数据预处理方式:标准化/正态分布/zscore/scale/
一、数据预处理在实际数据分析工作中,我们会得到各种各样的数据,例如:存在缺失值,存在重复值,数据量纲单位不同等,这就要求我们在使用之前对数据进行预处理,一般为针对不同生物学特征和数据集数据的不同而选择不同的预处理流程,下文将结合我们遇到的问题,分享一些在机器学习中常用到的可能会与我们的数据预处理相关的方法。1. 标准化(Standardization)根据维基百科中所说,归一化(Normaliza
一、数据预处理
在实际数据分析工作中,我们会得到各种各样的数据,例如:存在缺失值,存在重复值,数据量纲单位不同等,这就要求我们在使用之前对数据进行预处理,一般为针对不同生物学特征和数据集数据的不同而选择不同的预处理流程,下文将结合我们遇到的问题,分享一些在机器学习中常用到的可能会与我们的数据预处理相关的方法。
1. 标准化(Standardization)
根据维基百科中所说,归一化(Normalization)和标准化(Standardization)都属于数据缩放的方法,用于数据预处理过程。 而正则化一般用于解决过拟合问题,用于模型训练过程。 实际上在很多资料中,Standardization和Normalization经常混为一起说明。
下面将对标准化的几种常见方式进行一一说明:
目录
1.1 zscore (scale) 标准化处理
1.1 zscore (scale) 标准化处理
scale 将特征数据的分布调整成标准正态分布,也叫高斯分布,也就是使得数据的均值为0,方差为1。标准化的原因在于如果有些特征的方差过大,则会主导目标函数从而使参数估计器无法正确地去学习其他特征。
标准化的过程为两步:去均值的中心化(均值变为0);方差的规模化(方差变为1)。
1.1.1 运行
在sklearn.preprocessing中提供了一个scale的方法,可以实现以上功能。
- from sklearn import preprocessing
- import numpy as np
- x = np.array([[1., -1., 2.],
- [2., 0., 0.],
- [0., 1., -1.]])
- x_scale = preprocessing.scale(x)
1.1.2 测试
对疑惑的问题进行下述测试:
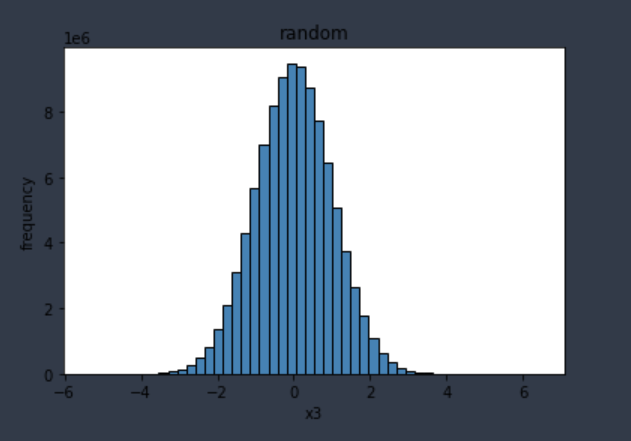
1. 不同类型数据经过scale转换后是否符合正太分布?
答:否,正态分布数据经过scale转换后变为标准正态分布,非正态分布数据不一定会转换为正太分布数据,
示例如下:
随机生成的非正态分布数据进行scale转换,使用KSTest 进行正太分布验证,然后看一下数据分布情况:
- import random
- from scipy import stats
- x1=np.random.rand(100000) ##随机生成
- x1_scale = preprocessing.scale(x1)
- print(jude_KS(x1))
- print(jude_KS(x1_scale))
1.2 最大-最小值缩放数据
在MinMaxScaler中是给定了一个明确的最大值与最小值。
它的计算公式如下:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std / (max - min) + min
以下这个例子是将数据规与[0,1]之间,每个特征中的最小值变成了0,最大值变成了1:
- min_max_scaler = preprocessing.MinMaxScaler()
- x_minmax = min_max_scaler.fit_transform(x)
- print(x_minmax)
- # 同样的,如果有新的测试数据进来,也想做同样的转换咋办呢?请看:
- x_test = np.array([[-3., -1., 4.]])
- x_test_minmax=min_max_scaler.transform(x_test)
1.3 MaxAbsScaler
MaxAbsScaler 原理与MinMaxScaler很像,只是数据会被规模化到[-1,1]之间,也就是说:在特征中,所有的数据都会除以最大值,这个方法对那些已经中心化均值为0或者稀疏的数据有意义。
1.4 用离群值缩放数据
如果数据包含许多离群值,那么使用数据的平均值和方差进行缩放可能不会很好地工作,异常值往往会对样本均值/方差产生负面影响。在这些情况下,可以使用罗布斯卡尔作为替代,它对数据的中心和范围使用更可靠的估计,中位数和四分位范围通常会给出更好的结果。
robust_scale、RobustScaler 为Sklearn中用离群值缩放数据的包, 实现规模化有异常值的数据(用离群值缩放数据)会根据中位数或者四分位数去中心化数据。
1.5 中心化核矩阵
有一个函数在定义的特征空间上计算点积核的核矩阵,可使用KernerlCenter变化核矩阵,使他包含由函数定义的被出去均值的特征空间上的内积。
换句话说:如果有一个核矩阵,它在一个由函数定义的特征空间中计算点积,KernerlCenterer可以转换核矩阵,使其包含特征空间中的内积,然后去除该空间中的均值,最终获得缩放后的数据。
 https://scikit-learn.org/stable/modules/preprocessing.html#standardization-or-mean-removal-and-variance-scaling
https://scikit-learn.org/stable/modules/preprocessing.html#standardization-or-mean-removal-and-variance-scaling
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)