利用python制作词云图,分词,提取关键词
利用python制作词云图保姆及教程前言一、环境配置1.要有python的运行环境2.需要导入jieba ,wordcloud等模块pip install jiebapip install wordcloud注意:有时候导入模块可能会出错,我们可以换一个镜像网站进行安装pip install 安装包名字-i http://pypi.doubanio.com/simple/ --trusted-ho
·
利用python制作词云图保姆及教程
前言
一、环境配置
1.要有python的运行环境
2.需要导入jieba ,wordcloud等模块
pip install jieba
pip install wordcloud
注意:有时候导入模块可能会出错,我们可以换一个镜像网站进行安装
pip install 安装包名字 -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
3.准备一个用于分析的文章(此处使用(边城.txt))
4.准备一个停用词表(如哈工大的停用词表,或百度的停用词表等,通常我们不提倡自己建一个停用词表)
5.准备一张背景图片模板
二、具体步骤
1.导入模块
from wordcloud import WordCloud,ImageColorGenerator
import jieba
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
2.读取分析文档
with open(r"F:\词云图\边城.txt","r",encoding="utf-8") as f:
file = f.read()
print(file)

3.对文本进行分词
data_cut = jieba.lcut(file,cut_all=False) #使用精确模式进行分词
print(data_cut)

4.创建一个stop_word列表,读取停用词文档,将停用词添加到列表中
stop_word = []
with open(r"F:\词云图\stopwords.txt","r",encoding="utf-8") as f:
for line in f:
if len(line)>0:
stop_word.append(line.strip()) #进行追加时将字符串前后的空格去掉
print(stop_word)

5.新建一个列表,用于存放将分析文档库与停用词库对比后去除停用词的字符串
data_result = []
for i in data_cut:
if i not in stop_word:
data_result.append(i)
print(data_result)

6.将去掉停用词后的列表使用空格将其中的元素连接起来,并将其中的\n替换为空格
text = " ".join(data_result).replace("\n"," ")
print(text)

7.基于TextRank提取关键词
text_new = " ".join(jieba.analyse.textrank(text,topK=100,withWeight=False))
print(text_new)

8.导入模板图片
background = Image.open(r"F:\词云图\biancheng.png")
images = np.array(background)
9.设置WordCloud的相关参数,并生成词云
wc = WordCloud(font_path=r"F:\词云图\SIMLI.TTF",background_color="white",mask=images,max_words=4000,contour_width=3,contour_color="black")
wc.generate(text_new)
10.设置显示的字体
#改变字体颜色,构造ImageColorGenerator对象
img_colors=ImageColorGenerator(images)
#字体颜色为背景图片的颜色
wc.recolor(color_func=img_colors)
11.显示词云图,并保存
#显示词图云
plt.imshow(wc)
#取消坐标
plt.axis("off")
plt.show()
wc.to_file(r"F:\词云图\biancheng.png")
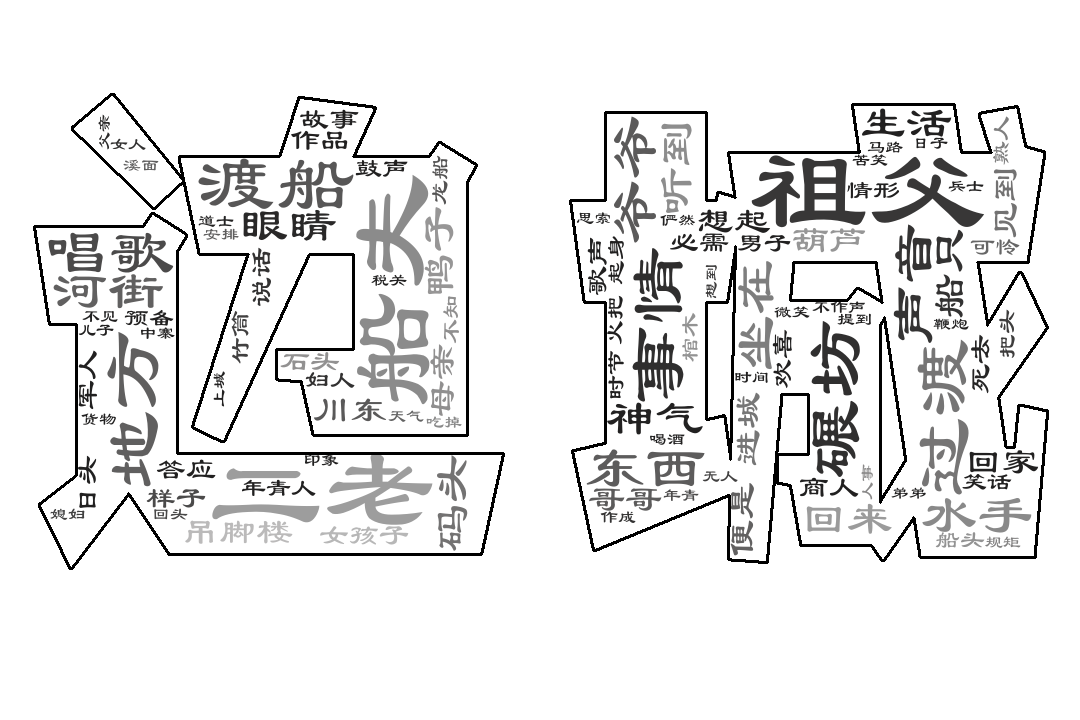
经过以上操作后我们可以得到一张biancheng.png词云图如下:

下面分享制作的其他词云图,欢迎大家交流学习!



为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)