Python文本处理
本文主要介绍python文本处理算法代码主要应用和一些基本原理一、常用库📖1.Jiebajieba是支持中文分词的第三方库。2.gensimgensim是一个通过衡量词组(或更高级结构,如整句或文档)模式来挖掘文档语义结构的工具三大核心概念文集(语料)–>向量–>模型2.1.构建词典(文集)2.2.语料向量化评价指标有困惑度(perplexity)和主题一致性(coherence),困惑度越低或
前言
本文主要介绍python文本处理算法代码主要应用和一些基本原理
一、常用库📖
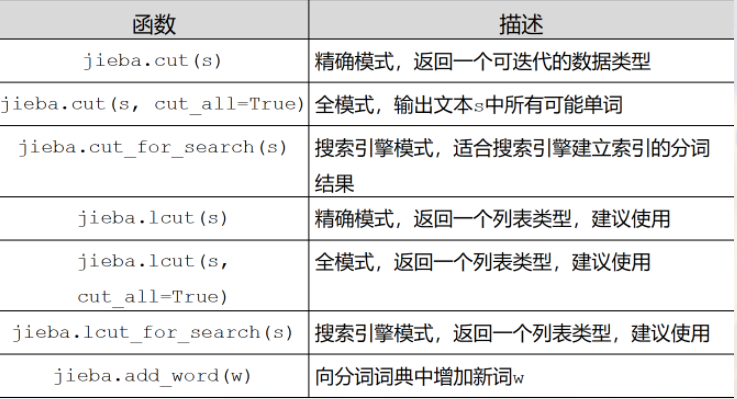
1. Jieba
jieba是支持中文分词的第三方库。
jieba库分词的三种模式:
- 精准模式:把文本精准地分开,不存在冗余
- 全模式:把文中所有可能的词语都扫描出来,存在冗余
- 搜索引擎模式:在精准模式的基础上,再次对长词进行切分
2. gensim
gensim 是一个通过衡量词组(或更高级结构,如整句或文档)模式来挖掘文档语义结构的工具
三大核心概念:文集(语料)–> 向量 –> 模型
2.1. 构建词典(文集)
from gensim import corpora
import jieba
documents = ['工业互联网平台的核心技术是什么',
'工业现场生产过程优化场景有哪些']
def word_cut(doc):
seg = [jieba.lcut(w) for w in doc]
return seg
texts= word_cut(documents)
'''为语料库中出现的所有单词分配了一个唯一的整数id'''
dictionary = corpora.Dictionary(texts)
dictionary.token2id
# => {'互联网': 0,
# '什么': 1,
# '优化': 7,
# '哪些': 8,
# '场景': 9,
# '工业': 2,
# '平台': 3,
# '是': 4,
# '有': 10,
# '核心技术': 5,
# '现场': 11,
# '生产': 12,
# '的': 6,
# '过程': 13}
2.2. 语料向量化
'''该函数doc2bow()只计算每个不同单词的出现次数,将单词转换为整数单词id,并将结果作为稀疏向量返回'''
bow_corpus = [dictionary.doc2bow(text) for text in texts]
# => [[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)],
# [(2, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1)]]2.3. 构建LDA模型
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
#分为10个主题
ldamodel = LdaModel(corpus, num_topics=10, id2word = dictionary, passes=30,random_state = 1)
ldamodel.print_topics(num_topics=num_topics, num_words=15) #每个主题输出15个单词2.4. 评价LDA主题模型 (确认最优主题数)
评价指标有困惑度(perplexity)和主题一致性(coherence),困惑度越低或者一致性越高说明模型越好。一致性指标应用更好。
#计算困惑度
def perplexity(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30)
print(ldamodel.print_topics(num_topics=num_topics, num_words=15))
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
#计算coherence
def coherence(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word = dictionary, passes=30,random_state = 1)
print(ldamodel.print_topics(num_topics=num_topics, num_words=10))
ldacm = CoherenceModel(model=ldamodel, texts=data_set, dictionary=dictionary, coherence='c_v')
print(ldacm.get_coherence())
return ldacm.get_coherence()可视化选择最优主题数:
x = range(1,15)
# z = [perplexity(i) for i in x] #如果想用困惑度就选这个
y = [coherence(i) for i in x]
plt.plot(x, y)
plt.xlabel('主题数目')
plt.ylabel('coherence大小')
plt.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
plt.title('主题-coherence变化情况')
plt.show()2.5. LDA模型结果进行可视化
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
data = pyLDAvis.gensim.prepare(lda, corpus, dictionary)
pyLDAvis.save_html(data, 'E:/data/3topic.html')
3. ahocorasick (AC自动机)
ac自动机算法可以快速找到字符串里的字符段
ac自动机典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
!pip install pyahocorasick #安装
import ahocorasick
A = ahocorasick.Automaton()
''' 向trie树中添加单词 '''
for index,word in enumerate("he her hers she".split()):
A.add_word(word, (index, word))
#检查trie树
A.get("he")
# (0,'he')
A.get("cat","<not exists>")
# '<not exists>'
A.get("dog")
# KeyError
''' 将trie树转化为Aho-Corasick自动机 '''
A.make_automaton()
''' 找到所有匹配字符串, 没有匹配到则不执行 '''
for item in A.iter("_hershe_"):
print item
#(2,(0,'he'))
#(3,(1,'her'))
#(4, (2, 'hers'))
#(6, (3, 'she'))
#(6, (0, 'he'))4. SnowNLP
Snownlp是中文文本处理库,可以用于情感分析(朴素贝叶斯实现),文本分类
from snownlp import SnowNLP
s = SnowNLP(u'SnowNLP类似NLTK,是针对中文处理的一个Python工具库。')
sentiments = s.sentiments
print(sentiments) #情感分数0~15. NLTK
Natural Language Toolkit

