多元函数牛顿法求函数极小值
多元函数牛顿法求极小值是对一元函数牛顿法的延申,关于一元函数牛顿法,可以看兔兔的《牛顿法(Newton's method)求函数极小值》一文。(一)算法原理与一元函数形式相似,但是又有很大的区别。首先,兔兔先介绍两个需要用到的基本概念:Hession矩阵和梯度。对于一个多元函数,有n个自变量,为n元函数,其Hession矩阵形式如下:并且自变量(向量x)为:函数的梯度定义为:例如对于二元函数,它的
多元函数牛顿法求极小值是对一元函数牛顿法的延申,关于一元函数牛顿法,可以看兔兔的《牛顿法(Newton's method)求函数极小值》一文。
(一)算法原理
与一元函数形式相似,但是又有很大的区别。首先,兔兔先介绍两个需要用到的基本概念:Hession矩阵和梯度。
对于一个多元函数,有n个自变量,为n元函数,其Hession矩阵形式如下:
并且自变量(向量x)为:
函数的梯度定义为:
例如对于二元函数,它的梯度就是
。其Hession矩阵为:
从本质上来说,多元函数梯度对应就是一元函数的导数,多元函数的Hession矩阵对应就是多元函数的二阶导数。而Hession矩阵的逆就对应着一元函数二阶导数的倒数,即:。
所以,与一元函数牛顿法相类比(这里兔兔就不给出证明方法了),最终的迭代公式为:
公式中x为自变量值,是列向量,为Hession矩阵的逆矩阵,
为梯度。
(二)算法实现
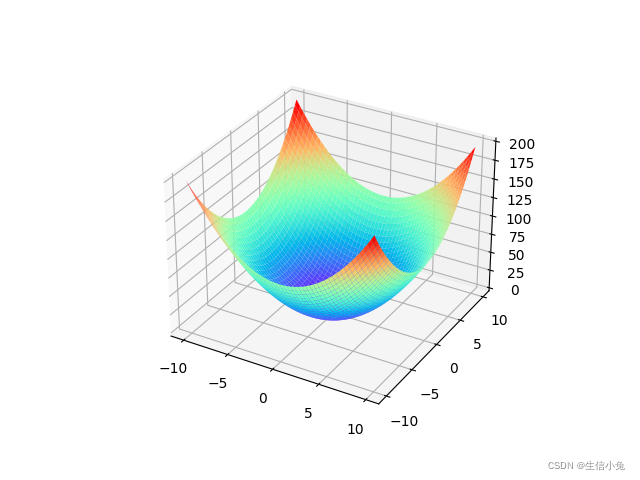
兔兔还是以函数在定义域x
[-10,10],y
[-10,10]为例,函数图像如下。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
ax=plt.axes(projection='3d')
def f(x):
return x[0][0]**2+x[0][1]**2
def gf(x):
'''函数梯度'''
return 2*x
def H(x):
'''Hession矩阵'''
h=np.array([[2,0],
[0,2]])
return h
x=np.arange(-10,10,0.1)
y=np.arange(-10,10,0.1)
x,y=np.meshgrid(x,y)
z=x**2+y**2
x0=np.mat([10,9]).T
xt=[x0]
for i in range(10):
x0=x0-np.dot(np.linalg.inv(H(x0)),gf(x0))
xt.append(x0)
xt_x=[]
xt_y=[]
xt_z=[]
for i in xt:
xt_x.append(i[0][0])
xt_y.append(i[1][0])
xt_z.append(i[0][0]**2+i[1][0]**2)
ax.plot_surface(x,y,z,cmap='rainbow')
ax.scatter(xt_x,xt_y,xt_z,color='red')
plt.show()
运行结果:
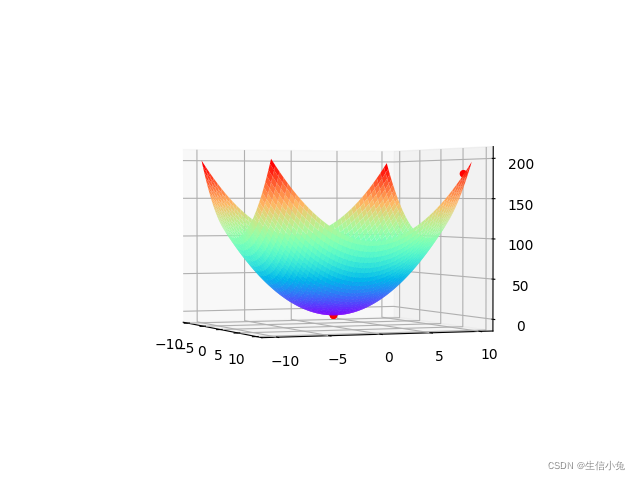
我们发现,基本迭代一次就达到了极小值点,收敛速度很快。
(三)总结
多元函数牛顿法作为一元函数牛顿法的延申,用于求解函数极小值,有着与一元函数牛顿法相同的优缺点。首先,它收敛很快,而且算法简便,但是对于一些函数也很难收敛全局最优或最小值,而且有时可能会收敛到极大值,并且严重依赖于初始值的选取。对于Hession矩阵在每次迭代中求取,有时计算量会很大,导致计算时间成本的增加。更主要的是,Hession矩阵有时可能行列式值为零,即不可逆,对应就是一元函数牛顿法中二阶导数出现0的情况,这种情况下程序报错,会运行不下去,所以就需要新的方法来解决该问题。对于Hession矩阵不可逆情况,需要用新的求解算法来替代Hession矩阵,所以就引申出DFP、BFGS、L-BFGS、SE1等系列算法。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容


所有评论(0)