浅谈Python爬虫(十)【企查查爬虫无需登录】
想起来有次面试的时候,面试官让我爬企查查,当时一脸懵。。。今天正好有时间,索性看一下。进入企查查,不登录,可以搜索到结果,但是只能看到前5个。。。凑合着也行吧直接怼一下试试。。。import requestsheaders = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)
想起来有次面试的时候,面试官让我爬企查查,当时一脸懵。。。今天正好有时间,索性看一下。
进入企查查,不登录,可以搜索到结果,但是只能看到前5个。。。凑合着也行吧
直接怼一下试试。。。
import requests
headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'}
url = 'https://www.qcc.com/web/search?key=腾讯'
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
print(response.text)
print(response)
返回值是200,但是内容是报错。

在浏览器新开一个无痕页面(Chrome Ctrl+Shift+N),然后把链接复制进去。看一下具体请求。
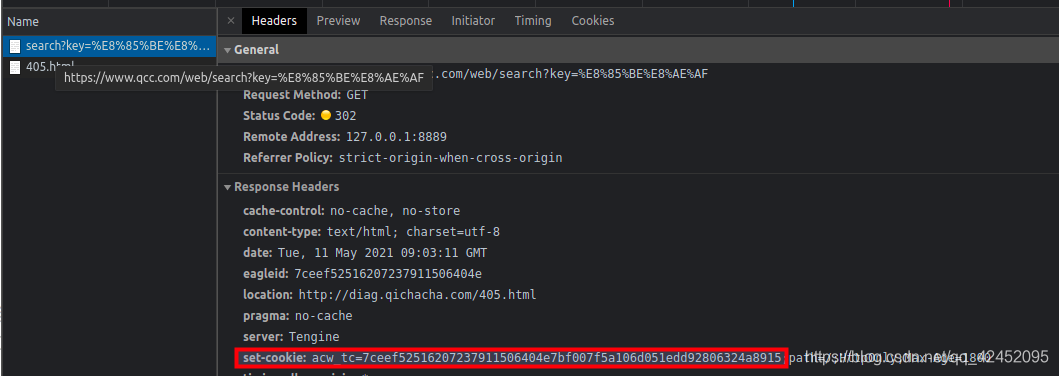
发现有一个set-cookie。把这个参数当成cookie放进请求头再请求一下试试看。
import requests
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'cookie': 'acw_tc=7ceef52516207237911506404e7bf007f5a106d051edd92806324a8915'
}
url = 'https://www.qcc.com/web/search?key=腾讯'
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
print(response.text)
print(response)
果然可以了。
接下来就是需要找这个值的存放位置了。
找了一下第一次报错返回的源码,发现没有。。。
这时候,突然发现第一次返回的源码是405.html这个文件的内容。那么。。。。这个小可爱重定向了???
换代码试一下
import requests
headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'}
url = 'https://www.qcc.com/web/search?key=腾讯'
response = requests.get(url, headers=headers, allow_redirects=False)
response.encoding = response.apparent_encoding
print(response.text)
然后看一下这个返回值,果然有一个类似cookie 的

虽然不是完全一样,但是这个好像是cookie前面的一部分。
emmm,不管了直接复制进去试一下
import requests
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'cookie': 'acw_tc=7ceef51716207240819688967e'
}
url = 'https://www.qcc.com/web/search?key=腾讯'
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
print(response.text)
发现也是可以的啊哈哈哈
所以具体流程就是,先请求一次任意搜索页面,获取到cookie(注意要加上禁止重定向的参数 allow_redirects=False)。然后就可以快乐的抓取了。
剩下就是解析内容页,没有啥技术难度了。
不多BB,直接上代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# @File : qcc.py
# @Author : Monkey
# @DATE : 2021/5/11 下午5:13
import requests
import re
from lxml import etree
class QCC(object):
"""企查查爬虫"""
def __init__(self):
self._headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
}
def get_cookie(self):
"""发起一次测试请求,获取到搜索的cookie"""
url = 'https://www.qcc.com/web/search?key=测试'
response = requests.get(url, headers=self._headers, allow_redirects=False)
response.encoding = 'utf8'
result = re.findall(r'div>您的请求ID是: <strong>\n(.*?)</strong></div>', response.text)
if result:
return result[0]
def search(self, search_keyword):
"""搜索"""
url = 'https://www.qcc.com/web/search?key={}'.format(search_keyword)
headers = self._headers
headers['cookie'] = 'acw_tc={}'.format(self.get_cookie())
response = requests.get(url, headers=headers)
response.encoding = 'utf8'
html = etree.HTML(response.text)
com_url = html.xpath('//a[@class="title"]/@href')
print('搜索到{}条结果。即将开始获取详细信息...'.format(len(com_url)))
for url in com_url:
self.get_com_info(url)
def get_com_info(self, url):
"""获取公司的详细信息"""
response = requests.get(url, headers=self._headers)
html = etree.HTML(response.text)
info_elements = html.xpath('//table[@class="ntable"]/tr')
item = {'url': url}
flag = True
for element in info_elements:
if not flag:
break
for index in range(0, len(element.xpath('./td')), 2):
try:
key = element.xpath('./td[{}]/text()'.format(index+1))[0].strip()
if key == '公司介绍:' or key == '经营范围':
flag = False
if key == '法定代表人':
item[key] = element.xpath('./td[{}]//h2/text()'.format(index+2))[0].strip()
else:
item[key] = element.xpath('./td[{}]//text()'.format(index+2))[0].strip()
except:
pass
print(item)
def run(self):
"""启动函数"""
self.search(search_keyword='腾讯')
if __name__ == '__main__':
t = QCC()
t.run()
有问题可以留言、私信
看到就回

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)