6. TextBlob

二、算法原理
1. LDA主题模型
LDA模型认为主题可以由一个词汇分布来表示,而文章可以由主题分布来表示
设有20个主题,LDA主题模型的目标是为每一篇文章找到一个20维的向量,向量中的20个值代表着这篇文章属于某一个主题的概率大小。是一个类似于聚类的操作。
在LDA主题模型中,文章的生成有三个要素【词语,主题,文章】,词语和主题是多对多的关系,每个词语都可能代表着多个主题,每个主题下也有多个代表的词语;主题和文章也是多对多的关系,每个主题都对应着多篇文章,每篇文章也可能有多个主题。
2. AC自动机
应用:有大量的语料,统计一系列词出现的位置和出现的次数。
AC自动机是KMP和trie的结合体。KMP算法适用于单模式串的匹配,而AC自动机适合多模式串的匹配。例如:在一篇文章中我们找一句话可以用KMP,找多句话适用于AC自动机。
3. TF-IDF
词频(Term frequency)就是一个单词在一个句子出现的次数与这个句子单词个数的比例。
TF = (Number of times term T appears in the particular row) / (number of terms in that row)
反转文档频率(Inverse Document Frequency),简称为IDF,其原理可以简单理解为如果一个单词在所有文档都会出现,那么可能这个单词对我们没有那么重要。
一个单词的IDF就是所有行数与出现该单词的行的个数的比例,最后对数。
IDF = log(N/n)
TF-IDF=TF*IDF
tf1 = (train['tweet'][1:2]).apply(lambda x: pd.value_counts(x.split(" "))).sum(axis = 0).reset_index()
tf1.columns = ['words','tf']
for i,word in enumerate(tf1['words']):
tf1.loc[i, 'idf'] =np.log(train.shape[0]/(len(train[train['tweet'].str.contains(word)])))
tf1['tfidf']=tf1['tf']*tf1['idf']4. LSI主题模型
LSI是最早出现的主题模型了,它的算法原理很简单,一次奇异值分解就可以得到主题模型,同时解决词义的问题,非常漂亮。但是LSI有很多不足,导致它在当前实际的主题模型中已基本不再使用。
主要的问题有:
- SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解是非常难的。
- 主题值的选取对结果的影响非常大,很难选择合适的k值。
- LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。
对于问题1),主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。对于问题2),这是老大难了,大部分主题模型的主题的个数选取一般都是凭经验的,较新的层次狄利克雷过程(HDP)可以自动选择主题个数。对于问题3),牛人们整出了pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。
回到LSI本身,对于一些规模较小的问题,如果想快速粗粒度的找出一些主题分布的关系,则LSI是比较好的一个选择,其他时候,如果你需要使用主题模型,推荐使用LDA和HDP。
三、文本处理编码问题
1. chardet 库
chardet可以自动检查字符串编码类型
import chardet
str1 = 'hello'.encode('utf-8') # encode 接受str,返回一个bytes
print(type(str1),str1)
result = chardet.detect(str1) # chardet 接受bytes类型,返回一个字典,返回内容为页面编码类型.
print(type(result),result)
codetype = result.get('encoding')
print(codetype)
#>> <class 'bytes'> b'hello'
#>> <class 'dict'> {'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
#>> ascii
2. emoji 库
编解码emoji表情
import emoji
a = emoji.emojize(':grinning_face:', use_aliases=True)
a = emoji.demojize('????', use_aliases=True)注意emoji除了定义了表情字符,还定义了一个控制前一个表情字符如何展示的特殊字叫'Variation Selector-16' 变体选择符。 使用 16 号变体选择符(U+FE0F)能把某些文字(如数字、骷髅符号、雌/雄符号 等)变成绘文字。比如unicode编码'U+2708',默认是'✈',而如果在这个字符后面紧跟着'U+FE0F'这个控制字符,则展示效果会变成✈️。 单个ufe0f没有内容,但是占1长度。
推荐阅读
文本主题模型之潜在语义索引(LSI) - 刘建平Pinard - 博客园
References

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)