多头自注意力机制Pytorch实现
注意力机制广泛存在于现在的深度学习网络结构中,使用得到能够提升模型的学习效果。本文讲使用Pytorch实现多头自注意力模块。一个典型的自注意力模块由Q、K、V三个矩阵的运算组成,Q、K、V三个矩阵都由原特征矩阵变换而来,所以本质上来说是对自身的运算。而多头注意力机制则是单头注意力机制的进化版,把每次attention运算分组(头)进行,能够从多个维度提炼特征信息。具体原理可以参看相关的科普文章,下
·
注意力机制广泛存在于现在的深度学习网络结构中,使用得到能够提升模型的学习效果。本文讲使用Pytorch实现多头自注意力模块。
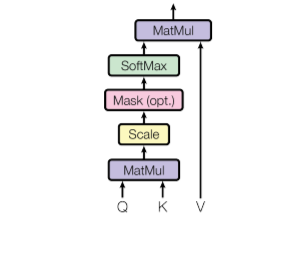
一个典型的自注意力模块由Q、K、V三个矩阵的运算组成,Q、K、V三个矩阵都由原特征矩阵变换而来,所以本质上来说是对自身的运算。

而多头注意力机制则是单头注意力机制的进化版,把每次attention运算分组(头)进行,能够从多个维度提炼特征信息。具体原理可以参看相关的科普文章,下面是Pytorch实现。
import torch.nn as nn
class MHSA(nn.Module):
def __init__(self, num_heads, dim):
super().__init__()
# Q, K, V 转换矩阵,这里假设输入和输出的特征维度相同
self.q = nn.Linear(dim, dim)
self.k = nn.Linear(dim, dim)
self.v = nn.Linear(dim, dim)
self.num_heads = num_heads
def forward(self, x):
B, N, C = x.shape
# 生成转换矩阵并分多头
q = self.q(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
k = self.k(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
v = self.k(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
# 点积得到attention score
attn = q @ k.transpose(2, 3) * (x.shape[-1] ** -0.5)
attn = attn.softmax(dim=-1)
# 乘上attention score并输出
v = (attn @ v).permute(0, 2, 1, 3).reshape(B, N, C)
return v

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)