requests.get()返回数据乱码解决办法
requests.get()返回信息乱码问题的解决方法:1、网页未设置编码或无法找到编码;2、网页采用br压缩格式,没有解压导致乱码
说明:本文为个人解决问题过程记录,方法和理论不一定完全正确,如有错误,欢迎指出。
1 问题
刚开始接触硕士课题,看论文的时候用过一个Chrome插件“Kopernio”,可以直接免费下载论文PDF,大部分论文都能找到。Koperno的下载速度不仅比SCI-HUB快,而且已被科瑞唯安收购,属于正规军。因此在做PaperAsistent这个软件的时候首先就想到了用它来下载论文。
找到了PDF的链接后,正常用requests.get()来读数据,结果发现返回的数据是乱码,代码如下:
# 请求头
gheaders = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:27.0) \
Gecko/20100101 Firefox/27.0',
'Accept': 'text/html,application/xhtml+xml,application/xml; \
q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8, \
application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'Host': 'kopernio.com',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-kopernio-plugin-version': '0.12.26'
}
url = 'https://kopernio.com/viewer?doi=10.1109/icqr2mse.2012.6246426&route=7'
res = requests.get(url=url, headers=gheaders, verify=False) # GET请求
print(res.text)
返回结果如下图所示
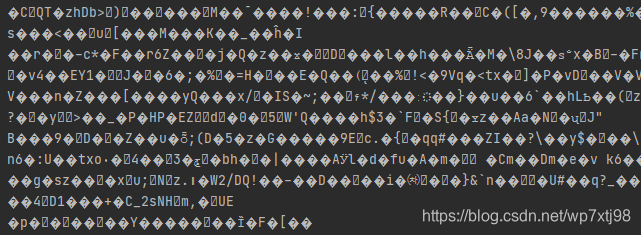
看到这个结果感觉是编码有问题,于是就百度了一下,找了一些方法进行了尝试。
2 尝试
百度[requests请求返回内容乱码]得到的解决方案主要是两个,参考这两篇文章 [ 1 , 2 ] ^{[1,2]} [1,2]。
2.1 自行设置编码格式
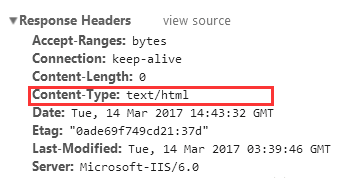
在浏览器按F12进入开发调试,找到请求链接对应的相关信息,在Response Headers中查看 'content-type’属性:
如果只指定了类型而没有指定编码(如下图),则页面默认是’ISO-8859-1’编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
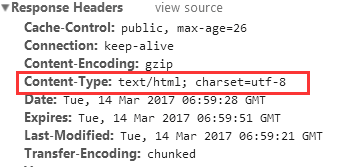
如下图,是指定编码为 UTF-8编码
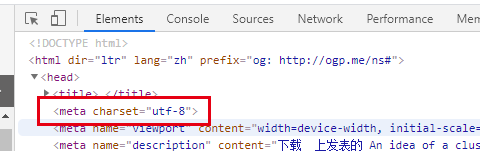
对于没有指定编码的情况,可以在网页源码中查找编码格式,如下图
然后在代码中指定它的编码格式即可,如下
res = requests.get(url, headers=header)
res.encoding = ‘UTF-8’
pritn(res.text)
我所请求的网址在Response Headers中设置了编码格式,所以这种解决方法无效,尝试下一种方法。
2.2 利用apparent_encoding
利用apparent_encoding来自动判断返回值的编码格式,然后用返回的编码格式进行设置
res = requests.get(url, headers = header)
res.encoding = res.apparent_encoding
pritn(res.text)
用了这种方法来试了一下,结果res.apparent_encoding的值是None…,这说明没识别出来返回信息的格式,这种办法对我遇到的情况来说没有用。
3 解决
又经过漫长的搜索,终于在知乎上看到了一个貌似合理,之前没有考虑的问题:压缩格式! [ 3 ] ^{[3]} [3]
造成乱码除了编码格式方面外,另外还有可能是因为压缩格式导致的。在请求头中,‘Accept-Encoding’是浏览器发给服务器,声明浏览器支持的编码类,一般有gzip,deflate,br 等等。很多网站都是以gzip的格式来输出页面,此时输出response.content和response.text时会自动解压,但是当以br格式压缩时,却不会自动解压
[
4
]
^{[4]}
[4]。
Brotli是一种由 Google开发的全新压缩算法,可以有效减小传输内容大小,加速分发效果。当客户端的请求携带请求头 Accept-Encoding: br 时,表示客户端希望获取对应资源时进行 Brotli 压缩。当服务端响应携带响应头 Content-Encoding: br 时,表示服务端响应的内容是 Brotli 压缩的资源。需要注意的是,只有在 HTTPS 的情况下,浏览器才会发送 br 这个 Accept-Encoding [ 5 ] ^{[5]} [5]。
看了一下网页里Response Headers中的content-encoding, 果然是br格式。又看了一眼代码里的accept-encoding,也包含了br格式,所以GET请求返回的页面是以br格式进行压缩的,无法自动解压,最后导致乱码。问题找到了就好解决了。
两种解决方法
[
6
]
^{[6]}
[6],一种是用pip install brotli安装解压库,再导入import brotli后解压缩:
response = requests.get(url, headers=headers)
data = brotli.decompress(response.content)
结果这里又出问题了,报错解压失败,如下图

参考资料[6]里最后说 python3.8和brotli=1.0.9运行时会提示错误,我用的是python3.9+brotli=1.0.9,估计是这个原因。
第二种解决方法简单粗暴,直接从请求头的Accept-Encoding中去除编码类型br:
Accept-Encoding = "gzip, deflate"
最后试了这种方法是有效的。
参考资料
[2]Python requests包get响应内容中文乱码解决方案
[3]如何解决用 Beautiful Soup 抓取网页却得到乱码的问题?

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 48
48 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)