Fisher线性判别分析原理解析及其Python程序实现两例
一、Fisher线性判别分析原理解析与算法描述Fisher:1890-1962, 英国数学家,生物学家,现代统计学奠基人之一,证明了孟德尔的遗传律符合达尔文的进化论。Fisher线性判别分析(Linear Discriminant Analysis)是一种应用较为广泛的线性分类方法,该方法于1936年由Fisher提出。Fisher线性判别分析又简称Fisher FDA。Fisher准则的基本原理
一、Fisher线性判别分析原理解析与算法描述
Fisher:1890-1962, 英国数学家,生物学家,现代统计学奠基人之一,证明了孟德尔的遗传律符合达尔文的进化论。
Fisher线性判别分析(Linear Discriminant Analysis, 简称Fisher LDA)是一种应用较为广泛的线性分类方法,该方法于1936年由Fisher提出。
Fisher准则的基本原理是,对于d维空间的样本,投影到一维坐标上,样本特征会混杂在一起,难以区分。如果找到一个投影方向,使得样本集合在该投影方向上最易区分,这就是Fisher准则的基本原理。Fisher准则可描述为用投影后数据的统计性质—均值和离散度的函数作为判别优劣的标准。
1.两类问题Fisher准则
已知两类问题N个d维样本x1,x2,…,xN;其中,类别为ωi(i=1,2),Ni是类别ωi的样本容量。设X空间为二维空间,现将X空间的各样本点投影到Y空间的一条直线上,样本特征维数由2维降为1维。若适当选择W的方向,能使二类分开。下面从数学角度寻找最好的投影方向,即寻找最好的变换向量W的问题。


以下是式(1)的Fisher准则函数J(W)的极值求解的具体过程:



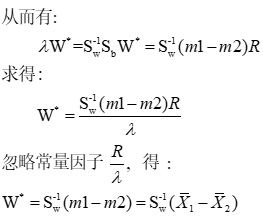
上式[即(2)式]就是n维X空间向一维Y空间的最好投影方向,它实际上是多维空间向一维空间的一种映射(W *就是使模式样本的投影在类间最分散、类内最集中的最优解)。

两类问题Fisher线性分类器计算步骤如下:

2.多类问题广义Fisher准则
基于两类问题的Fisher分类准则,我们可以很容易地将其扩展为多类问题的Fisher准则,又称广义Fisher准则(具体介绍此略)。
二、Fisher LDA的Python程序实现两例
Sklearn机器学习库中实现Fisher分类的方法是采用discriminant_analysis类的LinearDiscriminantAnalysis。
Fisher分类器Python关键语句如下:
from sklearn import discriminant_analysis
Fisher_clf = discriminant_analysis.LinearDiscriminantAnalysis()
1.蠓的二分类问题计算及其Python程序实现
蠓的二分类问题是源自美国大学生数学建模竞赛的一个题目,其大意是:生物学家W.L Grogan和W.W.Wirth试图将两种蠓Apf和Af进行鉴别,给出了9只Af和6只Apf蠓虫的触角长度和翅膀长度的数据,已知Af是宝贵的传粉益虫,Apf是某种疾病的载体,要求建立一种模型,正确区分两类蠓虫。
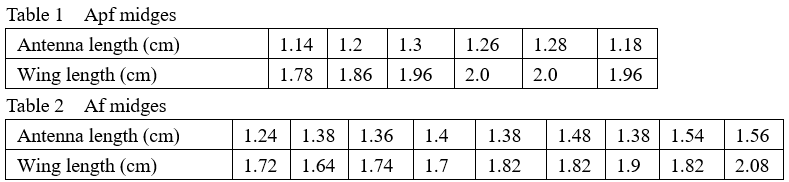
已知6只Apf蠓虫(Apf midges)和9只Af蠓虫(Af midges)的触长、翅长数据表见表1(Talbe 1)和表2(Table 2)所示。
蠓的二分类问题:
问题1: 试给出该问题的Fisher分类器;
问题2: 有三个待识别的模式样本,它们分别是(1.24,1.80)T ,(1.28,1.84)T,(1.40,2.04)T,试问这三个样本属于哪一种蠓。
按照前面给出的两类问题Fisher线性分类器计算步骤,蠓的二分类问题计算过程如下:









本例蠓虫二分类问题,采用Fisher LDA的Python程序运行界面截图如下:

