的每个线程耗时做统计。以及通过继承 ThreadPoolExecutor 对象之后,对当前线程池的coreSIze、maxiMumSize等等属性进行监控。
相关案例代码:
public class SysThreadPool extends ThreadPoolExecutor {
private final ThreadLocal<Long> startTime = new ThreadLocal<>();
private Logger logger = LoggerFactory.getLogger(SysThreadPool.class);
public SysThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public SysThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public SysThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public SysThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
startTime.set(System.currentTimeMillis());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
long endTime = System.currentTimeMillis();
long executeTime = endTime - startTime.get();
logger.info("Thread {}: ExecuteTime {}", r, executeTime);
}
@Override
public void shutdown() {
super.shutdown();
}
@Override
public void execute(Runnable command) {
super.execute(command);
}
public void getTaskInfo(){
logger.info("coreSize: {}, maxSize: {}, activeCount:{},blockQueueSize:{}",super.getCorePoolSize(),super.getMaximumPoolSize(),super.getActiveCount(),super.getQueue().size());
}
static class MyTestTask implements Runnable{
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
SysThreadPool sysThreadPool = new SysThreadPool(2,5,5000,TimeUnit.MILLISECONDS,new ArrayBlockingQueue(2));
sysThreadPool.getTaskInfo();
System.out.println("------------");
for(int i=0;i<10;i++){
Thread thread = new Thread(new MyTestTask());
sysThreadPool.submit(thread);
sysThreadPool.getTaskInfo();
}
System.out.println("------------");
Thread.sleep(3000);
}
}
通过日志打印记录线程池的参数变化:
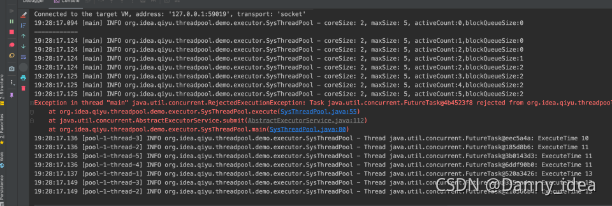
通过这份案例代码不妨可以设想下通过一些定时上报逻辑来实现线程池的监控功能。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)