Pandas删除缺失数据函数--dropna
在pandas中,dropna函数分别存在于DataFrame、Series和Index中,下面我们以DataFrame.dropna函数为例进行介绍,Series和Index中的参数意义同DataFrame中大致相同。DataFrame.dropna官方文档Series.dropna官方文档Index.dropna官方文档pandas.DataFrame.dropna函数函数参数DataFram
在pandas中,dropna函数分别存在于DataFrame、Series和Index中,下面我们以DataFrame.dropna函数为例进行介绍,Series和Index中的参数意义同DataFrame中大致相同。
pandas.DataFrame.dropna函数
函数参数
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
| 参数名称 | 参数取值 | 参数意义 |
|---|---|---|
| axis | 0 or ‘index’, 1 or ‘columns’ , default 0 | 确定是删除包含缺失值的行还是列 |
| how | ‘any’ or ‘all’, default ‘any’ | 表明是至少存在一个NAN值还是全为NAN值时执行删除操作 |
| thresh | int, 可选 | 指定存在多少个NAN值才进行删除操作 |
| subset | array, 可选 | 可选子集列表 |
| inplace | bool, default False | 如果为真,执行inplace操作,并返回None |
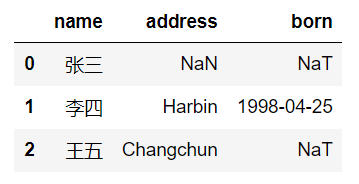
定义一个DataFrame,具有三个属性,分别是name、address和born。
import pandas as pd
import numpy as np
# 定义一个DataFrame
df = pd.DataFrame({"name": ['张三', '李四', '王五'],
"address": [np.nan, 'Harbin', 'Changchun'],
"born": [pd.NaT, pd.Timestamp("1998-04-25"),
pd.NaT]})
运行结果如下:
1.使用默认参数进行操作
df.dropna()
运行结果如下:
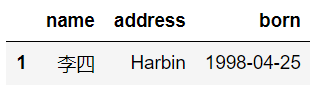
由运行结果看出,该函数把所有含有NAN值的行都执行了删除操作。
2.修改axis参数
df.dropna(axis=1) # 删除列
df.dropna(axis='columns') # 删除列
运行结果如下:
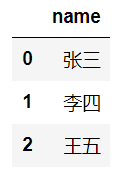
由结果可以看出,通过改变axis参数,可以控制删除操作执行的维度,0代表删除行,1代表删除列。
3.修改how参数
df.dropna(how='all')
运行结果如下:

有运行结果可以看出,数据并没有发生变化,这是因为在该数据中,并没有存在整行全部为NAN值的情况,所以不会进行删除操作。
4.修改thresh参数
df.dropna(thresh=2)
运行结果如下:

通过运行结果可以看出,当thresh=2时,说明将所有NAN值个数大于等于2的行或者列进行删除操作。
5.修改subset参数
df.dropna(subset=['name', 'address'])
运行结果如下:

通过结果截图可以看出,通过subset参数,可以选定一个数据的子集,例如代码中的[‘name’, ‘address’],在这个子集上进行删除操作,而不考虑born中的数据是否含有NAN值。
6.修改inplace参数
import pandas as pd
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),
pd.NaT]})
data = df.dropna(inplace=True)
print('----- the df is ------')
print(df)
print('----- the data is ------')
print(data)
运行结果如下:

由运行结果可以得出:
inplace=True,表示不创建新对象,直接在原始对象上进行修改,返回None;
inplace=False,表示创建新对象,返回创建对象的修改结果。
参考文献

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)