下面是蠓虫二分类问题Fisher LDA的Python程序清单:
#Fisher线性判别分析-Fisher LDA
#蠓虫的Fisher二分类程序
#Filename: Fisher_LDA_Midge.ipynb
#Import Library
import numpy as np
from sklearn import discriminant_analysis
#Assumed you have X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
X=np.array([[1.14,1.78],[1.18,1.96],[1.20,1.86],[1.26,2.00],[1.30,2.00],[1.28,1.96],
[1.24,1.72],[1.36,1.74],[1.38,1.64],[1.38,1.82],[1.38,1.90],[1.40,1.70],[1.48,1.82],[1.54,2.08],[1.56,1.78]])
y=np.array([0,0,0,0,0,0,1,1,1,1,1,1,1,1,1])
#(X,y)作为训练集,前6个为Apf类 (类标签:0),后9个样本为Af类 (类标签:1)
#定义Fisher分类器对象fisher_clf
fisher_clf = discriminant_analysis.LinearDiscriminantAnalysis()
#调用该对象的训练方法
fisher_clf.fit(X,y)
x_test=np.array([[1.24,1.8],[1.28,1.84],[1.4,2.04]]) #待测试的三个样本
y_test=([0,0,0]) #待测试的三个样本的类标签
#(x_test,y_test)三个样本作为测试集
#调用该对象的测试方法
y_pred=fisher_clf.predict(x_test)
print('测试数据集的正确标签为:',y_test)
print('测试数据集的预测标签为:',y_pred)
from sklearn.metrics import accuracy_score
testing_acc=accuracy_score(y_test, y_pred)*100
print('Fisher线性分类器测试准确率: {:.2f}%'.format(testing_acc))
2.鸢尾花三分类问题及其Python程序实现
(1) 鸢尾花数据集介绍
Sklearn机器学习包集成了多种数据集,包括糖尿病数据集、鸢尾花数据集(Iris Dataset)等。鸢尾花有三个亚属,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
鸢尾花数据集的每条记录有4个特征变量(分别是萼片长度、萼片宽度、花瓣长度、花瓣宽度)和1个类别变量,每条记录为一个样本,共有150个样本。Iris是鸢尾植物,鸢尾植物分三类,类别变量取值有三个,它们分别是:0表示山鸢尾,1表示变色鸢尾,2表示维吉尼亚鸢尾。
Iris中有两个属性iris.data,iris.target。data是数据样本矩阵,矩阵各列代表萼片长度、萼片宽度、花瓣长度、花瓣宽度,矩阵各行代表某个被测量的鸢尾植物,共采集了150个样本记录。
from sklearn.datasets import load_iris #导入iris数据集
iris = load_iris() #加载iris数据集
print(iris.data)
输出结果:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
…
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
target是一个向量,存储了data中每条记录属于哪一类鸢尾植物,因此向量的长度是150。因为有3类鸢尾植物,因此target向量元素有3个不同取值(0-山鸢尾,1-变色鸢尾,2-维吉尼亚鸢尾),分别代表3种不同鸢尾植物的类标签。
print(iris.target) #输出真实标签
print(len(iris.target)) #共150个样本, 每个样本有4个特征
print(iris.data.shape)
输出结果:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150, 4)
从输出结果可以看出,类标签共分成三类,前面50个类标签为0,中间50个类标签为1,后面50个类标签为2。
(2) 鸢尾花三分类问题Python程序实现
本例鸢尾花三分类问题,采用Fisher LDA的Python程序运行界面截图如下:

下面是鸢尾花三分类问题Fisher LDA的Python程序清单:
#Fisher线性判别分析-Fisher LDA
#鸢尾花的Fisher三分类Python程序
#Filename: Fisher_LDA_Iris.ipynb
import numpy as np
from sklearn import discriminant_analysis
from sklearn import datasets
np.random.seed(1000)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices=np.random.permutation(len(iris_x))
#随机选取数据集中的120个样本(数据集的80%样本)作为训练集
iris_x_train=iris_x[indices[:-30]]
iris_y_train=iris_y[indices[:-30]]
#数据集剩下的30个样本(数据集的20%样本)作为测试集
iris_x_test=iris_x[indices[-30:]]
iris_y_test=iris_y[indices[-30:]]
#定义Fisher分类器对象fisher_clf
fisher_clf = discriminant_analysis.LinearDiscriminantAnalysis()
#调用该对象的训练方法
fisher_clf.fit(iris_x_train,iris_y_train)
#调用该对象的测试方法
iris_y_pred=fisher_clf.predict(iris_x_test)
print('测试数据集的正确标签为:',iris_y_test)
print('测试数据集的预测标签为:',iris_y_pred)
from sklearn.metrics import accuracy_score
testing_acc=accuracy_score(iris_y_test,iris_y_pred)*100
print('Fisher线性分类器测试准确率: {:.2f}%'.format(testing_acc))
(Email联系:yuanzywhu@163.com)
发布日期:2021年03月15日

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)